PDDS
SQL优化
Data Model
数据模型提供了指定特定数据结构、约束以及操作数据的方法。
- 主要类型:
- 关系模型 (Relational Model):由 E.F. Codd 于1970年提出。数据以二维表(关系)的形式组织,每行有统一的结构。优点包括灵活性、低冗余和高数据完整性、内置安全性以及易于使用(标准查询接口为SQL)。
- 层次模型 (Hierarchical Model):树结构,最古老,IBM于1968年开发。
- 网络模型 (Network Model):图结构,CODASYL于1970年提出。
- 语义模型 (Semantic Model) 和 面向对象模型 (Object-oriented Model)。
SQL Language
SQL(结构化查询语言)是一种声明式语言,用于管理关系数据库中的数据。
历史:
- 1970年:E.F. Codd 提出关系数据库概念。
- 1972年:IBM 为 System R 原型创建了 SEQUEL(结构化英语查询语言)。
- 1979年:Oracle v2 成为首个商业化的基于SQL的关系数据库管理系统(RDBMS)。
- 1986年:ANSI SQL 标准发布。
- 后续不断更新,如 SQL:1999 (正则表达式、触发器)、SQL:2003 (XML、窗口函数)、SQL:2016 (JSON)等。
子语言:
- 数据定义语言 (DDL):用于创建、修改和删除数据库结构(如
CREATE,ALTER,DROP)。 - 数据操纵语言 (DML):用于查询和修改数据(如
SELECT,INSERT,UPDATE,DELETE)。 - 数据控制语言 (DCL):用于控制数据库访问权限(如
GRANT)。
- 数据定义语言 (DDL):用于创建、修改和删除数据库结构(如
Logical & Physical Plan
查询优化器的工作是将一个逻辑代数表达式映射到最优的等价物理代数表达式。
- 逻辑计划 (Logical Plan):描述“做什么”,例如进行投影(Project)、连接(Join)、扫描(Scan)等操作,但不涉及具体执行方式。
- 物理计划 (Physical Plan):描述“怎么做”,指定具体的执行策略,如使用哪种连接算法(如 Sort-Merge Join)、访问路径(如索引扫描或全表扫描)等。
逻辑优化是基于规则的
- 规则基础优化 (Rule-Based Optimization, RBO):通过模式匹配规则将逻辑计划转换为等价的、更高效的逻辑计划。目标是增加枚举出最优计划的可能性。
- 常用规则示例:
- 谓词下推 (Predicate Pushdown):将过滤条件尽可能早地应用到数据源上,减少后续处理的数据量。
- 投影下推 (Projection Pushdown):尽早消除不必要的列,特别是在流水线中断点之前,以减少物化成本。
- 用连接替换笛卡尔积 (Replace Cartesian Products with Joins):利用连接谓词将笛卡尔积转换为内连接。
为什么逻辑层面不需要cost model而物理层面需要?
- 逻辑层面:优化是基于启发式规则的,这些规则被经验证明通常能产生更好的计划(例如,先做选择再做连接总是比先连接再选择好)。因此,它不需要比较不同计划的成本,而是直接应用规则来“指导”转换到一个更优的方向。
- 物理层面:不同的物理实现方式(如不同的连接算法或访问路径)有不同的性能特征,其优劣高度依赖于数据分布、硬件环境等因素。因此,必须使用成本模型 (Cost Model) 来估算每个物理计划的执行成本(如CPU、I/O),然后从多个等价的物理计划中选择成本最低的那个。
物理优化有哪些Cost Model?
物理优化中的成本模型主要包括以下几种组件:
- 物理成本 (Physical Costs):预测CPU周期、I/O次数、缓存未命中、内存消耗和网络消息等。这严重依赖于硬件。
- 逻辑成本 (Logical Costs):估计每个算子输出的结果大小(即基数估计)。这独立于算子的具体算法,是成本计算的基础。
- 算法成本 (Algorithmic Costs):算子算法实现的复杂度。
PostgreSQL 成本模型示例:
- 结合了CPU和I/O成本,并通过一些“魔法常数”因子进行加权。
- 默认设置假设是磁盘驻留数据库且内存不大:
- 在内存中处理一个元组比从磁盘读取一个元组快400倍。
- 顺序I/O比随机I/O快4倍。
统计信息 (Statistics):为了进行准确的成本估算,数据库管理系统会存储关于表、属性和索引的内部统计信息,如直方图、草图(如 Count-Min Sketch 用于近似频率计数,HyperLogLog 用于近似去重计数)和采样数据。
Consistency
背景
- 早期单机系统无数据共享,不需讨论一致性。
- 随着多处理器(共享内存/Cache)、**分布式系统(数据复制)**的出现,同一份数据存在多个副本或被并发访问,才需要”Consistency”来保证程序逻辑正确。
分类
PPT将Consistency分为两大类:
(1) State Consistency(状态一致性)
对系统状态的约束,要求数据在任何时刻满足某些不变式(Invariant)。
- Invariant(不变式):如”若两个CPU缓存了同一变量A,则缓存值必须相等”(Cache Coherence 的本质)。
- Error Bounds:允许数值在一定误差范围内,如 Google Spanner 的 TrueTime API。
- Eventual Invariants:最终满足不变式(如最终一致性 Eventually Consistent)。
- 数据库 ACID 中的 C 主要指 State Consistency —— 事务使数据库从一个合法状态转移到另一个合法状态。
(2) Operation Consistency(操作/行为一致性)
对操作返回结果的约束,客户端不太关心内部状态,只关心读操作得到的结果是否合理。
- Sequential Equivalence(串行等价):并发执行的结果等价于某个串行的正确执行结果。
- Linearizability(线性一致性):存在合法串行序,且若 op1 完成先于 op2 开始,则串行序中 op1 须在 op2 前(最强,含实时序)。
- Sequential Consistency(顺序一致性):存在合法串行序,但只保证同一客户端的操作顺序,不保证不同客户端操作的实时序。
- Read-write centric(读写为中心):
- Read-my-writes:客户端必能读到自己的写。
- Bounded Staleness:写操作在一定时间后被读可见。
- Operational Eventual Consistency:最终所有读看到最新写。
- 数据库 Isolation(隔离性)属于 Operation Consistency 中的 Transaction-level Serializability / Strict Serializability 等。
不同领域的一致性侧重
| 领域 | 侧重 |
|---|---|
| Computer Architecture | Operation Consistency — Load/Store 的内存一致性(Memory Consistency) 与 Cache Coherence |
| Distributed System | State 或 Operation Consistency,受网络分区/延迟影响常做权衡(CAP) |
| Database System | ACID中 C=State Consistency,A/I=Operation Consistency,D=Durability |
Consistency 与 ACID 的关系
- Atomicity: Operation Consistency
- Consistency: State Consistency
- Isolation: Operation Consistency
- Durability: Not related to consistency
即:
- C (Consistency):指数据库约束(主外键、唯一、业务规则等)在事务前后均成立,是应用+DBMS共同保证的状态不变式。
- A (原子性) & I (隔离性):是 DBMS 通过锁/OCC 等机制提供的 Operation Consistency,是让 C 得以成立的前提(若脏写或脏读可能破坏状态不变式)。
- D (持久性):与一致性语义无关,是故障恢复保障。
保证 ACID 的并发控制方法及其优缺点
PPT从简单到复杂介绍了四种演进方案:
1. Single Global Lock(全局一把锁)
1 | |
- ✅ 绝对串行化(Serializable),实现极简,无死锁、无脏写。
- ❌ 吞吐量极差,整个系统只允许一个事务运行,完全无并发,无法用于多核/高吞吐场景。
2. Per-record Lock(记录级互斥锁)
- 每个记录一把锁,读写都用同一把排他锁。
- ✅ 比全局锁并发度高,对同一记录冲突才串行。
- ❌ 读-读 也互斥,降低读并发;仍可能出现非串行化调度(需更精细的读写锁)。
3. Per-record Read-Write Lock(读共享/写互斥)
- 读加 S(Shared) 锁,写加 X(Exclusive) 锁,读写兼容,写写/读写不兼容。
- ✅ 提高读并发(多个事务可同时读同一记录)。
- ❌ 仅凭读写锁不能保证 Serializability(可能出现 write-read 交叉导致非串行结果),仍需配合协议。
4. Two-Phase Locking(2PL,两阶段锁)
- Growing Phase:只获取锁不释放。
- Shrinking Phase:只释放锁不再获取。
- ✅ 2PL 保证 Conflict Serializability(冲突可串行化),是传统关系型数据库主流。
- ❌ 缺陷:
- Cascading Abort(级联回滚):若 T1 提交前释放锁且 T2 读了 T1 未提交数据,这在主流数据库时不被允许的,因此 T1 回滚会导致 T2 也必须回滚。解决方法是 commit 后才进行释放。
- Deadlock(死锁):需用 Wait-for Graph(检测环)/ Wait-die(超时kill)/ Wound-wait 检测或预防,带来额外开销。
5. Strict Two-Phase Locking(严格2PL / S2PL)
- 所有锁(读/写)直到事务 Commit/Rollback 时才统一释放(无 Shrinking Phase 直到结束)。
- ✅ 避免 Cascading Abort,仍是多数传统 RDBMS(MySQL InnoDB 等)的默认隔离级别基础。
- ❌ 锁持有时间长 → 锁竞争加剧、并发度下降;仍存在死锁问题;不适合高冲突分布式场景。
6. Optimistic Concurrency Control(OCC,乐观并发控制)
- 三阶段:Read Phase(本地拷贝读写,不拿锁)→ Validation Phase(提交时检查是否与已提交事务冲突,读集版本是否变化)→ Write Phase(校验通过才写入)。
- ✅ 无锁读,读开销极低,在高并发低冲突(如内存数据库 Silo)时性能极好;避免死锁。
- ❌
- 高冲突时大量事务在 Validation 阶段失败需重启(ABORT),浪费已做的工作。
- 需维护读集/写集和版本号。
- 不适合长事务或高争用场景(PPT中 IC3 部分指出 OCC/2PL 在高 contention 下吞吐量骤降)。
汇总对比
| 方法 | 串行化保证 | 并发度 | 主要缺点 |
|---|---|---|---|
| 全局锁 | ✓ | 极低 | 无并行 |
| 记录锁(互斥) | ✗ | 低 | 读-读互斥 |
| 读写锁 | ✗ | 中 | 不足以保证可串行化 |
| 2PL | ✓(冲突可串行化) | 中 | 级联回滚+死锁 |
| Strict 2PL | ✓ | 中-低 | 锁持有时长→竞争大,死锁 |
| OCC | ✓(校验后提交) | 高(低冲突时) | 高冲突时频繁 ABORT 重试 |
Isolation Level
SQL Isolation Levels
SQL 标准定义了四个隔离级别,从弱到强依次为:
| 隔离级别 | 允许的异常 |
|---|---|
| READ UNCOMMITTED | Dirty Read、Non-Repeatable Read、Phantom 都允许 |
| READ COMMITTED | 不允许 Dirty Read,但允许 Non-Repeatable Read 和 Phantom |
| REPEATABLE READ | 不允许 Dirty Read 和 Non-Repeatable Read,但允许 Phantom |
| SERIALIZABLE | Dirty Read、Non-Repeatable Read、Phantom 都不允许,所有调度必须是可串行化的 |
各隔离级别的 Anomaly 说明
1. Dirty Read(脏读)
- 一个事务读取了另一个未提交事务写入的数据。
- 如果那个未提交事务后来回滚,则读取到的数据是无效的。
2. Non-Repeatable Read(不可重复读)
- 同一个事务内,两次执行相同的 SELECT 语句,返回的行集合相同,但属性值可能不同。
- 原因是两次读取之间,另一个并发事务修改并提交了这些行。
3. Phantom(幻读)
- 同一个事务内,两次执行相同的 SELECT 语句,第二次返回了第一次没有的行(新增的行)。
- 原因是另一个并发事务插入了满足查询条件的新行并提交。
4. Lost Update(丢失更新)
- 两个事务先后读取同一数据,然后各自基于读取的值进行修改并提交,后提交的事务覆盖了先提交事务的修改。
- 在 READ COMMITTED 级别下可能发生。
5. Dirty Write(脏写)
- 一个事务覆盖了另一个未提交事务写入的数据。
- 在所有隔离级别下都被防止(写锁都是长期持有的)。
各隔离级别的锁实现方式
PPT 中给出了基于锁的实现方案(Locking Implementation):
1. READ UNCOMMITTED
- 读锁:不加任何读锁。
- 写锁:长期持有谓词写锁(防止脏写)。
- 后果:事务可以读取已被写锁定的项,导致脏读。
2. READ COMMITTED
- 读锁:短期读锁。锁在 SELECT 语句执行完成后立即释放。
- 写锁:长期持有谓词写锁。
- 后果:由于读锁不跨语句保持,同一事务内两次 SELECT 可能读到不同的值(不可重复读和幻读可能发生)。
3. REPEATABLE READ
- 读锁:长期读锁(行级)。锁在事务提交时才释放。
- 写锁:长期持有谓词写锁。
- 后果:同一事务内多次读取同一行会得到相同值(防止不可重复读),但由于不锁定谓词(不锁定间隙),其他事务仍然可以插入满足条件的新行(幻读可能发生)。
4. SERIALIZABLE
- 读锁:长期读锁,且作用于谓词(Predicate),而非仅作用于行。
- 写锁:长期持有谓词写锁。
- 后果:通过谓词锁定(Predicate Locking)防止幻读,保证所有调度可串行化。
谓词锁定与幻读的防止
PPT 特别强调了**幻读(Phantoms)**的成因和解决方法:
幻读的产生原因
- 当事务 T1 使用谓词 P(如
name = 'Mary')进行 SELECT 时,它只锁定了当前存在的满足 P 的行。 - 事务 T2 插入了一个新行,该行也满足 P,但由于该行在 T1 锁定时还不存在,所以未被锁定。
- 导致 T1 再次查询时看到了新行(幻影行)。
防止幻读的方法
- 谓词锁定(Predicate Locking):锁定谓词本身,阻止任何可能插入满足该谓词的新行的操作。但实现过于复杂(谓词可满足性判定是 NP-complete 问题)。
- 索引锁定(Index Locking)/ 键范围锁定(Key-Range Locking):通过锁定索引页或索引条目之间的间隙(gap)来防止幻读。MySQL InnoDB 的 Gap Lock 就是这种思路。
- 表级锁定(Table Locking):锁定整个表,简单但并发度极低。
总结
| 隔离级别 | Dirty Read | Non-Repeatable Read | Phantom | 读锁时长 | 读锁范围 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | 可能 | 可能 | 可能 | 无读锁 | N/A |
| READ COMMITTED | 不可能 | 可能 | 可能 | 短期 | 行 |
| REPEATABLE READ | 不可能 | 不可能 | 可能 | 长期 | 行 |
| SERIALIZABLE | 不可能 | 不可能 | 不可能 | 长期 | 谓词 |
Durability
Redo Log & Undo Log
1. 作用
- Redo Log(重做日志):保证 Durability(持久性)。若已提交事务的数据页还未刷盘就发生崩溃,重启后通过 Redo 重新应用已提交事务的修改。
- Undo Log(撤销日志):保证 Atomicity(原子性)。若事务中止(Abort)或崩溃时为未提交”Losers”,通过 Undo 回滚其修改,恢复旧值。
2. 日志记录内容
典型 Update 日志记录包含:
1 | |
oldValue→ 用于 UNDOnewValue→ 用于 REDOprevLSN→ 同一事务内反向链接,便于回溯撤销
3. Compensation Log Record (CLR)
- 在执行 UNDO 时写入,记录撤销动作本身
- CLR 含
undoNextLSN(指向原记录的 prevLSN),避免重启时重复撤销 - CLR 也会被 REDO(保证重复历史),但 永远不会被 UNDO
4. 日志类型(ARIES / PostgreSQL / InnoDB)
| 类型 | 说明 |
|---|---|
| Physical Logging | 记录页面内具体字节变化(old/new bits) |
| Logical Logging | 记录操作及参数(如 UPDATE field WHERE key=37 ADD 32),需逆操作做 Undo |
| Physiological Logging | ARIES 常用——指定页面 + 页面内逻辑操作(如”在page 298 index 17处替换记录”) |
| InnoDB | Redo=物理/生理,Undo=逻辑(MVCC + Rollback) |
| PostgreSQL | 无独立 Undo Log,采用 MVCC 就地标记删除+插入新版本,只有 Redo(WAL) |
二、WAL 日志与 Log Sequence Number (LSN)
1. Write-Ahead Logging (WAL) 协议
- Undo Rule:数据页写入磁盘前,对应更新操作的日志必须先刷盘(force log record first)
- Redo Rule:事务提交前,其所有日志记录(含 Commit 记录)必须先刷盘
2. Log Sequence Number (LSN)
- 每条日志记录有唯一且递增的 LSN
- pageLSN:每个数据页保存”最近一次修改它的日志记录的 LSN”
- flushedLSN:系统记录已刷入稳定存储的最大 LSN
- WAL 约束:数据页允许写盘 ⇔
pageLSN ≤ flushedLSN(确保日志先落盘)
3. 辅助内存结构
| 结构 | 内容 |
|---|---|
| Transaction Table | 活跃事务表:XID、status(running/committed/aborted)、lastLSN |
| Dirty Page Table (DPT) | 缓冲池中脏页:pageID、recLSN(首次使该页变脏的日志记录的 LSN) |
三、Checkpoint(CKPT)优化
目的:限制崩溃恢复时需要向前扫描的日志长度。
Fuzzy Checkpoint 过程
- 写
begin_checkpoint日志记录 - 写
end_checkpoint日志记录,附上当前的 Transaction Table 和 Dirty Page Table 快照 - 将 checkpoint 记录的 LSN 存入 Master Record(稳定存储已知位置)
- 其他事务正常运行(fuzzy),不强制刷脏页到磁盘
- 恢复时从 Master Record 找到最近 checkpoint,结合日志做 Analysis
四、Transaction Commit 流程
- 事务执行若干读写,严格 2PL(写锁持有至提交),采用 STEAL / NO-FORCE
- 写
<Commit>日志记录到 WAL Buffer - 将事务所有相关日志(含 Commit 记录)强制刷盘(fsync) ← 关键持久化点
- 返回
Commit()给客户端,随后释放锁 - 写
<End>日志记录(标示 commit/abort 处理完毕)
InnoDB 中由
innodb_flush_log_at_trx_commit控制刷盘策略(1=每次提交都 fsync,最安全)
五、Crash Recovery —— ARIES 三阶段
恢复从最近的 Checkpoint 开始(通过 Master Record 定位):
Phase 1 — Analysis(分析,正向扫描)
- 从
begin_checkpoint恢复 Xact Table 和 Dirty Page Table - 正向扫描日志:
- 遇到 Begin/Update → 加入/更新 Xact Table(
lastLSN=LSN);若是新脏页加入 DPT(recLSN=LSN) - 遇到 Commit → 标记 status=committed
- 遇到 End → 从 Xact Table 删除该事务
- 遇到 Begin/Update → 加入/更新 Xact Table(
- 结束后得到:哪些事务是 Loser(活跃或已 Abort 但未 End),以及 DPT 中最小
recLSN
Phase 2 — Redo(重做,正向扫描)
- 从 DPT 中最小
recLSN开始正向扫描 - 对每个 UPDATE 或 CLR 记录:
- 若目标页不在 DPT → 跳过
- 若页在 DPT 且
pageLSN < LSN→ 重做(REDO)该操作,将新值写回页,设pageLSN = LSN - 若
pageLSN ≥ LSN→ 页已更新过,跳过
- 效果:重复历史(Repeat History),把数据库恢复到崩溃前一刻的状态(含 Loser 的未提交修改)
Phase 3 — Undo(撤销,反向扫描)
- 收集所有 Loser 事务的
lastLSN放入ToUndo集合 - 反复取最大 LSN 处理:
- 若是普通 UPDATE → 撤销写旧值,写 CLR(含 undoNextLSN=prevLSN),把
prevLSN加入 ToUndo - 若是 CLR:
undoNextLSN == NULL→ 写<End>记录,事务完成undoNextLSN != NULL→ 将该undoNextLSN加入 ToUndo(继续追溯原链)
- 若是普通 UPDATE → 撤销写旧值,写 CLR(含 undoNextLSN=prevLSN),把
- 结束后所有 Loser 的影响被清除,写对应
<End>记录
关键思想:先 Redo 重复全部历史(含 Loser 的写入),再统一 Undo Loser——简化了恢复逻辑,避免判断哪些页被 Loser 污染过。
六、小结对照表
| 项目 | 要点 |
|---|---|
| WAL | 先写日志再写页;提交时刷所有相关日志 |
| LSN | 单调递增,链接日志+标记页版本(pageLSN) |
| Checkpoint | Fuzzy,存 Xact Table + DPT,缩减恢复扫描范围 |
| Commit | 写 Commit 日志 → 刷盘 → 返回 → 释放锁 |
| Recovery | Analysis → Redo(repeat history) → Undo(loser txns, 写CLR) |
| CLR | Undo 时写,含 undoNextLSN,防止重启重复撤销 |
Availability
一、为什么需要 Availability & Replication(可用性背景)
- Durability(持久性) 靠 Logging 保证——服务器宕机后数据不丢,但服务在此期间对客户端不可用。
- Availability(可用性):通过 Replication(复制)——将数据和服务复制到多台服务器,单点故障不影响对外服务。
- Primary-Backup 是最经典的复制架构之一。
二、Primary-Backup 基本模型
1. 工作原理
- Client 只向 Primary(主节点)发送请求。
- 只有 Primary 执行请求、更新状态。
- Primary 将状态更新(state-update / log)同步给 Backup。
- 若 Primary 失效,某个 Backup 晋升为新 Primary。
2. 形式化性质(Formal Spec)
- Pb1:任意时刻至多存在一个 Primary。
- Pb2:Client 只向它认为是 Primary 的节点发请求。
- Pb3:非 Primary 不处理 Client 请求。
- Pb4:存在固定 k、Δ,使服务表现为
(k, Δ)-bofo server(最多 k 段中断,每段不超过 Δ 时间)——即故障导致的不可用窗口有界。
3. 故障检测(简单心跳协议)
- Primary 每 τ 秒发心跳(dummy message)。
- Backup τ+δ 秒未收到心跳 → 认为 Primary 失效 → 晋升为 Primary。
- 服务表现为
(1, τ+4δ)-bofo。
4. ⚠️ 关键顺序约束:先发状态更新,再回客户端
Response must be sent AFTER state-update message
若 Primary 先回 Client 再发 state-update,Primary 恰在此时崩溃 → Backup 未收到更新 → 新 Primary 状态缺失 → Client 读到不一致结果。
正确做法:Primary 先向 Backup 发 state-update,等确认(或至少发出并落盘)后再向 Client 返回响应。
Consensus
一、Viewstamped Replication (VR / VSR)
1. 基本思想
- State Machine Replication:各副本维护相同的操作日志(Log),按相同顺序执行日志 → 副本状态一致。
- 使用 Primary-Backup + View(视图) 机制处理主节点故障。
- 静态配置
S1,S2,...,Sn,通过 View Number 映射 Primary:primary = view_number % N。 - Quorum(法定人数)= 多数派(Majority = ⌊N/2⌋+1)。
2. 正确性条件
- 操作在 多数派节点同一 log position 被复制后才视为 Committed。
- 同一 log position 不会提交两个不同的操作。
- 新 View 的 Primary 必须先学习旧 View 中所有已 Committed 的日志(Quorum Intersection 保证:任意两个多数派交集非空 → 至少有一个节点含所有 committed entries)。
3. 节点状态
| 字段 | 含义 |
|---|---|
curV |
当前 View Number |
status |
NORMAL / VIEW-CHANGE / RECOVERY |
op-num |
日志最后一条位置 |
commit-num |
最后已提交位置 |
lastV |
上次处于 NORMAL 状态的 View Number(View Change 选日志用) |
4. 正常处理(Normal Case)
- Client 发请求 → Primary
- Primary 追加请求到本地 log(
op-num++),发送Prepare(curV, req, op-num)给备份 - Backup 校验
curV匹配、status=NORMAL、前面 log 已补齐 → 追加 log → 回OK - Primary 收到 多数派 OK → 标记 committed → 执行 → 回 Client
- 后续
Prepare/StartView中通知 Backup 推进commit-num
Prepare 阶段先等前面 log entry 都存在才追加(保证 backup log 是 primary log 的前缀)
5. View Change(主节点故障切换)
发起条件:Backup 超时未收到 Primary 心跳/Prepare → 发 ViewChange(newV) 给所有节点。
View Change 流程:
- Acceptor 拒掉
curV > msg.V的请求;若接受则设curV=msg.V, status=VIEW-CHANGE,返回自身(log, lastV) - 新 Primary(View 中映射的节点)收到 多数派 ViewChange 回复
- 决定新日志(New Log Selection Rule):
- Rule 1:优先选
lastV最大的日志(保证学到旧 View 已 committed 的 ops) - Rule 2:若多个
lastV相同,选 log 最长的
- Rule 1:优先选
- 新 Primary 发
StartView(V, newLog)给所有节点 - 各节点替换 log、
curV=V、status=NORMAL
6. Recovery(节点恢复 / 落后追赶)
- healed 节点发
Recovery给集群 - 其他节点回
(curV, log, op-num, commit-num) - 恢复节点从多数派取最新
(curV, log)覆写本地 → 设status=NORMAL
7. VR 容错
- 容忍 f 个 Crash 故障需 N = 2f+1 个节点(多数派仲裁)
- 网络分区时小分区无法形成多数派 → 停止服务(CP 系统)
二、Paxos(Single-Decree & Multi-Paxos)
1. 问题定义(Consensus)
- N 个节点,异步网络,非拜占庭故障(Crash-Stop)
- Safety:所有节点最终选定同一个值
- Liveness:活节点最终选定某值(FLP 不可能定理 → 需随机化/超时打破平局)
2. 角色
| 角色 | 说明 |
|---|---|
| Proposer | 提出提案 (proposal number + value) |
| Acceptor | 接受/拒绝提案 |
| Learner | 获知被选定值(通常所有节点兼之) |
- 值被 Chosen(决定) ⇔ 被 多数派 Acceptor 接受
3. Basic Paxos(Single Decree)—— 两阶段协议
每个 Acceptor 维护:
h_n:见过的最高 proposal numbera_n:接受过的最高 proposal numbera_v:在a_n下接受的值
Phase 1 — Prepare(发现 Safe Value)
- Proposer 选全局唯一递增 Ballot Number
n(如(本地计数器, serverID)),发Prepare(n)给 Read Quorum(多数派) - Acceptor:若
n ≥ h_n→h_n=n,回<OK, a_n, a_v>;否则忽略 - Proposer 收多数派 OK:
- 若有 Acceptor 返回
(a_n≠0, a_v)→ safe_value = 带最大 a_n 的 a_v(已部分 chosen 必须延续) - 若无返回已接受值 → safe_value = 自己提议值(自由选)
- 若有 Acceptor 返回
Phase 2 — Accept(提交)
- Proposer 发
Accept(n, safe_value)给 **Write Quorum(多数派)` - Acceptor:若
n ≥ h_n→h_n=n, a_n=n, a_v=safe_value,回 OK - Proposer 收多数派 OK → Value Chosen → 通知 Learners
关键:若某值已被 Chosen,所有更大 Ballot Number 的 Proposer 经 Phase 1 必发现该 safe value 并继续提案它(Paxos 安全核心)
4. Multi-Paxos(日志复制 / Replicated State Machine)
- 对 log 中每个 slot(index=0,1,2…)运行一个 Single-Decree Paxos 实例
- 优化(Distinguished Leader):选一个 Leader,先跑一次 Phase 1(
Prepare(ballot)成为 leader 并学旧 log),之后所有 log slot 只跑 Phase 2(Accept(ballot, value, index)),极大减少 RTT - Leader 故障 → 新 Leader 先 Phase 1 学 log → 接手 Propose
- 各节点按顺序执行已 Chosen 的 log entry(需等前一个 entry chosen/committed 再执行)
三、VR vs Paxos 核心对比(PPT 隐含)
| 维度 | Viewstamped Replication | Paxos / Multi-Paxos |
|---|---|---|
| 架构 | Primary-Backup + View Change | Leader-based Proposer(Multi-Paxos有Leader) |
| 日志确定 | Primary 分配 seqno,Prepare 达多数派即 committed | 每 slot 经 Paxos Instance 达多数派 Accept 才 chosen |
| 故障切换 | View Change,新 Primary 从多数派学 log(lastV+最长) | 新 Leader 先 Phase 1 学已 Accepted 值再 Phase 2 |
| 理论地位 | 与 Paxos 同期(1988),同样解决异步共识 | 最经典共识算法(Lamport 1989) |
| 工程使用 | 较少直接实现,思路影响 ZAB/ZooKeeper | Multi-Paxos 思路影响 Spanner、Cassandra 等 |
PPT 最后指出:Raft 本质上是 VR/Paxos 思想的工程化重构(加了 log matching + 选举限制),Raft* 可证明 Refine Paxos。
GaussDB
一、VectorDB(向量数据库)
1. 基本概念
| 概念 | 定义(PPT原文) |
|---|---|
| 向量 (Vector) | 有序数值序列,为AI理解世界的通用数据形式,是多模态数据的压缩表示 |
| Embedding | 将文字/文本转化为保留语义关系的向量 |
| 向量搜索 | 在海量存储向量中找到最符合要求的 TopN 个目标(相似模糊匹配,无精确标准答案) |
| 向量数据库 | 用以高效存储和搜索向量,通过 embedding 函数描写非结构化数据特征,提供查询、删除、修改、元数据过滤等操作 |
- 传统数据库难管理高维非结构化数据;AI 将极高维数据降维至百~万维后,向量数据库可高效检索。
- 向量搜索多基于距离远近(L2欧氏距离、Cosine余弦相似度、Hamming汉明距离)决定相似度,挑战是维度灾难。
2. 向量数据库关键指标(PPT P10)
| 指标类别 | 说明 |
|---|---|
| 容量大 | 支持高维向量(维度=浮点数个数),维度越高描述越精细但计算和存储开销越大 |
| 响应快 | 平均响应时延(发起查询→获取结果)、QPS、索引构建时间 |
| 召回准 | 召回精度(检索结果与真实最相似结果的匹配度)、召回率(检索中实际相关结果占全部相关结果比例) |
| 基础能力 | 易用性、高可用、高可靠、高安全 |
3. 典型应用场景(PPT P6/P15-P18)
- RAG(检索增强生成):企业知识库向量化存储,LLM 查询时先检索相关片段注入 Prompt,查得快(毫秒级)、查得准(流式更新不降精度)、成本低(统一存储)。
- AI数据湖:百PB~千PB多模态数据统一湖格式,支持向量+标量+GIS+图谱多模融合检索。
- Agentic AI / 记忆体:作为大模型”长期记忆”,支持 PB 级情景/语义/程序记忆分层存储与关联检索(工作记忆+情景记忆+过程记忆+语义记忆)。
- KV Cache推理加速:将 Transformer 的 KV Cache 分块提取表征向量存入向量库,推理时稀疏检索相关 KV Cache,降低长序列推理显存占用和提升吞吐。
4. GaussVector 技术亮点(PPT P24-P30)
- 高性能 GsDiskANN 图索引:基于 DiskANN + QSG 选边策略 + 极致 PQ 距离计算加速,内存-磁盘混合近邻检索,磁盘访问场景平均时延 5.1ms vs Milvus DiskANN 17.45ms。
- 向量流式更新(FreshDiskANN):动态邻居选择 + 路由节点延迟删除(墓碑)+ 局部重建,支持 GPTCache 场景时延 <150ms,减少算力开销 15%。
- 向标混合查询 + BM25 文本检索:B+树 + 倒排表 + 图索引,支持标量任意组合过滤 + 向量近邻,双库合一支撑双路召回。
- 基于聚类的向量分发(分布式):以向量聚类中心为分布键,相似向量汇聚同节点,百亿千维百毫秒查询(20节点100亿128维 recall>99% @25ms)。
- NPU 异构加速:昇腾 NPU 卸载矩阵运算,IVF 索引构建性能提升 10x+,查询提升 2x+。
5. SQL 接口示例(向量查询)
1 | |
二、TopK(向量搜索 / ANN)
1. TopK / ANN 定义(PPT P3)
- KNN(K-Nearest Neighbor):精准匹配 TopK——精确计算所有向量距离排序取前 K,复杂度 O(N×D),海量数据不可行。
- ANN(Approximate Nearest Neighbor,近似最近邻):模糊匹配 TopK——通过索引(如 DiskANN/HNSW/IVF-PQ)近似找最相似的 K 个向量,牺牲少量精度换取极高性能,是向量数据库核心查询模式。
2. TopK 在 SQL 中的实现
- 用
ORDER BY vector_col <operator> '[query_vec]' LIMIT K指定:<->:L2 欧氏距离(越小越相似)<=>:Cosine 余弦相似度(越小越相似,归一化后)<#>:Hamming 距离
LIMIT K= TopK 中的 K(返回最相似的 K 条记录)- 向标混合查询时先向量检索候选集,再标量过滤;若过滤后不足 K 条,以步长(如128)扩展候选集直至满足或超限。
3. ANN 算法挑战(PPT P11-P12)
- 无单一最优 ANN 算法适合所有场景,需在准确性/成本/性能/时效性/索引更新间系统均衡。
- 主流算法:IVF-PQ(倒排+乘积量化)、HNSW(分层小世界图)、DiskANN(Vamana图+SSD友好)。
- GaussVector 采用改进 GsDiskANN,支持流式更新、向量聚类分布式分发、NPU 加速。
小结:向量数据库(VectorDB)核心是高效存储高维 Embedding 并提供 ANN TopK 近似最近邻查询,GaussVector 基于关系型数据库扩展,融合 DiskANN 索引、向标混合查询、分布式向量聚类分发和 NPU 加速,支撑 RAG、Agent 记忆体和 KV Cache 推理加速等 LLM 应用场景。TopK 查询通过 ORDER BY 向量距离 LIMIT K 实现,底层依赖 ANN 索引避免全量 KNN 计算。
- AI4DB
根据你上传的《GaussDB数据库智能领域技术解读 - 周兆琦.pptx》,为你总结 AI4DB 与 DB4AI 相关内容如下:
一、AI4DB(AI for Database)—— 用 AI 让数据库更智能
PPT定义:利用机器学习/深度学习算法优化数据库内核与运维,实现自监控、自诊断、自恢复、自调优(四自),降低对人力的依赖。
1. 内核级 AI 技术(AI-Based Optimizer)
- 智能基数估计(Cardinality Estimation):基于库内轻量级**贝叶斯网络(Bayesian Network)**捕捉列间相关性,解决传统单列统计信息在多列复合谓词下估算偏差大的问题;相比神经网络更易落地、可解释性强。
- 计划自适应选择(Adaptive Plan Choice):基于多版本探测缓存执行计划,根据运行时数据分布自动选择最优计划,解决因数据倾斜、Offset 查询等引起的计划跳变。
- 效果:典型场景基数估计准确率提升约 1 倍,端到端查询性能提升 50%+;计划自适应选择性能提升 1x+。
2. 自治运维平台(DBMind)
| 能力 | 说明 |
|---|---|
| 自监控 | 时序 KPI 采集(CPU/IO/QPS/慢SQL等),异常检测(Spike/Level Shift/Volatility等),趋势预测(AR模型),全量健康巡检 |
| 自诊断 | 慢SQL根因分析(KNN特征匹配),指标关联分析(找最强相关指标定位根因),Workload 分类与 SQL 透视 |
| 自调优 | 离线/在线参数推荐(深度强化学习+全局优化),单Query/Workload级索引推荐(假设索引 hypopg),物化视图推荐,分布键推荐,SQL 重写建议 |
| 自愈 | 慢盘检测恢复,异常会话查杀,自动扩缩容,基于规则/知识图谱的故障恢复建议 |
3. 智能运维系统(GaussDB Doer)
- 智能问答:基于 RAG(向量+文本融合检索、重排序、切短查长分块、微调嵌入模型),回答 GaussDB 部署/功能/运维问题,避免 LLM 幻觉。
- 智能运维 Agent(Multi-Agent):故障诊断多智能体协作(检测→定界→定位→恢复→报告),支持子目标分解(CoT)、动态专家招募、短期/长期记忆(知识图谱固化经验)、SKILL 自演化。
- 价值:交互式自然语言运维,一键诊断,自排障率 >90%,覆盖 TOP 故障场景。
二、DB4AI(Database for AI)—— 数据库原生支持 AI 工作流
PPT定义:数据库内建 ML 引擎,数据不出库完成数据清洗→特征工程→模型训练→推理→管理,提供原生 SQL 语法,支持向量检索(RAG 底座)。
1. 库内机器学习引擎(In-Database ML)
原生 SQL 语法:
1
2
3
4
5
6
7-- 训练
CREATE MODEL price_model USING logistic_regression
FEATURES size, lot TARGET price FROM houses;
-- 推理
SELECT address, PREDICT BY price_model(FEATURES size, lot)
FROM houses;支持算法(20+,覆盖 >95% 场景):
- 分类:Logistic Regression、Naïve Bayes、Decision Tree、Random Forest、XGBoost、Softmax
- 回归:Linear Regression、XGBoost Regressor
- 聚类:KMeans
- 降维:PCA
- 其他:KNN、DBScan、GLM、Bayes Net
AutoML:超参数调优(HPO)、特征选择/处理、模型评估、模型版本管理。
性能:并行训练 + 指令集加速,相比 MADlib 提升 5-10 倍;数据不出库保证安全。
2. 库内向量检索引擎(VectorDB / RAG 支撑)
- 索引:GsDiskANN(改进 DiskANN + 动态稀疏选边 + 局部重建,支持流式更新)、IVFFLAT。
- 向标融合检索:基于 CBO 选择策略——低选择率用倒排 Bitmap 过滤后图搜,高选择率先 ANN 再回表过滤。
- 分布式:向量聚类分布键,相似向量同节点,百亿向量 25ms@99%召回。
- 应用:企业 RAG 知识库、Agent 长期记忆、KV Cache 推理加速。
3. 库内语义算子引擎(Semantic Engine)
- 扩展 SQL 支持语义过滤/匹配/聚合,一站式 RAG(Embedding → 向量检索 → LLM 生成)全部可用 SQL 表达。
- Batch 优化(多行一次调用 LLM)、Limit 下推(减少冗余推理)。
- 示例:
1
2
3WITH q AS (SELECT create_embedding('如何办理网银?') AS emb)
SELECT content FROM docs
ORDER BY embedding <=> q.emb LIMIT 5;
三、AI4DB vs DB4AI 对照
| 维度 | AI4DB | DB4AI |
|---|---|---|
| 目标 | 数据库自身更自治、高性能、易运维 | 数据库成为 AI 应用的数据+计算底座 |
| 技术手段 | 贝叶斯网络基数估计、RL参数调优、异常检测、索引推荐、RAG智能问答、Multi-Agent运维 | 库内训练/推理 SQL、向量索引(DiskANN)、向标融合、语义算子、AutoML |
| 典型用户 | DBA、运维人员 | 数据科学家、应用开发、LLM应用(RAG/Agent) |
| 核心价值 | 减人力、自动优化、快速排障 | 数据不出库、低延迟、简化 AI Pipeline |
小结:GaussDB 的 AI 能力分为两个方向——AI4DB 用 AI 优化优化器与自治运维(基数估计、自调优、DBMind/Doer),DB4AI 在库内提供 ML 训练推理、向量检索(DiskANN)和语义算子,支撑 RAG 与 AI 应用一站式开发。两者共用异构计算(GPU/昇腾)、模型管理及安全底座。
LEC 8: Distributed Storage: Sequential Consistency
Consistency Model
一致性模型是指一个存储系统在并发操作下如何处理同步和一致的约定
Strong Consistency
- 所有数据只有一个版本
- 读写等价于串行化的读写(线程之间的顺序可以不一样)
- 读写可以被视为一个从未 failed 的系统
- 根据等价于哪种串行化 分为:
- Strict Consistency:串行化顺序符合发生时间顺序 没有人实现这种模型 因为会有网络延迟的区别 机器的时钟不同步等问题
- Linearizability:如果 B 在 A 结束之后开始 串行化顺序中 B 一定在 A 之后
- Sequential Consistency:对于各个线程内的操作 保证串行化顺序和发生时间顺序一致 对于不同线程则不保证
Release Consistency
Eventual Consistency:所有服务器的数据最终会达到一致
如何实现 Linearizability?
- local property:如果一个数据的所有操作是线性化的 多个数据的操作组合也是线性化的
The simplest approach:centralized KVS
- 对于一个 server 客户端只需要把读写请求发送给这个 server 即可 记住在收到确认之前不能视为完成操作
- 假设接下来每个客户端需要有自己的 replica 我们采用 Primary-Backup model
- 对于每一个数据项 有一个指定的客户端作为 primary
- 对于写 primary 先转发给所有 replicas 全部写入后返回 最终在 primary 本地写入
- 为了防止 replicas 收到请求的顺序不一样 primary 会使用一个全局 counter 来为每一个 write request 加上 seq number replic 在收到前一个写之前不会执行后一个写
- 对于读 返回 primary 的数据 而不能读 replica 本地的数据 否则会产生在本地写入但是在 primary 未写入之前读取数据不一致的情况
- Drawbacks
- 读写需要额外的 RTT
- 一个 primary 会成为性能瓶颈和单点故障
- 这个模型的 backup 主要是为了容错 而不是提高性能 因此读写还是单节点的
- partitioning:把不同数据分区到不同的 primary 上 来解决只有一个 primary 导致的性能瓶颈问题
Drawbacks of linearizability
- 太慢 每一个操作都需要等待确认
- 单个 primary 会成为性能瓶颈和单点故障
- 难以提供 fault tolerance 因为 primary 一旦挂了就无法提供服务
LEC 9: Distributed Storage: Eventual Consistency
- Eventual Consistency:如果没有新的写入操作 那么所有服务器的数据最终会达到一致
- 实现 eventual consistency 是为了更高的性能
- READ:读取本地的最新数据
- WRITE:写入本地的数据 在后台异步地把写数据同步到其他服务器
如何实现 Eventual Consistency?
Write-write conflict
- write-write conflict:两个不同的客户端同时写入同一个数据
- linearizability 是悲观的解决方案 所有写入都会先在 primary 上确定顺序 于是先到的先写入
- eventual consistency 是乐观的解决方案 先写入 之后再解决顺序问题 也正因此 读可能会读取到不一致的数据 但是最终会一致
- 不能再使用 update 操作 这有可能导致最终不符合语义 需要 append 操作 使用 update function 可以定义任意的数据库操作
- 通过 Ordered Update Log 来统一不同设备间的操作顺序 每个设备会把操作记录在自己的 log 里 同步时确保两台设备的 log 中顺序一致
- 同步时用什么确定 order?可以使用时间戳 如果时间戳一致则使用设备 ID
- 上述实现会在同步后才进行数据库的写入 然而为了用户体验 需要在本地数据库立马执行写入操作 然而如果这样做 当同步时 两个设备的初始状态是不同的 可以使用 Rollback and Replay 来解决这个问题
- 在 SYNC 前 设备把所有修改进行回滚 回到了初始状态 然后根据同步的 log 执行所有的操作 最终两台设备就会达到一致状态
- 时间一久 log 中的操作会非常多 导致回滚和重放的时间过长
- 解决方法是 checkpoint 即把 stable 的数据写入磁盘 然后截断 log 下面详细解释一下 checkpoint 的原理(使用的是 lamport clock):
- 设备 A 和设备 B 上一次同步时 如果同步得到的时间戳是 T 那么在同步之后发生的事件的时间戳一定大于 T 反之 小于等于 T 的事件一定在同步之前发生 也即一定被设备 B 所同步了
- 同理 对于设备 k 上一次同步的时间戳是 Tk 那么 Tk 之前的所有事件一定被 k 同步了
- 在设备 A 中维护一个 map 记录时间戳 Tk 时间戳小于 Tk 中最小值的事件 一定被其他所有设备同步了 也即 stable 的数据 可以写入磁盘
- 每一次和其他设备同步后 更新 Tk 集合 顺带更新了最小的 Tk 也就顺便把 stable 的数据落盘
- 问题:如果有一个设备一直离线 Tk 的最小值将永远不变
- 以下内容根本没听懂:
- 为了解决这个问题 引入 primary
- primary 会为每一个写分配 CSN(Commit Sequence Number) 分配到 CSN 的写都是 stable 的
- 不过会出现 reorder 现象

synchoronized clock time
为了用户体验 除了状态一致以外 还需要保证一些其他语义
Causal Ordering:在一台机器上 A 发生早于 B 或者是 A 触发了 B 的操作(比如 A 是添加数据 B 是删除数据)则 A 和 B 有因果关系
Lamport Clock:保证如果 A 是 B 的因 则 A 的时间戳小于 B 的时间戳 如果两个事件无因果关系(我们称其为并发事件) 则时间戳可能相等或无序
- 算法:
- 每个服务器保留一个时钟 T
- 随着时间的推移 T 会增加
- 收到一条消息的时间戳为 T’ 则更新 T 为 max(T,T’+1) 也即保证时间戳大于已经发生的事件
- 问题
- 时间戳可能相等 可以通过设备 ID 来解决
- 事件 A 发生在事件 B 之前 => A 的时间戳小于 B 的时间戳 但是反之不一定成立 因为每个设备的时间戳是独立的 换言之 没有办法确定 A 和 B 是因果关系还是并发事件
- 算法:
Vector Clock:用一个 n 维向量来表示时间戳 每个维度代表一个设备的时间戳 T[i]严格大于(即每个维度都大于)T[j] 则 i 发生在 j 之后 若无法比较 则是并发事件
- 算法:
- 若有 n 个设备 则每个设备有一个 n 维的向量代表时间戳
- 每个设备的时间戳初始时一样
- 设备 i 上 随着时间的推移 T[i] 自增
- 设备 i 向设备 j 发送消息时 把自己的时间戳 W 发送给对方 设备 j 把第 k 位时钟 更新为 max(V[k],W[k] + 1)
- 算法:
Summary
- scalability:仍有 primary 但是操作更轻量了
- 编程比较复杂
- fault tolerance:只要有一个设备存活就可以工作
LEC 10: Distributed Storage: All-or-nothing Atomicity
前面讲了两个一致性模型 是说系统如何处理并发操作来保证数据的一致性 然而面对各种 faults 这些模型将无法再保证数据的一致性 这就需要保证 atomicity 从而确保 faults 发生时数据不会出现不一致
Consistency under single-machine faults
- 任何调用都应该是 all-or-nothing 的 即要么全部成功 要么全部失败 否则会很难处理错误
- 以 bank transfer 为例 数据的一致性即保持账户总额不变
Achieving atomicity
Shadow Copy:保证对于一个文件的修改是原子的 通过写入一个新文件 然后重命名的方式来实现 因为重命名是原子的 虽然不会导致数据不一致 但是文件系统有可能会不一致
- Drawbacks
- 不支持并发 多个线程会同时写入一个原文件 导致覆盖
- 难以操作多文件 需要把所有文件放到一个目录下
- 拷贝开销大 即使只修改了一个字节也要拷贝整个文件
- Drawbacks
Journaling:上面的问题可以在 rename 之前写入 WAL 来解决 journaling 会导致极大的额外空间开销 所以可以只对 metadata 进行
- 通常磁盘会有一个电容 保证有足够的电力完成一个 sector 的写入
- 如果 journal 大于 sector size 怎么办?我们需要更通用的方法
Logging:可以见 AEA 事务笔记
REDO LOG
- logging 和 journaling 基本一致 不过 journaling 针对的是文件系统的细粒度操作 比如 rename
- 引入 transaction 的概念 一组原子性操作被称为事务
- 在准备操作前 写入 log 如何确保 log entry 是完整的?可以做一个 checksum
- redo-only logging’s pros & cons
- commit 很快速 只需要 append 操作到 log 中
- IO 利用率低 因为必须在事务提交时全部写入 log 如果在事务进行时就异步的写入 log 性能会更好
- 所有操作在提交之前需要缓存在内存中 万一内存不足就失败了
- log 无限增长 但是操作其实已经落盘了
UNDO LOG
- 为了解决 IO 和内存的问题 考虑在每一个操作后直接落盘 如果失败了需要全部回滚 因此引入了 undo log
UNDO-REDO
- undo 需要记录旧值 redo 需要记录新值 两者结合 每一个操作都记录新值和旧值 即可实现 undo-redo logging
- undo-redo 会记录每一个操作的 record 当系统调度不同事务时 可能不同的事务的 record 会交叉 因此需要一个指针来指向同事务的下一个 record
- record 的结构
- XID:事务 ID
- OID:操作 ID
- PTR:指向下一个 record
- VALUE:包括文件名、偏移量、旧值、新值
Put it together
- logging
- 每次操作前写入日志(WAL)
- 在 commit point 写入一个 commit record 到日志中
- recovery
- 从 end 遍历到 start
- 找到所有没有 commit 的事务 并添加 abort record
- undo 所有 abort 的事务 从后往前
- redo 所有 commit 的事务 从前往后
- logging
Problem:日志会无限增长 使用 checkpoint 来解决
- 等到没有任何操作在进行(而不是等到所有事务结束)
- 把 CKPT record 写入日志 CKPT 包括了所有当前正在进行的事务的 undo 和 redo 日志
- 把所有内存中的数据落盘
- 丢弃除了 CKPT 之外所有的日志
如何恢复?
- 如果 crash 时事务尚未提交 则应该保证事务回滚
- 如果事务在上一次 CKPT 后开始 则仅需 undo log
- 如果事务在上一次 CKPT 前开始 则需要 undo log 和 CKPT
- 如果 crash 时事务已经提交 则应该保证事务提交
- 如果事务在上一次 CKPT 前提交 不需要做任何事 因为 CKPT 内不会包含这个事务
- 如果事务在上一次 CKPT 后提交 且在 CKPT 后才开始 则需要 redo log
- 如果事务在上一次 CKPT 后提交 且在 CKPT 前就开始 则需要 redo log 和 CKPT
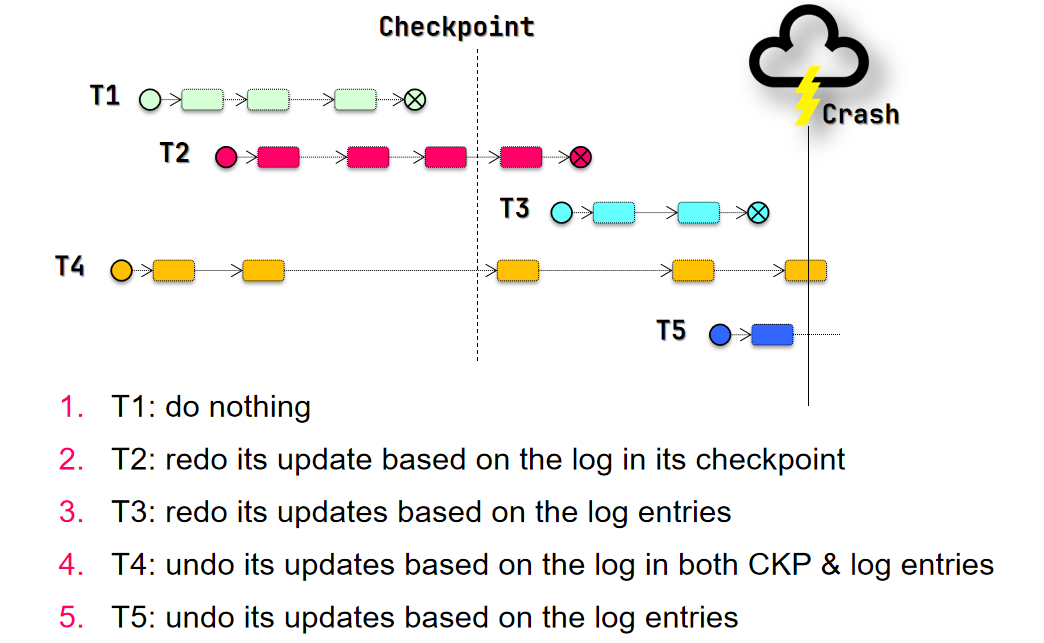
- 如果 crash 时事务尚未提交 则应该保证事务回滚
Undo-Redo vs Redo-Only vs Undo-Only
- REDO
- 更少的 IO 因为只需一半
- 更快的恢复 因为只需要从头到尾扫一遍
- 没有 UNDO 因此未提交的事务不得落盘 要求内存比较大 也就不适合事务太大 内存不够的情况
- UNDO
- 恢复快 和 REDO 一样
- 没有 REDO 因此提交的事务必须立马落盘 但是一个 page 可能包含多个事务的修改 这样就会重复落盘 很浪费性能;还有一种方法是每个操作都立马落盘 这样显然性能很差
- 由于上述原因 UNDO-ONLY 几乎不会用到
- UNDO-REDO
- IO 更多 是 REDO 的两倍
- 每条操作完了立马可以写入日志 IO 利用率比 REDO 高
- 恢复慢 要扫三遍
- REDO
Summary
- 保证原子性的方法
- shadow copy
- journaling
- logging
- Logging 同时也保证了 Durability 即一旦写入就不会丢失(因为可以 redo)
LEC 11: Distributed Storage: Before-or-after Atomicity & 2PL
- race condition:多个线程同时访问一个数据 由于操作包含多个步骤 会导致数据竞争
- before-or-after atomicity:也叫 isolation 保证一组读写操作是原子的 不允许其他线程看到中间状态
- 严格定义是 并发操作从自己的视角来看 其他的操作要么已经做完 要么还没开始
- 一组操作如何定义?用 Transaction 来定义 begin 和 end 会标记一组操作的原子性
Use Locks to achieve Isolation
- global lock:可以严格保证原子性 但是会导致性能瓶颈 粒度太粗
- fine-grained lock:对于每一个数据项加锁来减小粒度
- 如果一个事务涉及多个数据项的操作 细粒度锁并不能保证整个事务的 Isolation
- 解决方法:事务开始时按固定顺序获取所有数据项的锁 事务结束时再按相反的顺序释放所有锁
- 一旦数据量太大 内存中将放不下所有锁 对此可以预先设置最大数量的锁 数据项会哈希映射到锁上 只需确保同样的数据项会映射到同一个锁上即可
- 2PL(Two-Phase Locking)
- 在需要操作数据之前再获取锁
- 所有释放延迟到事务结束时 而不是在每个数据操作后立即释放
- 好处是推迟了锁的获取 减少了总占用时间
- 2PL 通过 serializability 保证了 before-or-after atomicity before-or-after atomicity 通常也被称为 serializability
Serializability
- Serializability:一系列事务的操作等价于它们串行执行的结果
- Final State Serializability:最终状态等价于串行化的结果
- Conflict Serializability:最常用的
- View Serializability
- Confilct ∈ View ∈ Final State
Confilct Serializability
2 opreations confilct if:
- 操作了同一个数据
- 至少有一个是写操作
- 它们属于不同的事务
定义:如果每个 conflict 的两个操作发生的顺序 和某一个串行化的都一致 则是 conflict serializable 的
Confilct Graph
- 每个节点是一个事务 边有向
- 如果 T1 和 T2 有冲突 且冲突的第一步是 T1 的操作 则有一条边从 T1 指向 T2
- 调度是 conflit serializable 的 <=> 其 conflict graph 是无环的 且节点的拓扑顺序就是其等价的串行化调度顺序
- Conflict Equivalence:如果两个 schedule 的 conflicts order 是相同的 则是 conflict equivalent 的
View Serializability
Informal Definition:如果一个 schedule 的最终状态与过程中间的读取结果可以等价于某一个串行化调度 则是 view serializable 的
Formal Definition
- 2 schedules S1 and S2 are view equivalent if:
- Ti 在 S1 中读取了 X 的初始值 且在 S2 中也读取了 X 的初始值
- Ti 在 S1 中读取了 Tj 的写入值 且在 S2 中也读取了 Tj 的写入值
- Ti 在 S1 中写入了 X 的最终值 且在 S2 中也写入了 X 的最终值
- 如果一个顺序和某一个串行化顺序是 view equivalent 的 则它是 view serializable 的
- 2 schedules S1 and S2 are view equivalent if:
View Serializability 的验证太复杂 因此很少使用 仅做理论研究
Conflict vs View
- Conflict Serializability 更容易验证 View Serializability 是近似 NP-hard 的
- Conflict Serializability 更容易实现 使用并发控制机制即可 比如 2PL
- Conflict Serializability 比 View Serializability 更严格
Proof of 2PL
2PL 保证了 conflict serializability 下面是证明:
- 假设不是 conflict serializable 则存在一个 cycle T1 -> T2 -> … -> Tk -> T1 设 Ti 和 Ti+1 间的冲突是对于变量 Xi 的
- 根据 2PL 的定义 Ti 在操作变量 X 之前会获取锁 也就是说 T1 要获取 X1 的锁 T2 要获取 X1 和 X2 的锁 … Tk 要获取 Xk-1 和 Xk 的锁 T1 要获取 Xk 的锁
- Ti->Ti+1 意味着对于数据 Xi Ti 的操作在 Ti+1 之前 因此 Ti 先拿到 Xi 的锁 再释放 Xi 的锁 然后 Ti+1 再拿到 Xi 的锁 同时因为 2PL 的定义 Ti+1 释放 Xi+1 的锁必定在 Ti+1 拿到 Xi 的锁之后 因此顺序为 Ti 释放 Xi 的锁 -> Ti+1 获取 Xi 的锁 -> Ti+1 释放 Xi+1 的锁 递推即可得到 T1 释放 X1 的锁在 Tk 释放 Xk 的锁之前 也就在 T1 获取 Xk 的锁之前 产生了矛盾
然而幻读现象是 2PL 情况下不满足 conflict serializability 的特例
一个典型的例子是:T1 是对于所有满足大于 300 的数据进行+1 操作 并 print 这些数据 T2 是插入一个新的大于 300 的数据
T1 在执行前会获取所有大于 300 的数据的锁 然而 T2 新插入的数据的锁却无法获取 因此 T1 修改完毕后 T2 立马插入新的数据 T1 再 print 时 读取到了新插入的数据 然而如果线性化 新的数据要么+1 了并且被 print 要么没有被+1 并且不被 print 而现在的结果是没有被+1 但是被 print 了 显然不符合冲突串行化的定义
幻读现象告诉我们 冲突定义中的数据项有时指的是一个范围内的数据 而不是一个具体的数据项(比如满足大于 300 的所有数据)此时只对于一个数据项加锁是不够的 需要对于整个范围加锁
解决方法包括:
- Predicate Locking:禁止其他事务插入符合条件的数据
- Range locks in B-Tree index:给 B-Tree 的索引加锁
- 或者干脆忽略
总结: 如果锁能够正确处理冲突的顺序 2PL 可以保证 conflict serializability
Deadlock
- 2PL 是悲观锁 仍有可能发生死锁
- Methods to prevent deadlock:
- 获取锁时按照一个固定的顺序获取
- 并不通用 许多事务并不能确定获取锁的顺序(比如从一个哈希表里获取数据)
- 根据 conflict graph 来检测死锁:
- 如果有环 则有死锁
- 终止其中一个事务来断开环
- 但是检测时需要串行 具有高开销
- 使用启发式算法来检测死锁 比如超时重试
- 可能会误判 或是活锁
- 获取锁时按照一个固定的顺序获取
LEC 12: Distributed Storage: Serializability, OCC & Transaction
OCC(Optimistic Concurrency Control)
大体思路是:执行事务时不拿锁 在提交前检查是否有冲突 如果有则终止或重试
OCC Execute a TX in 3 steps:
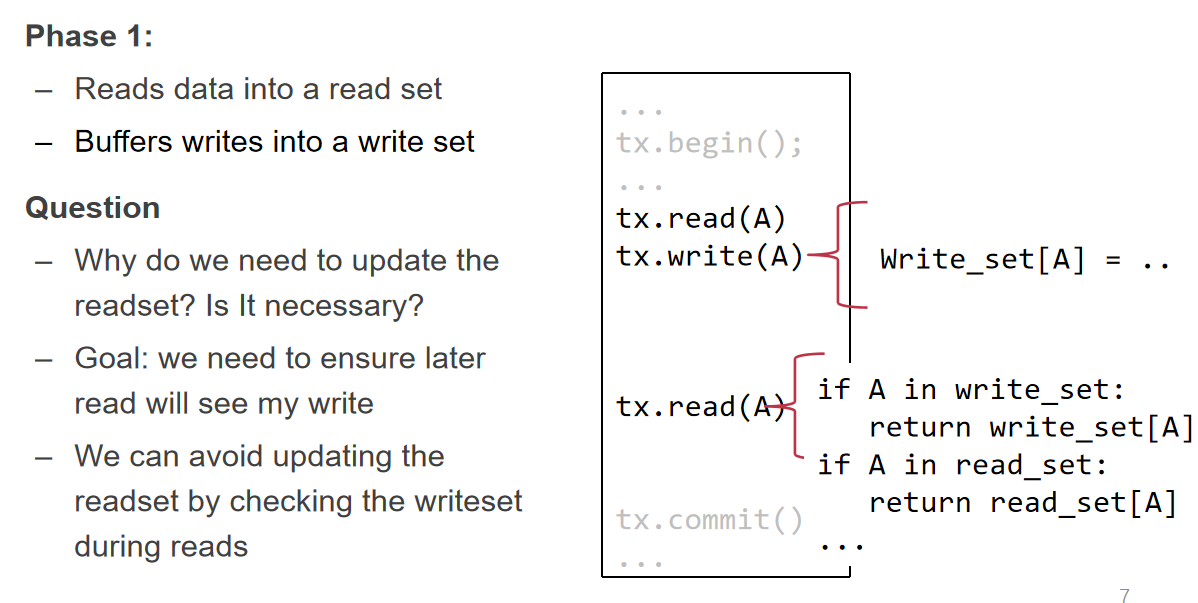
- Concurrent local processing(因为不拿锁 所以不能在原始数据上操作 而是在副本上操作)
- 初始化 read set 和 write set
- 遇到 READ:如果 read set 中已经有这个数据项 则返回 set 中的数据 否则从数据库中读取数据
- 遇到 WRITE:把数据写入 write set 如果 read set 中有这个数据项 则修改 read set 中的数据 (此处似乎有点问题 应该是如果整个事务需要读取这个数据项 则修改 read set 中的数据?)
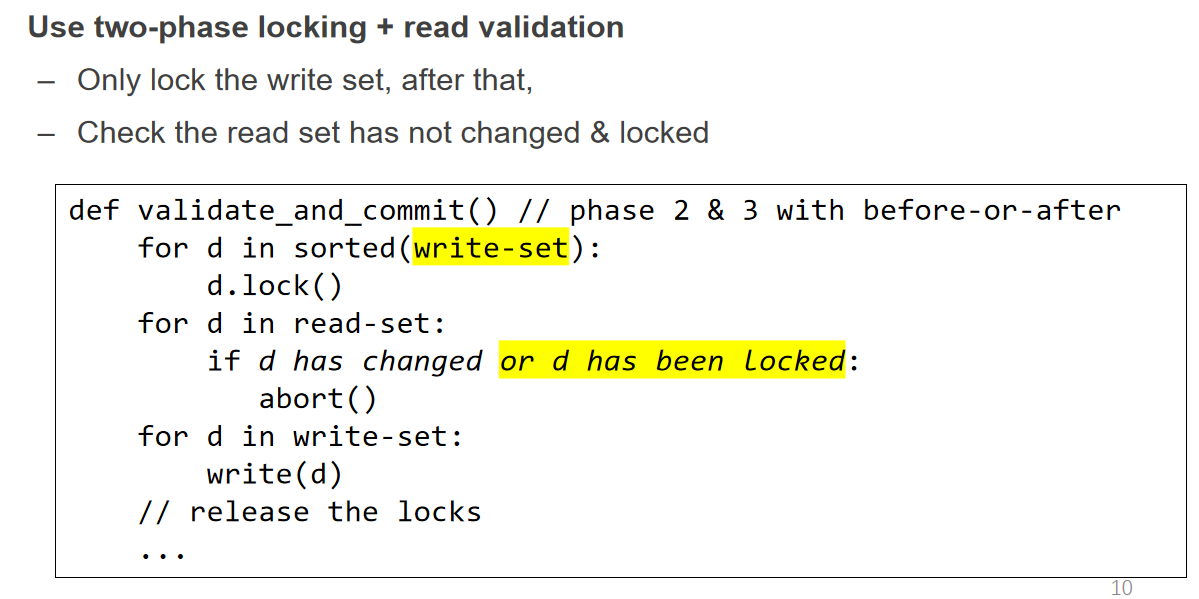
- Validation serializability in critical section
- 对于 read set 中的每一个数据项 检查是否和数据库中的数据一致 如果不一致则终止
- 为了防止 ABA 问题 可以记录每一个数据项的版本号 比较版本号即可

- Commit or abort in critical section
- 验证成功 则对于 write set 中的每一个数据项写入数据库

- 验证成功 则对于 write set 中的每一个数据项写入数据库
- Concurrent local processing(因为不拿锁 所以不能在原始数据上操作 而是在副本上操作)
Critical Section 指的是第 2、3 步也需要保证 before-or-after atomicity 确保验证到提交中间没有其他事务修改数据导致的 race condition
可以通过对第 2、3 阶段上一把全局锁来保证 由于锁的范围很小 因此性能不会受到太大影响
在分布式或高并发的场景下 还是需要上细粒度锁来提高性能 我们可以采用 2PL 验证 read set 之前获取锁 写入 write set 数据前获取锁 在提交或 abort 时释放所有锁
2PL 的死锁问题仍存在 不过现在我们必定知道哪些数据项会被访问 因此可以预先固定一个顺序来获取锁 即先把 read set 和 write set 中的数据项排序 然后按照这个顺序获取并释放锁即可
进一步思考 如果抛去 read set 数据的锁会如何?
- 如果 read set 数据被修改了 会导致验证失败 事务会被终止 肯定不会有问题
- 如果 read set 数据没有被修改 验证通过 有可能会在提交之前被修改 但是修改的数据项一定不在 write set 中 如果没有数据依赖 这个被修改的数据项一定可以等价于在提交之后发生 因此不会有问题
- 最后看看有数据依赖的特殊情境
- T1 执行 A+=B T2 执行 B+=A
- T1 读取 A 和 B T2 读取 A 和 B T1 获取 A 的锁 T1 通过验证 T2 获取 B 的锁 T2 通过验证 T1 写入 A T2 写入 B
- 此时 A 和 B 都被改为 A+B 显然不符合冲突串行化的定义
- 原因是虽然 T1 只写入 A 但是写入 A 的操作对于 B 有数据依赖 需要确保读取 B 和写入 A 之间不能被其他事务读取
- 解决方法也很简单 一个读取发生在其他事务的读取和写入之间 意味着读取后别的事务进行了写入 我们只需要检测这种情况即可 别的事务进行了写入之前一定会获取锁 因此在验证时 除了判断数据是否被修改 还需要判断锁是否被获取 也即数据是否正在被其他事务修改
Advantages
- 阶段 1 在 local 进行 线程间没有竞争 不需要任何锁 性能很高
- 阶段 2 需要锁 但是范围很小 性能也不错
- 对于 read-heavy 的应用 OCC 的性能很好 因为 read set 不需要锁 而 2PL 则全部需要锁
Problems
- False Aborts:OCC 检查有时会把满足 conflict serializability 的事务终止 原因是 OCC 验证时如果读后发生写会终止 也就是说任一读写冲突 OCC 只允许写操作在前的顺序 对于 read-heavy 的事务 abort 的概率会更高 甚至在低竞争的情况下也会出现
- livelock:高竞争的场景下 OCC 会不断的 abort 尤其是对于读写操作很多的大事务 从而导致事务在执行 但是却无法提交 业界会采取检测 abort 次数过多的事务 并且把它们转为 2PL 来解决这个问题
Summary
- 并发事务少时 OCC 的性能很好
- 当并发事务数越多 OCC 的性能会越差 逐渐低于 2PL
LEC 13: Distributed Storage: OCC, MVCC & Multi-Site Atomicity
Transaction
事务是对于管理数据的一组操作的抽象 具有 ACID 特性
- Atomicity:要么全部成功 要么全部失败
- Consistency:事务只会将数据从一个一致状态转换到另一个一致状态 然而这个状态是人为定义的 应用层面也会打破一致性 因此数据库无法保证 consistency
- Isolation:事务之间是隔离的 两个事务的并发一定可以串行化
- Durability:事务一旦提交 数据就会持久化
Summary
- A 与 D 用 log 来保证
- I 用 2PL、OCC、MVCC 来保证 同时还有 HTM 在硬件上实现 OCC 的思路
Multi-Site atomicity
- 当数据分布在多个 site 时 单机的原子性将不再适用 比如一个事务涉及到多个 site 的数据 在其中某一个 site 上发生了故障 则这个事务就无法保证原子性
- 如何保证分布式的原子性 即 Multi-Site Atomicity
2PC(Two-Phase Commit)
事务也应该是模块化的 一个大事务可以分解为多个小事务 小事务仍不失去原子性 在分布式架构下 可以把每一个 site 上的操作看作一个小事务 把统筹各个 site 小事务的操作看作一个大事务
2PC 大体思路
- Prepare Phase
- 将小事务的 commit 延迟
- 小事务要么 abort 要么 tentatively commit
- 大事务来评估小事务的结果
- Commit Phase
- 大事务决定小事务是否真正 commit:如果有至少一个小事务 abort 则大事务也 abort 否则 commit
- Prepare Phase
Logging in 2PC
- 分布式下 小事务执行到 commit point 时 只能保证自己的 Durability 无法保证其他事务的 因此无法真正提交
- 整个过程中只有 coordinator 是可以保证所有事务的 Durability 的 因此只有 coordinator 可以决定 commit 与否
- 小事务(worker)
- REDO-UNDO:保持不变
- commit record 需要改为 prepared record
- 记录需要带有大事务的 reference
- 当 failure 时 向 coordinator 询问是否 commit
- 大事务(coordinator)
- 有一个 prepare log 记录大事务是 commit 还是 abort
Challenge:unreliaible communication、coordinator & worker
Problem:如果小事务的日志是完好的 但是大事务的日志还未写入 没法判断是否 commit
Solution
- 听从 coordinator 的决定 如果大事务没有 record coordinator 可以向各个 worker 查看是否 prepared 如果都 prepared 则 commit 否则 abort
- worker 不能自己决定 必须向 coordinator 询问 确定了 commit 后 就可以把 prepared record 改为 commit record
本质上就是 小事务一旦处于 prepared 状态(也就是原来的 commit 状态)就意味着小事务已经保证了 A 和 D(原子性和持久性) 一旦所有小事务都处于 prepared 状态 大事务就保证了 A 和 D 因此就可以 commit
coordinator 给小事务发送 commit 的目的并非让小事务保证 A 和 D 而是让小事务把 prepared 改为 commit 从而可以继续下一个事务
Summary
- coordinator 需要记录每个小事务的 prepare 状态吗?不是必须的 反而会带来额外的开销
- 记住 logging 的最小化才是性能的关键
- 还剩一个问题:如何做 CKPT?
- 小事务的 CKPT 仍然一致 只要 commit 了就可以清除
- 大事务的 CKPT 会遇到新问题:worker 仍有可能询问这个 commit 什么时候才可以真正清除呢?
- 也很简单 coordinator 在异步发送 commit 给 worker 后 后台会收到每一个 worker 的 ack 等到所有 ack 都收到后再清除这个 commit
2PL & OCC in 2PC
- 2PL:给小事务上锁就能保证 Isoaltion 只需要每一个小事务直到大事务决定 commit 后才释放锁即可
- OCC:prepare 阶段和 OCC 的 validation 相结合 coordinator 除了询问 worker 是否 prepared 还需要 validate 是否有冲突 如果有冲突则 abort 否则 commit
Summary
- 2PC 保证了 Multi-Site Atomicity
- 然而一旦 coordinator 挂了 系统的可用性将被破坏 下节课将讨论如何解决这个问题
LEC 14: Distributed Storage: Replication & Consensus (Paxos)
- 2PC 只保证了 Consistency 通过 Replication 可以保证 Availability 与 Partition Tolerance
- Replication 可以提高性能和延迟(比如前端) 也可以提高可用性
- Replication Consistency
- Optimistic Replication:允许数据不一致 但是最终会一致
- Pessemistic Replication:保证 strong consistency
Pessemistic Replication
- 悲观复制意味着更低的可用性和性能 但是所有操作都可以被视为在一个 single copy 上执行的 用户将感知不到多个 replica 的存在 这和乐观复制不同
RSM(Replicated State Machine)
- 所有 replica 都可以被视为一个状态机 只需要保证输入和顺序一致 那么输出也一定一致 真正的关键在于请求的顺序如何保持一致
- RSM 可以使用之前提到的 primary-backup 模型实现 我们知道 primary-backup 模型最大的问题在于 primary 的单点故障导致可用性被破坏 下面我们会看到如何使用 View Server 和 Coordinator 来解决这个问题
- Coordinator
- 所有客户端的请求发送给 coordinator
- coordinator 会把请求转发给 primary
- 出现 multiple coordinators 时 会出现问题 因此引入了 view server
- View Server
- 管理 primary 和 backup 的选举 记录谁是 primary 谁是 backup
- 每个 replica 向 view server 进行心跳 维护每个节点的健康状态 当 primary 挂掉时 view server 会选举一个 backup 作为新的 primary 并找到空闲的 replica 作为新的 backup
- 新的 primary 收到 vs 发送的任命状之前会拒绝所有 coordinator 的请求 此时旧的 primary 仍可以正常处理请求
- 新的 primary 收到任命状后会开始处理请求 旧的 primary 如果收到 coordinator 的请求 会因为无法向新的 primary(在它的视角仍是 backup)写入数据而拒绝请求
- switch-over 的 commit point 是新的 primary 收到 vs 的任命状时
- 当 coordinator 收到 client 请求时 向 view server 询问当前的 primary
- vs 只负责记录 primary、维护心跳与选举 因此负载很低 不构成性能瓶颈
- vs 也可能会挂掉 因此需要多个 vs 保证可用性 此时引入 Paxos 算法保证一致性
Paxos (Single-Decree)
- Paxos 是一个分布式一致性算法 用于选举一个值
- Paxos 有三个角色(每个节点都可以同时扮演这三个角色)
- Proposer:提议者 提出一个提案
- Acceptor:接受者 接受提案 超过半数的 acceptor 接受了提案 则提案被接受
- Learner:学习者 达成统一后 发送结果给 client
- Paxos 的目标是所有的 acceptor 统一一个单值
- General Approach
- 一个 propose 决定变为 leader
- leader 提出一个提案的值 并从所有的 acceptor 那里得到接受
- leader 宣布结果
- Political Science 101
- Poxos 有轮次(round) 每一个轮次有一个 ID 称为 N
- 轮次是异步的
- 如果在 j 轮次中听到 j+1 轮次的消息 终止一切并转移到 j+1 轮
- 使用超时机制
- 每一个轮次有很多阶段(phase)
Paxos Phases
- Phase 0
- client 发送一个请求给所有的 proposer

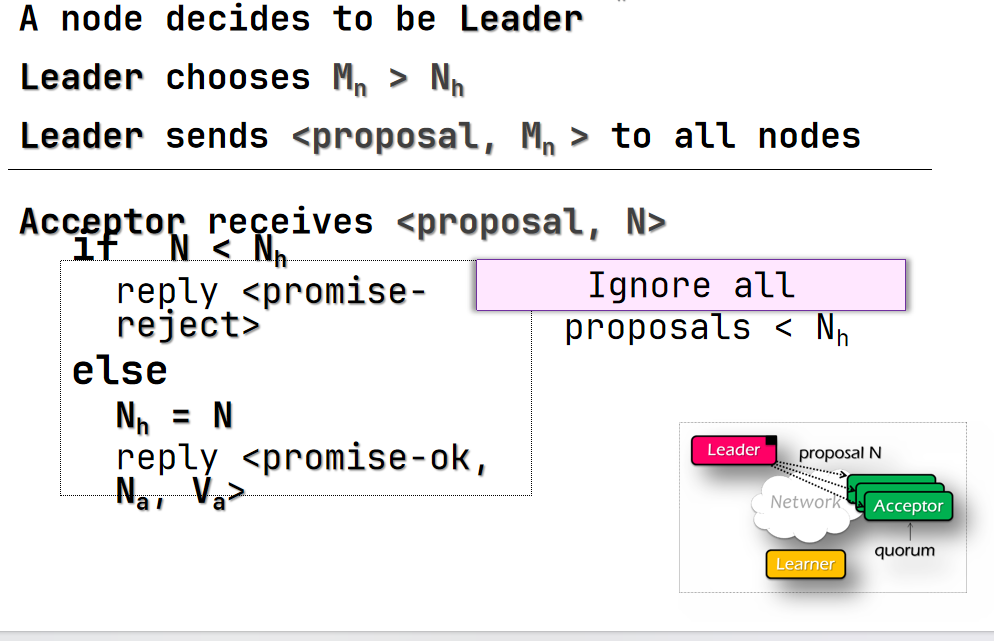
- Phase 1a(prepare)
- 一个节点决定成为 leader
- leader 创建一个 proposal N 发送给所有 acceptor 其中 N 必须比 leader 先前见过的所有轮次要大
- Phase 1b(prepare)
- acceptor 收到 proposal N 如果 N 大于等于它之前见过的所有 proposal
- 更新自己见过的最大轮次
- 回复 leader 之前accept过最大的 proposal
- 否则回复拒绝
- acceptor 收到 proposal N 如果 N 大于等于它之前见过的所有 proposal
- Phase 2a(accept)
- leader 收到至少半数的 ok 后(而不是 reject)
- 设置 proposal 的初始值(任意) 如果有任何返回的 proposal 值 用其中最大轮次的替换
- 发送给所有节点一个 accept request 带上 proposal
- 如果没有至少半数的 ok 则稍作 delay 后重试
- leader 收到至少半数的 ok 后(而不是 reject)
- Phase 2b(accept)
- acceptor 收到 accept 请求
- 如果轮次 N 大于等于它之前见过的所有轮次
- 更新自己见过的最大轮次、接受的最大轮次的 proposal
- 发送 accepted message 给 proposer 和 learner
- 否则拒绝
- 如果轮次 N 大于等于它之前见过的所有轮次
- acceptor 收到 accept 请求
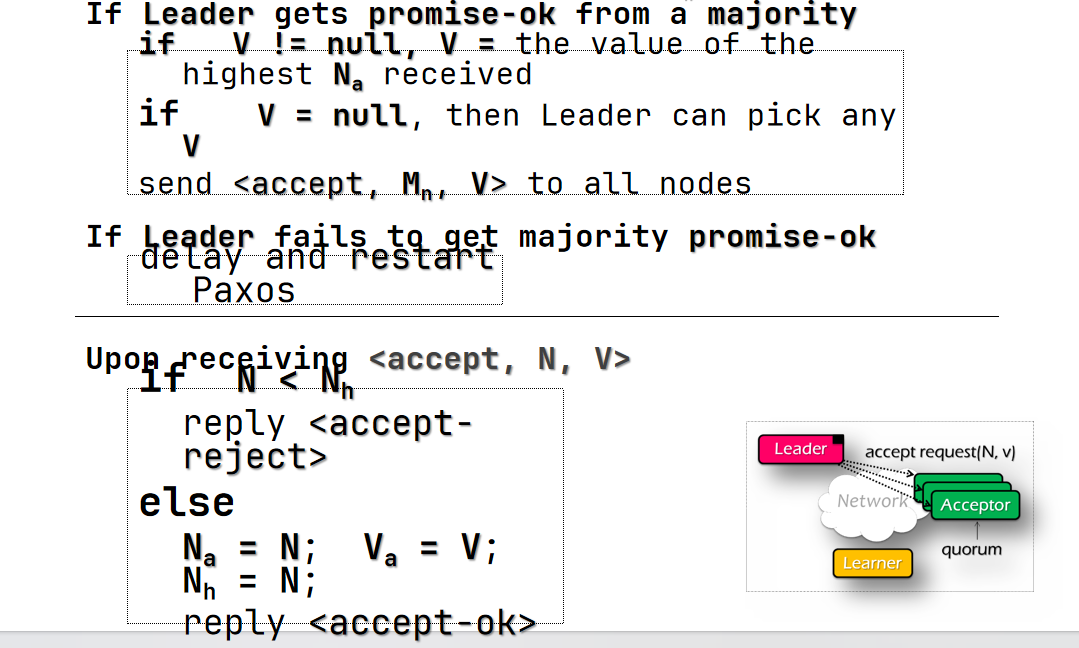
- Phase 3(learn?)
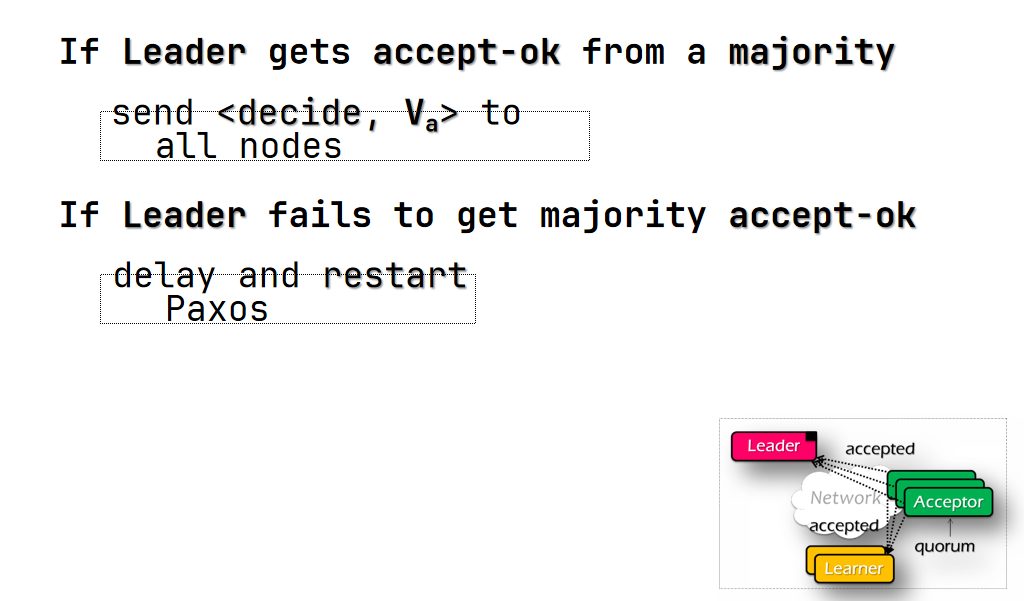
- leader 收到半数以上节点的 accepted message 把 decide message 发送给所有节点
- 否则稍作 delay 后重试
Inside of Paxos
- 为什么要多个 acceptor?
- 为了保证可用性 如果只有一个 acceptor 挂掉了 就会 halt
- 为什么不直接接受第一个 proposal?
- 有可能有多个 leader 同时提出了 proposal
- leader 可能在 decide 之前挂掉
- 为什么可以保证最终的一致?
- 不可能有两个 leader 可以同时看到半数以上的 accepted message
- 因此最终只有一个 leader 可以 decide
- 什么时候值真的被确认了?
- 当 leader 收到半数以上的 accepted message 时 此时半数以上的节点记录了这个 proposal 后续不可能无视掉这个 proposal
- 真正的时间点其实是在半数以上的节点收到了 accepted request 时 但是这个时间点对于系统来说是不可见的 因此选用后续的时间点
- acceptor 在发送 ok 后挂掉了怎么办?
- 需要在发送 ok 之前维护自己见过的最大轮次
- accpetor 在收到 accept request 后挂掉了怎么办?
- 需要立马维护自己见过的最大轮次和接受的最大轮次的 proposal
- leader 在发送 accept request 后挂掉了怎么办?
- 需要维护自己见过的最大轮次 并重新选举更大的轮次
- 上面三个状态都应该维护到 WAL 里 保证可以恢复
A extreme case for Paxos
假设现在有 10 个节点
节点 1 提出了一个 proposal <1, “hello”> 收到半数以上的 ok 后发送 accept request 发送完后立马挂掉
这个 accept request 只有节点 2 收到了
节点 3 提出了一个 proposal <2, “world”> 收到半数以上的 ok 后发送 accept request 不巧的是节点 3 和节点 2 间的网络断开了 因此节点 3 并不知道<1, “hello”> 这个 proposal 因此它可以发送 <2, “world”> 这个 proposal
以此类推 直到有半数的节点收到了 proposal 后 后续的 proposal 将必须从这 5 个 proposal 中选取
这个例子告诉我们 Paxos 不保证选举的成功 也不保证一定能选取出全局最新的 proposal 但是保证了最终一致性
Summary
- Paxos 在 RSM 中的应用:即每个 VS 是一个节点 需要选举出一个统一的 primary 和 backup 如果选举期间有节点挂掉 这个选举可能会一直进行下去 Paxos 不保证选举一定成功
- Single-Decree Paxos 只能产生一次决议 在 RSM 中 往往需要产生多个 View 因此需要 Multi-Paxos
Multi-Paxos
- Multi-Paxos 的实现非常简单 思路即一个 Paxos 负责一个决议
- 假设有 3 台 VS 我们只需要在每台 VS 上运行多个 Paxos 实例 每一个实例负责一个决议 就可以产生多个 View
- client 发送一个请求 选一个新的 Paxos 实例进行选举 如果发现最终决议不是自己的请求 则继续使用下一个 Paxos 实例进行选举
Problems
- Multi-Paxos 的性能很差 因为需要很多 RTT
- 最优情况下需要 2RTT
- 高并发场景下更糟糕
- 请求可能与其他服务器的数据有冲突 需要新建实例选举
- 可能同时有多个请求需要选举 导致多个轮次
- Solution
- 选取一个 leader 绝大部分时间都由这个 leader 来处理请求和 propose
- 这样还可以做到批处理请求 leader 可以一次性 prepare 之后的所有 proposal
- 注意这个 leader 不是必须的 用户发现 leader 挂掉后可以自己任选一个节点作为 leader 发送请求
- Hole in the log
- leader 在发送选举之前就挂掉 会导致本次决议为空
- 由于每个节点都有可能故障 Paxos 中的决议 sequence 是不连续的 会产生很多空洞
- Raft 会解决这个问题
Summary
- Multi-Paxos 基于 Single-Decree Paxos 产生一系列的决议 应用于 RSM 中
- Multi-Paxos 至今没有很好的实践 因为对于 programmer 来说不友好 需要应用自己解决很多问题