《计算机系统原理(研)》课程笔记
LEC 1: Distributed Storage: Sequential Consistency
Consistency Model
一致性模型是指一个存储系统在并发操作下如何处理同步和一致的约定
Strong Consistency
- 所有数据只有一个版本
- 读写等价于串行化的读写(线程之间的顺序可以不一样)
- 读写可以被视为一个从未 failed 的系统
- 根据等价于哪种串行化 分为:
- Strict Consistency:串行化顺序符合发生时间顺序 没有人实现这种模型 因为会有网络延迟的区别 机器的时钟不同步等问题
- Linearizability:如果 B 在 A 结束之后开始 串行化顺序中 B 一定在 A 之后
- Sequential Consistency:对于各个线程内的操作 保证串行化顺序和发生时间顺序一致 对于不同线程则不保证
Causal Consistency:对于有因果关系的操作 保证其顺序一致
Eventual Consistency:所有服务器的数据最终会达到一致
从上到下逐渐放宽一致性要求
如何实现 Linearizability?
- local property:如果一个数据的所有操作是线性化的 多个数据的操作组合也是线性化的
The simplest approach:centralized KVS
- 对于一个 server 客户端只需要把读写请求发送给这个 server 即可 记住在收到确认之前不能视为完成操作
- 假设接下来每个客户端需要有自己的 replica 我们采用 Primary-Backup model
- 对于每一个数据项 有一个指定的客户端作为 primary
- 对于写 primary 先转发给所有 replicas 全部写入后返回 最终在 primary 本地写入
- 为了防止 replicas 收到请求的顺序不一样 primary 会使用一个全局 counter 来为每一个 write request 加上 seq number replic 在收到前一个写之前不会执行后一个写
- 对于读 返回 primary 的数据 而不能读 replica 本地的数据 否则会产生在本地写入但是在 primary 未写入之前读取数据不一致的情况
- Drawbacks
- 读写需要额外的 RTT
- 一个 primary 会成为性能瓶颈和单点故障
- 这个模型的 backup 主要是为了容错 而不是提高性能 因此读写还是单节点的
- partitioning:把不同数据分区到不同的 primary 上 来解决只有一个 primary 导致的性能瓶颈问题
Drawbacks of linearizability
- 太慢 每一个操作都需要等待确认
- 单个 primary 会成为性能瓶颈和单点故障
- 难以提供 fault tolerance 因为 primary 一旦挂了就无法提供服务
LEC 2: Distributed Storage: Eventual Consistency
- Eventual Consistency:如果没有新的写入操作 那么所有服务器的数据最终会达到一致
- 实现 eventual consistency 是为了更高的性能
- READ:读取本地的最新数据
- WRITE:写入本地的数据 在后台异步地把写数据同步到其他服务器
如何实现 Eventual Consistency?
Write-write conflict
write-write conflict:两个不同的客户端同时写入同一个数据
linearizability 是悲观的解决方案 所有写入都会先在 primary 上确定顺序 于是先到的先写入
eventual consistency 是乐观的解决方案 先写入 之后再解决顺序问题 也正因此 读可能会读取到不一致的数据 但是最终会一致
通过 Ordered Update Log 来统一不同设备间的操作顺序 每个设备会把操作记录在自己的 log 里 同步时确保两台设备的 log 中顺序一致
同步时用什么确定 order?可以使用时间戳 如果时间戳一致则使用设备 ID
上述实现会在同步后才进行数据库的写入 然而为了用户体验 需要在本地数据库立马执行写入操作 然而如果这样做 当同步时 两个设备的初始状态是不同的 可以使用 Rollback and Replay 来解决这个问题
- 在 SYNC 前 设备把所有修改进行回滚 回到了初始状态 然后根据同步的 log 执行所有的操作 最终两台设备就会达到一致状态
- 时间一久 log 中的操作会非常多 导致回滚和重放的时间过长
- 解决方法是 checkpoint 即把 stable 的数据写入磁盘 然后截断 log 下面详细解释一下 checkpoint 的原理(使用的是 lamport clock):
- 设备 A 和设备 B 上一次同步时 如果同步得到的时间戳是 T 那么在同步之后发生的事件的时间戳一定大于 T 反之 小于等于 T 的事件一定在同步之前发生 也即一定被设备 B 所同步了
- 同理 对于设备 k 上一次同步的时间戳是 Tk 那么 Tk 之前的所有事件一定被 k 同步了
- 在设备 A 中维护一个 map 记录时间戳 Tk 时间戳小于 Tk 中最小值的事件 一定被其他所有设备同步了 也即 stable 的数据 可以写入磁盘
- 每一次和其他设备同步后 更新 Tk 集合 顺带更新了最小的 Tk 也就顺便把 stable 的数据落盘
synchoronized clock time
不同步的时间会导致用户体验异常 因此除了状态一致以外 还需要保证一些其他语义
Causal Ordering:在一台机器上 A 发生早于 B 或者是 A 触发了 B 的操作(比如 A 是添加数据 B 是删除数据)则 A 和 B 有因果关系
Lamport Clock:保证如果 A 是 B 的因 则 A 的时间戳小于 B 的时间戳 如果两个事件无因果关系(我们称其为并发事件) 则时间戳可能相等或无序
- 算法:
- 每个服务器保留一个时钟 T
- 随着时间的推移 T 会增加
- 收到一条消息的时间戳为 T’ 则更新 T 为 max(T,T’+1) 也即保证时间戳大于已经发生的事件
- 问题
- 时间戳可能相等 可以通过设备 ID 来解决
- 事件 A 发生在事件 B 之前 => A 的时间戳小于 B 的时间戳 但是反之不一定成立 因为每个设备的时间戳是独立的 换言之 没有办法确定 A 和 B 是因果关系还是并发事件
- 算法:
Vector Clock:用一个 n 维向量来表示时间戳 每个维度代表一个设备的时间戳 T[i]严格大于(即每个维度都大于)T[j] 则 i 发生在 j 之后 若无法比较 则是并发事件
算法:
- 若有 n 个设备 则每个设备有一个 n 维的向量代表时间戳
- 每个设备的时间戳初始时一样
- 设备 i 上 随着时间的推移 T[i] 自增
- 设备 i 向设备 j 发送消息时 把自己的时间戳 W 发送给对方 设备 j 把第 k 位时钟 更新为 max(V[k],W[k] + 1)
Summary
- scalability:仍有 primary 但是操作更轻量了
- 编程比较复杂
- fault tolerance:只要有一个设备存活就可以工作
LEC 3: Distributed Storage: All-or-nothing Atomicity
前面讲了两个一致性模型 是说系统如何处理并发操作来保证数据的一致性 然而面对各种 faults 这些模型将无法再保证数据的一致性 这就需要保证 atomicity 从而确保 faults 发生时数据不会出现不一致
Consistency under single-machine faults
- 任何调用都应该是 all-or-nothing 的 即要么全部成功 要么全部失败 否则会很难处理错误
- 以 bank transfer 为例 数据的一致性即保持账户总额不变
Achieving atomicity
Shadow Copy:保证对于一个文件的修改是原子的 通过写入一个新文件 然后重命名的方式来实现 因为重命名是原子的 虽然不会导致数据不一致 但是文件系统有可能会不一致
- Drawbacks
- 不支持并发 多个线程会同时写入一个原文件 导致覆盖
- 难以操作多文件 需要把所有文件放到一个目录下
- 拷贝开销大 即使只修改了一个字节也要拷贝整个文件
- Drawbacks
Journaling:上面的问题可以在 rename 之前写入 WAL 来解决 journaling 会导致极大的额外空间开销 所以可以只对 metadata 进行
- 通常磁盘会有一个电容 保证有足够的电力完成一个 sector 的写入
- 如果 journal 大于 sector size 怎么办?我们需要更通用的方法
Logging:可以见 AEA 事务笔记
REDO LOG
- logging 和 journaling 基本一致 不过 journaling 针对的是文件系统的细粒度操作 比如 rename
- 引入 transaction 的概念 一组原子性操作被称为事务
- 在准备操作前 写入 log 如何确保 log entry 是完整的?可以做一个 checksum
- redo-only logging’s pros & cons
- commit 很快速 只需要 append 操作到 log 中
- IO 利用率低 因为必须在事务提交时全部写入 log 如果在事务进行时就异步的写入 log 性能会更好
- 所有操作在提交之前需要缓存在内存中 万一内存不足就失败了
- log 无限增长 但是操作其实已经落盘了
UNDO LOG
- 为了解决 IO 和内存的问题 考虑在每一个操作后直接落盘 如果失败了需要全部回滚 因此引入了 undo log
UNDO-REDO
- undo 需要记录旧值 redo 需要记录新值 两者结合 每一个操作都记录新值和旧值 即可实现 undo-redo logging
- undo-redo 会记录每一个操作的 record 当系统调度不同事务时 可能不同的事务的 record 会交叉 因此需要一个指针来指向同事务的下一个 record
- record 的结构
- XID:事务 ID
- OID:操作 ID
- PTR:指向下一个 record
- VALUE:包括文件名、偏移量、旧值、新值
Put it together
- logging
- 每次操作前写入日志(WAL)
- 在 commit point 写入一个 commit record 到日志中
- recovery
- 从 end 遍历到 start
- 找到所有没有 commit 的事务 并添加 abort record
- undo 所有 abort 的事务 从后往前
- redo 所有 commit 的事务 从前往后
- logging
Problem:日志会无限增长 使用 checkpoint 来解决
- 等到没有任何操作在进行(而不是等到所有事务结束)
- 把 CKPT record 写入日志 CKPT 包括了所有当前正在进行的事务的 undo 和 redo 日志
- 把所有内存中的数据落盘
- 丢弃除了 CKPT 之外所有的日志
如何恢复?
- 如果 crash 时事务尚未提交 则应该保证事务回滚
- 如果事务在上一次 CKPT 后开始 则仅需 undo log
- 如果事务在上一次 CKPT 前开始 则需要 undo log 和 CKPT
- 如果 crash 时事务已经提交 则应该保证事务提交
- 如果事务在上一次 CKPT 前提交 不需要做任何事 因为 CKPT 内不会包含这个事务
- 如果事务在上一次 CKPT 后提交 且在 CKPT 后才开始 则需要 redo log
- 如果事务在上一次 CKPT 后提交 且在 CKPT 前就开始 则需要 redo log 和 CKPT
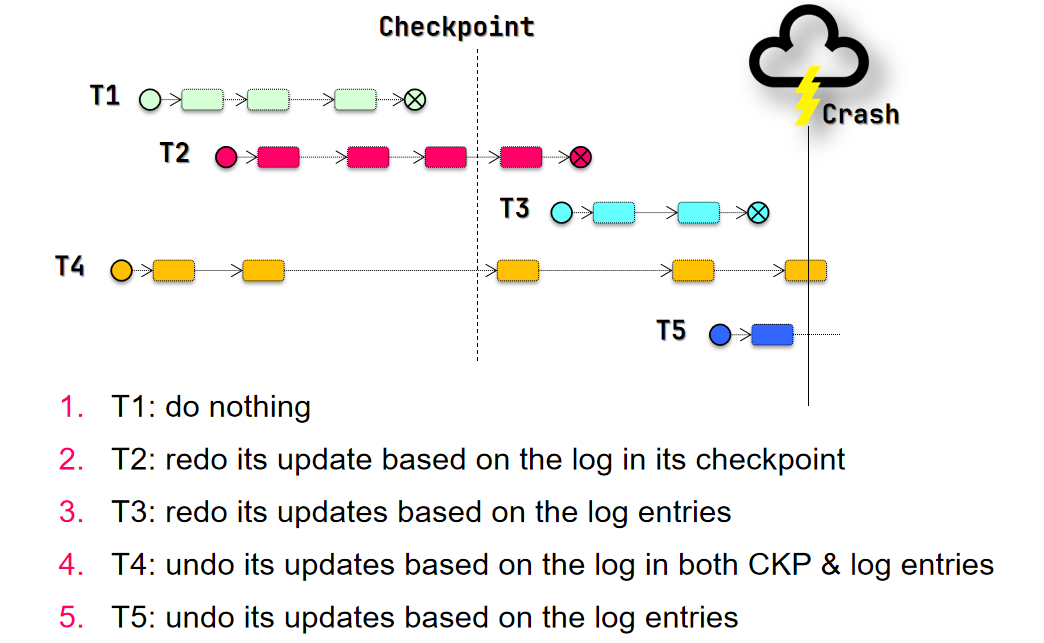
- 如果 crash 时事务尚未提交 则应该保证事务回滚
Undo-Redo vs Redo-Only vs Undo-Only
- REDO
- 更少的 IO 因为只需一半
- 更快的恢复 因为只需要从头到尾扫一遍
- 没有 UNDO 因此未提交的事务不得落盘 要求内存比较大 也就不适合事务太大 内存不够的情况
- UNDO
- 恢复快 和 REDO 一样
- 没有 REDO 因此提交的事务必须立马落盘 但是一个 page 可能包含多个事务的修改 这样就会重复落盘 很浪费性能;还有一种方法是每个操作都立马落盘 这样显然性能很差
- 由于上述原因 UNDO-ONLY 几乎不会用到
- UNDO-REDO
- IO 更多 是 REDO 的两倍
- 每条操作完了立马可以写入日志 IO 利用率比 REDO 高
- 恢复慢 要扫三遍
- REDO
Summary
- 保证原子性的方法
- shadow copy
- journaling
- logging
- Logging 同时也保证了 Durability 即一旦写入就不会丢失(因为可以 redo)
LEC 4: Distributed Storage: Multi-Site Atomicity
Transaction
事务是对于管理数据的一组操作的抽象 具有 ACID 特性
- Atomicity:要么全部成功 要么全部失败
- Consistency:事务只会将数据从一个一致状态转换到另一个一致状态 然而这个状态是人为定义的 应用层面也会打破一致性 因此数据库无法保证 consistency
- Isolation:事务之间是隔离的 两个事务的并发一定可以串行化
- Durability:事务一旦提交 数据就会持久化
Summary
- A 与 D 用 log 来保证
- I 用 2PL、OCC、MVCC 来保证 同时还有 HTM 在硬件上实现 OCC 的思路
Multi-Site atomicity
- 当数据分布在多个 site 时 单机的原子性将不再适用 比如一个事务涉及到多个 site 的数据 在其中某一个 site 上发生了故障 则这个事务就无法保证原子性
- 如何保证分布式的原子性 即 Multi-Site Atomicity
2PC(Two-Phase Commit)
事务也应该是模块化的 一个大事务可以分解为多个小事务 小事务仍不失去原子性 在分布式架构下 可以把每一个 site 上的操作看作一个小事务 把统筹各个 site 小事务的操作看作一个大事务
2PC 大体思路
- Prepare Phase
- 将小事务的 commit 延迟
- 小事务要么 abort 要么 tentatively commit
- 大事务来评估小事务的结果
- Commit Phase
- 大事务决定小事务是否真正 commit:如果有至少一个小事务 abort 则大事务也 abort 否则 commit
- Prepare Phase
Logging in 2PC
- 分布式下 小事务执行到 commit point 时 只能保证自己的 Durability 无法保证其他事务的 因此无法真正提交
- 整个过程中只有 coordinator 是可以保证所有事务的 Durability 的 因此只有 coordinator 可以决定 commit 与否
- 小事务(worker)
- REDO-UNDO:保持不变
- commit record 需要改为 prepared record
- 记录需要带有大事务的 reference
- 当 failure 时 向 coordinator 询问是否 commit
- 大事务(coordinator)
- 有一个 prepare log 记录大事务是 commit 还是 abort
Challenge:unreliaible communication、coordinator & worker
Problem:如果小事务的日志是完好的 但是大事务的日志还未写入 没法判断是否 commit
Solution
- 听从 coordinator 的决定 如果大事务没有 record coordinator 可以向各个 worker 查看是否 prepared 如果都 prepared 则 commit 否则 abort
- worker 不能自己决定 必须向 coordinator 询问 确定了 commit 后 就可以把 prepared record 改为 commit record
本质上就是 小事务一旦处于 prepared 状态(也就是原来的 commit 状态)就意味着小事务已经保证了 A 和 D(原子性和持久性) 一旦所有小事务都处于 prepared 状态 大事务就保证了 A 和 D 因此就可以 commit
coordinator 给小事务发送 commit 的目的并非让小事务保证 A 和 D 而是让小事务把 prepared 改为 commit 从而可以继续下一个事务
Summary
- coordinator 需要记录每个小事务的 prepare 状态吗?不是必须的 反而会带来额外的开销
- 记住 logging 的最小化才是性能的关键
- 还剩一个问题:如何做 CKPT?
- 小事务的 CKPT 仍然一致 只要 commit 了就可以清除
- 大事务的 CKPT 会遇到新问题:worker 仍有可能询问这个 commit 什么时候才可以真正清除呢?
- 也很简单 coordinator 在异步发送 commit 给 worker 后 后台会收到每一个 worker 的 ack 等到所有 ack 都收到后再清除这个 commit
2PL & OCC in 2PC
- 2PL:给小事务上锁就能保证 Isoaltion 只需要每一个小事务直到大事务决定 commit 后才释放锁即可
- OCC:prepare 阶段和 OCC 的 validation 相结合 coordinator 除了询问 worker 是否 prepared 还需要 validate 是否有冲突 如果有冲突则 abort 否则 commit
Summary
- 2PC 保证了 Multi-Site Atomicity
- 2PC 只保证了 Consistency 通过 Replication 可以保证 Availability 与 Partition Tolerance
- 然而一旦 coordinator 挂了 系统的可用性将被破坏 下节课将讨论如何解决这个问题
LEC 5: Distributed Storage: Replication & Consensus (Paxos)
- Replication 可以提高性能和延迟(比如前端) 也可以提高可用性
- Replication Consistency
- Optimistic Replication:允许数据不一致 但是最终会一致
- Pessemistic Replication:保证 strong consistency
Pessemistic Replication
- 悲观复制意味着更低的可用性和性能 但是所有操作都可以被视为在一个 single copy 上执行的 用户将感知不到多个 replica 的存在 这和乐观复制不同
RSM(Replicated State Machine)
- 所有 replica 都可以被视为一个状态机 只需要保证输入和顺序一致 那么输出也一定一致 真正的关键在于请求的顺序如何保持一致
- RSM 可以使用之前提到的 primary-backup 模型实现 我们知道 primary-backup 模型最大的问题在于 primary 的单点故障导致可用性被破坏 下面我们会看到如何使用 View Server 和 Coordinator 来解决这个问题
- Coordinator
- 所有客户端的请求发送给 coordinator
- coordinator 会把请求转发给 primary
- 出现 multiple coordinators 时 会出现问题 因此引入了 view server
- View Server
- 管理 primary 和 backup 的选举 记录谁是 primary 谁是 backup
- 每个 replica 向 view server 进行心跳 维护每个节点的健康状态 当 primary 挂掉时 view server 会选举一个 backup 作为新的 primary 并找到空闲的 replica 作为新的 backup
- 新的 primary 收到 vs 发送的任命状之前会拒绝所有 coordinator 的请求 此时旧的 primary 仍可以正常处理请求
- 新的 primary 收到任命状后会开始处理请求 旧的 primary 如果收到 coordinator 的请求 会因为无法向新的 primary(在它的视角仍是 backup)写入数据而拒绝请求
- switch-over 的 commit point 是新的 primary 收到 vs 的任命状时
- 当 coordinator 收到 client 请求时 向 view server 询问当前的 primary
- vs 只负责记录 primary、维护心跳与选举 因此负载很低 不构成性能瓶颈
- vs 也可能会挂掉 因此需要多个 vs 保证可用性 此时引入 Paxos 算法保证一致性
LEC 6: RDMA (Remote Direct Memory Access)
- 分布式训练的规模越来越大 其对于通信带宽和延迟的要求也越来越高 RDMA 技术可以有效降低这些开销
- 传统的网络通信具有非常复杂的软件实现 导致软件开销非常大 成为了通信带宽和延迟的主要瓶颈
- DPDK(Data Plane Development Kit)是一套用于快速数据包处理的开源软件库和驱动程序 通过绕过内核网络栈直接与网络接口卡(NIC)进行交互 来实现高性能的数据包处理
- Pros:绕过内核;减少了 memcpy 开销;用户可以自定义网络;
- Cons:与传统网络通信不适配;用户应用仍然需要一个适配层(因为没有 TCP/IP 协议层了)
- RDMA 的工作原理
- RDMA 允许直接从一个计算机的内存访问另一个计算机的内存而无需经过操作系统的干预
- 这通过使用特殊的网络接口卡(NIC)和协议来实现
- RDMA 可以显著降低延迟和提高带宽利用率
- RDMA 有三种主流实现
- IB(InfiniBand)
- RoCE(RDMA over Converged Ethernet)
- iWARP(Internet Wide Area RDMA Protocol)
- QP(Queue Pair)是 RDMA 的基本通信单元 由 Send Queue、Complete Queue、Receive Queue 组成
- RDMA 发送消息的流程
- 注册一个 msg buffer 用于接收回复的消息 接口是
ibv_post_recv - 发送消息 接口是
ibv_post_send - 轮询 直到消息已发送 把消息放入 CQ
- 网卡把 ack 放入完成队列 用接口
ibv_poll_cq进行轮询 确认消息已经发送 - 对方通过接口
ibv_poll_cq进行轮询 接受到接收队列里的消息
- 注册一个 msg buffer 用于接收回复的消息 接口是
- RDMA 使用了 MMIO 和 DMA 技术
- MMIO(Memory-Mapped I/O):通过将设备寄存器映射到虚拟内存地址空间来实现设备与内存之间的直接访问
- DMA(Direct Memory Access):允许设备直接访问系统内存而无需经过 CPU
- RDMA vs. DPDK
- 都是绕过内核
- RDMA 的硬件适配性更强 并且是零拷贝(即不需要额外的内存拷贝)
- DPDK 更灵活 支持自定义网络协议
- CPU 性能已经达到瓶颈 而网卡性能仍能保持增长(因为网络通信的并行化非常容易实现)对于双边 RDMA 接收方的 CPU 需要轮询处理响应 一直处于满载状态 对于散热和能耗都是一个挑战 因此设计了 One Sided RDMA 消除了接收方的 CPU 性能瓶颈
- One Sided RDMA
- One Sided RDMA 允许一个节点直接读写另一个节点的内存而无需对方的参与
- 这通过 RDMA 的注册和权限机制来实现 接收方会通过 MR(Memory Registration)来注册自己的内存区域并授予对方访问权限 从而防止不安全的篡改
- One Sided RDMA 可以显著降低延迟并提高带宽利用率
- One-sided vs. Two-sided RDMA
- One-sided 能耗低 理论性能高 绕过了 CPU 但是扩展性差 offloading 语义差
- Two-sided RDMA 易编程 扩展性强 但是性能较低 CPU 开销高
- One-sided RDMA 在 KV-store 中应用 与传统的网络通信不同 传统网络通信访问桶哈希 只需要 cpu 在内存中遍历链表即可 但是对于 RDMA 而言 这样的遍历只能转换为一次次的网络请求 这就导致性能下降 因此需要引入 Cuckoo Hashing 来解决这个问题 其可以保证 O(1)的查找性能
- RDMA 也需要解决 race condition 通常可以模仿 OCC 的做法 用 checksum 等机制来验证是否出现 race condition
- RDMA 的操作过于底层 因此在功能实现上有所限制 因此我们可以用 SmartNIC 来进行功能扩展
LEC 7: SmartNIC
- Types
- On-path:数据必须经过处理核心
- Off-path:数据可以绕过处理核心
- SmartNIC 是一种智能网络接口卡 其内置了处理器和存储器 可以在硬件层面上实现一些网络功能
- SmartNIC 的优势
- 减少 CPU 的负担 将一些网络处理任务 offload 到 SmartNIC 上
- 提高网络性能 SmartNIC 可以并行处理多个网络连接
- 灵活性高 用户可以根据需求编程 SmartNIC 的功能
- SmartNIC 的应用场景
- 数据中心网络 加速虚拟化和容器化应用
- 边缘计算 处理 IoT 设备产生的数据
- 云服务 提供高性能的网络服务
LEC 8: System Virtualization
- System Virtualization 是一种将物理资源抽象为虚拟资源的技术
- VMM(Virtual Machine Monitor)是实现虚拟化的关键组件 分为两类
- Type 1 VMM(裸机虚拟机监控器):直接运行在物理硬件上
- Type 2 VMM(托管虚拟机监控器):运行在宿主操作系统上(现在的主流虚拟化技术)
CPU Virtualization
- OS 没有办法直接作为一个应用运行在另一个 OS 上的原因是其需要运行很多特权指令 而这些指令在用户态被禁止 通过 Trap & Emulate 可以缓解这个问题 其会捕捉这些特权指令 并将其转换为其他可行操作 但是并非所有特权指令都可以通过这个方式解决 这样的指令有 17 条
- 这 17 条指令可以用其它方法处理 包括:
- 写一个指令解释器 用软件去解释并 emulate 指令
- 对二进制源码进行翻译 把这些指令转换为其他操作 比如 VMware 会把这些指令翻译为 func call
- 在源码中手动替换这些指令 换句话说 就是修改虚拟机OS的逻辑
- 上面 3 种方案都是软件支持 把虚拟机运行在了用户态进程 而使用新的硬件改变 CPU 逻辑 也就是 CPU 虚拟化 也可以解决问题 具体而言 CPU 会加一层权限 原本的 ring-0 和 ring-3 会增加 root 和 non-root 模式 原本的 os 在 root 下 而虚拟 os 则在 non-root 下 从而可以把上面的 17 条指令也进行转换
Memory Virtualization
- 内存虚拟化是指将物理内存资源抽象为多个虚拟内存空间供虚拟机使用
- Solution
- Shadow Page Table:host 为每个虚拟机维护一个影子页表 每个虚拟机内部维护自己的页表 但是不使用 host 会动态的将虚拟机内部的页表和 host 的页表进行映射的合并 从而生成一个最终的影子页表 可以直接被 CPU 使用
- Direct Paging:修改虚拟机 OS 的逻辑 直接把真实的内存地址告诉虚拟机 虚拟机直接建立从真实地址到自己的虚拟地址的页表映射 性能更好 但是虚拟机知道更多 host 的信息 存在安全问题
- 硬件支持:在 CPU 中加入新的页表 用于存放虚拟机的页表映射信息
- Trade-off(会考)
- SPT
- 对虚拟机完全透明/无需修改客户机 OS/兼容性好
- 内存开销大:需维护多套页表副本/管理复杂:需捕获客户机页表更新并同步/切换开销大:每次上下文切换需刷新 TLB
- DP
- 性能高/减少陷入和影子页表维护开销/内存效率高
- 需修改客户机 OS/破坏透明性/安全性风险:虚拟机知晓部分宿主机物理布局
- HARDWARE
- 性能最佳/对客户机透明/硬件自动完成两级转换,几乎无软件开销
- 依赖 CPU 硬件支持/早期实现有性能开销(EPT Miss 等)
- SPT
I/O Virtualization
- I/O 虚拟化是指将物理 I/O 设备抽象为多个虚拟 I/O 设备供虚拟机使用
- Solution
- Direct access:让虚拟机直接使用 IO 设备 但是虚拟机太多设备就不够用 性能好 但是隔离性差 可能绕过MMU直接访问内存 存在安全问题
- Device emulation:用软件实现设备逻辑 可以模拟不存在的设备 比如 VMware会直接用软件写一个8139网卡的逻辑 和虚拟机的网卡驱动对接 非常稳定但是性能差
- Para-virtualization:修改虚拟机的OS 在虚拟机运行一个前端驱动 这个前端驱动对接host里的后端驱动 然后驱动可以操作真实设备
- Hardware-assisted virtualization:在硬件设备上支持虚拟化 比如硬件本身支持虚拟化为多个设备
LEC 9: Distributed Computing: Intro
- 人工智能的发展导致需要大量的计算资源 也就必须得扩展为分布式计算
- AI 训练计算所需要的性能是非常好计算的
- 一个神经网络层 W 是 m*k 的矩阵 X 是 k*B 的矩阵 B 为 batch size k 为输入维度 m 为输出维度 那么计算 W*X 的时间复杂度为 (2k-1)*m*B
- backward path(反向传播)需要计算 dW 和 dX 时间复杂度为(2m-1)*k*B 和(2B-1)*k*m 都可以约为 2*参数数量*Batch Size
- 最终的结论就是 AI 模型训练总的时间复杂度为 6*参数数量*Batch Size
- 对于 GPT 来说 有 1.76trillion 个参数 一张 A100 显卡的性能是 19.5TFLOPS 那么训练一个 GPT 需要 30s 进行一次迭代 非常的耗时
- 我们最终的目的是使用足够的算力进行分布式训练 接下来将先从单个计算设备开始讲起
Computing Device
CPU
- 单核 CPU 系统 算力上限取决于 Clock Rate 一个时钟周期最多做一次指令 (当然也有使用 pipeline 和超标量的方法来提高单核的算力)然而硬件的主频基本上因为散热问题已经到了极限
- 多核 CPU 系统 算力上限取决于核心数 然而和分布式类似 多核需要应对的问题是 cache 中的 coherence 问题
- 另一种类似多核的方法是增加每个核的 ALU 数量 即 SIMD(Single Instruction Multiple Data)的思想 一条指令处理多个数据
- 需要新的指令集(比如 Intel 的 AVX)增加了代码的复杂度
- 性能增益不可能达到理论的倍增 因为指令可能有依赖
- 有时候访存也会成为性能瓶颈 访存的时间 = Latency + Payload / Bandwidth
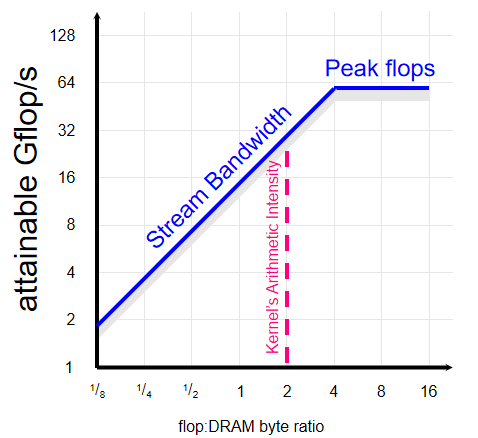
- Roofline Model:刻画算力与带宽的关系图 y 轴是算力 单位是 GFLOP/s 即每秒多少次浮点运算 x 轴是应用利用内存的效率 单位是 Flop/Byte 即读取一个字节数据可以进行多少次运算 于是斜率就是应用对于带宽的需求 单位为 Byte/s 于是设备在图中表示为两条线 一条代表算力的水平线与一条代表带宽的斜线 应用的 OI(Operational Intensity)所落在哪条线 就说明哪个因素是瓶颈
GPU
- 也是两种方式提升算力:增加核心数和 SIMD
- GPU 的 ALU 数量远远多于 CPU 因为 GPU 没有 cache coherence
- SIMD 难以实现分支条件 但是可以通过 mask 来实现 也就是执行所有分支 但是写回的数据会用条件的 mask 来选择 不过还是会造成很多无用的计算 而且编程变得很复杂
- 于是 NVIDIA 实现了 SIMT(Single Instruction Multiple Threads):(没听懂 说是超纲了)应该就是相当于用户指定某一个线程执行某一个任务 比如指定第 i 个线程执行第 i 位的相加
TPU
- Tensor Core:专门用于矩阵运算的核心 替换掉了原来的 ALU 用于加速矩阵运算
- TPUs(Tensor Processing Units):谷歌的专门用于矩阵运算的芯片
Summary
- 单个设备的算力由于种种限制没法无限提高(比如主频是因为散热问题 多核是因为芯片面积问题等)连老黄的显卡的提升也只是因为使用了 tensor core 或是增加了核心数
- 于是就需要分布式计算来提高算力 大部分情况下使用一个开源的分布式计算框架足以 接下来我们介绍一个经典的分布式计算框架:MapReduce
LEC 10: Distributed Computing: FlashAttention
- 矩阵计算的代码可以优化逻辑来加速 首先是交换循环顺序 然后还可以进行 tiling
LEC 11: Distributed Computing: Distributed Training
- 接下来我们终于到达了目的地:分布式训练 下面介绍一下如何使用计算图来进行分布式训练
- 以所有 AI 模型训练都会用到的梯度下降法为例 可以看到求权重的下一次迭代可以表示为如下的计算图 其中 x 是输入 y 是 label w 是当前权重 最终计算出 dw 来更新权重
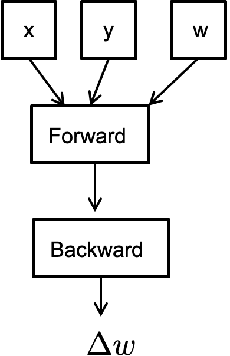
- 为了分布式训练 我们需要考虑如何实现这个计算的并行化 接下来介绍几种常用的并行化方法
Data Parallelism
- 即将数据的 batch 划分为更小的部分 分别计算 最后再汇总 比如上图的累加操作
- 第一个问题是 同步的方法导致必须等待所有节点计算完毕才能进行下一次迭代 也就会有某些节点拖累整体性能 这个只能通过异步的方法来解决
- 第二个问题是 被称为 all-reduce 的汇总操作 往往需要巨大的通信与计算开销 比如累加操作中的 sum 操作 其开销决定了整个计算的性能
- 在 all-reduce 中主要的开销是通信开销而并非计算开销 减少通信开销的方法包括减少通信量与减少并发通信 下面是业界常用的几种方法
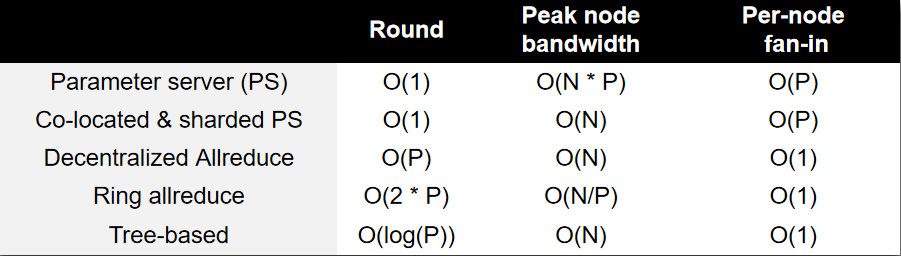
- Parameter Server
- PS 负责接受所有节点的参数并进行 reduce 然后再广播回所有节点
- 假设 N 是节点的数量 P 是参数的数量 那么 PS 需要 1 轮通信 节点的 fan-in 是 O(N) 通信量是 O(N*P)
- 这意味着随着节点的拓展通信量会线性增加 并且需要应对高并发问题
- Co-located & Sharded PS
- 进行 sharding 一个节点只负责一部分参数的 reduce 仍然只需要 1 轮 每个节点的通信量变为 O(P) 与节点数量无关
- high fan-in 问题:每个节点仍需要收到 O(N) 个节点的请求 还是存在高并发问题
- Decentralized Allreduce
- 所有节点串行的发送参数 减少了并发请求 通信量仍然是 O(N * P) 需要的轮数是 O(N^2) 有 O(1)的 fan-in
- 如果 1 给 0 发的同时 2 给 1 发 3 给 2 发 则可以减少轮数为 O(N)
- Ring Allreduce
- 节点的通信形成一个环 即 0->1->2->3 最终节点 3 进行 reduce 并广播
- 结合 sharding 后 看起来就像是每一轮每个节点都会接受上一个节点的参数 并发送参数给下一个节点 最终在 N 轮内结束 注意参数最远只需要走 N-1 步 所以所有参数肯定可以到达目的地
- 同理 广播也可以通过一轮环路通信来实现
- 每个节点的通信量是 O(P) 通信轮数是 O(2*N) 但是每个节点只需要同时处理两个节点的请求 这就是牺牲了网络延迟来换取了低并发
- 这个方法会导致每个参数的 reduce 顺序不一样 如果计算不满足交换律则会导致结果不一样(比如浮点数的加法)
- Tree Allreduce
- 不断二分 reduce 的方法 即每个节点负责两个子节点的 reduce 最终汇总到根节点上 最终再进行广播
- 每个节点的通信量是 O(P) 通信轮数是 O(logN) fan-in 为 3(父节点和两个子节点)
- 然而负载并不均衡(叶与根 fan-in 更少)于是使用 Double Binary Tree Allreduce 将二叉树进行翻转 保证负载均衡
- Parameter Server
Model Parallelism
- 可以看到 Data Parallelism 要求一个节点必须存储所有的参数 然而目前模型的参数量太大 往往一个节点存不下
- 因此考虑把模型的不同层或者每一层的不同参数分配到不同的节点上(水平或垂直切分)也就是 Pipeline Parallelism 与 Tensor Parallelism
- Pipeline Parallelism
- 即把模型的每一层放到不同节点 之所以称为 Pipeline 是因为节点之间有依赖关系 上一层计算完了才能计算下一层
- Pipeline 最大的性能问题是 bubble 即空闲时间
- 通过把 batch 进一步划分为多个 micro-batch 可以减少 pipeline 的 bubble(空闲时间)因为节点可以更早的获取上一层的结果
- 理想情况下 bubble size 是 p-1 而减少的倍数是 (p-1)/m 其中 p 为 partition 的个数 m 为 micro-batch 的数量
- 要想减少 bubble 需要增加 m 或者减少 p
- 增加 m 会导致 batch 太小 GPU 性能下降
- 那么只能相对的增大 batch size 然而这会影响模型的收敛
- p 也不能无限制减少 因为我们切分模型就是为了减少单个节点的参数量 模型的参数量也就限制了 p 的最小值
- Tensor Parallelism
- 由于参数量限制了 p 我们可以考虑把一层进一步划分为多个子矩阵 分配给不同的节点 这样多个节点就可以存储一层 p 也就可以进一步减少了
- 原理很简单 即矩阵乘法可以分解为多个子矩阵的乘法
- 由于在计算了一整个矩阵乘法后 需要汇总成完整的矩阵 因此会有额外的网络通信开销 导致其通信量比 Pipeline Parallelism 更大
- Summary
- Pipeline Parallelism
- 网络通信少
- 有 Bubble
- Tensor Parallelism
- 支持参数多的大模型
- 网络通信多
- Pipeline Parallelism