《机器学习》课程笔记
L1 - 机器学习概述
WHAT IS ML?
- 从数据(数据集)中学习规律(模型) 不断优化性能(优化算法)以实现目标(损失函数)的算法
- Data:用于训练和测试模型的数据
- Model:用于从数据中学习规律的算法
- Loss Function:用于衡量模型预测与真实值之间的差距的函数
- Optimizer:用于根据损失函数的梯度来更新模型参数的算法
- 流程:数据收集 → 数据预处理 → 特征提取 → 模型选择 → 模型训练 → 模型验证 → 模型预测 → 模型评估
AI vs ML vs DL
- AI>ML>DL 机器学习是需要从样例中学习数据规律的技术 而深度学习则是其中自动学习特征的一种方法
分类
- 监督学习:每个输入样本都有一个标签 比如分类问题、回归问题
- 无监督学习:没有标签的数据集 比如聚类问题、降维问题
- 强化学习:通过与环境交互来学习 环境包括奖励和惩罚等机制 目标是最大化长期奖励
泛化性
- 泛化性是指模型对未知数据的适应能力 比如一个分类模型是否能处理未见过的数据
- 过拟合:模型在训练集上表现很好 但在测试集上表现很差 通常是因为模型把训练数据的噪声因素也一并学习 相当于只会背题的学生 泛化性差
- 措施
- 数据划分:训练集(训练权重参数)、验证集(确定超参和模型)、测试集(评估最终模型性能) 其中验证集和测试集不能重叠
- 交叉验证:K 折交叉验证 即每份数据集轮流作为验证集 解决数据量不足的问题
- 早停:出现过拟合迹象时及时停止训练(即训练损失下降 但是验证损失上升)
- 正则化:对参数增加惩罚项 限制模型的复杂度
- 措施
- 欠拟合:模型在训练集和测试集上表现都很差 通常是因为模型太简单 无法拟合数据的复杂性 相当于智商不够的学生 泛化性差
L2 - 线性回归
- 线性回归是一种用于预测连续值的监督学习算法
模型结构
- 数据格式:x 是输入向量 y 是目标值(连续变量)
- 模型假设:y = wx + b + ϵ 其中 w 是权重 x 是输入 b 是偏置 ϵ 是噪声
- 训练过程:根据误差来调整 w 和 b
- 预测过程:根据新输入的 x 来预测 y
- 损失函数:均方误差(MSE)是最常用的损失函数 即预测值与真实值的差的平方的均值
- 优化方法:梯度下降是最常用的优化方法 即根据损失函数的梯度来调整参数
- 解析解:w = (X^T X)^-1 X^T y 其中 X 是输入矩阵 y 是输出向量
- 正则化:存在矩阵 X^T X 不可逆的情况 可以通过正则化来解决 只需要为损失函数增加正则化项 λ/2 ||w||^2 此时解析解变为 w* = (X^T X + λI)^-1 X^T y 保证矩阵可逆
L3 - 决策树
- 分类问题是一种用于预测离散值的监督学习算法 包括决策树、随机森林等
决策树
- 数据的分布可能是非线性的 但是沿着某些维度局部线性可分 决策树通过递归对子问题进行线性划分来实现分类问题
模型结构
- 基本结构:根节点、内部节点、叶节点 其中叶节点代表类别 非叶结点代表特征判断条件
- 训练过程(递归构造决策树)
- 构造根节点 代表整个数据集
- 选择一个最合适的特征进行划分
- 根据特征将数据集划分为若干子集
- 创建子节点代表子集数据
- 递归进行 2-4 直到满足停止条件(包括叶子节点都属于同一类、叶子节点样本数量太小、没有更多特征可用(ID3))
- 优化算法(如何选择决策特征)
- ID3:基于信息增益 即选择能够最大程度降低信息熵的特征 每一轮遍历所有特征 计算信息增益 注意特征分界值通常选择中位数或是平均值 离散特征一般不重复使用 连续特征则可以
- 信息熵:H = -∑(p_i log(p_i)) 其中 p_i 是第 i 类的概率
- 信息增益:IG = H(S) - ∑(|S_i|/|S| * H(S_i)) 其中 S 是数据集 S_i 是划分后的子集
- CART:基于基尼指数
- C4.5:基于信息增益比
- ID3:基于信息增益 即选择能够最大程度降低信息熵的特征 每一轮遍历所有特征 计算信息增益 注意特征分界值通常选择中位数或是平均值 离散特征一般不重复使用 连续特征则可以
- 优点
- 简单直观 易于理解 可视化性强
- 预处理要求低 可以处理缺失值
- 可以处理非线性边界
- 数据驱动 可以任意精度拟合数据集
- 缺点
- 容易过拟合 会把噪声数据划分为一个叶子节点
- 为了解决过拟合问题 下面介绍随机森林
随机森林
- 基本思想:对数据有放回的抽样 形成 T 个子集 分别训练决策树 最后通过投票来决定最终分类结果 由于噪声数据最多只会影响一个决策树 因此不会影响最终的分类结果
- 优点
- 比决策树更准确
- 训练并行化 速度快
- 可以处理高维数据
- 可以处理缺失值
- 结果可解释性强
- 可以检测特征之间的相关性
- 对于不平衡数据集效果好 可以平衡误差
L4 - 朴素贝叶斯分类
- 核心思想:假设数据基于独立同分布的特征采样 从而计算样本的后验概率来写预测标签 Y
- 基本概念
- 先验概率:P(Y) 代表样本属于某一类的概率
- 后验概率:P(Y|X) 代表样本 X 属于某一类的概率
- 似然:P(X|Y) 代表样本 X 在已知类别 Y 的情况下的概率
- 证据:P(X) 代表样本 X 的概率
- 贝叶斯定理(规则):P(Y|X) = P(X|Y) * P(Y) / P(X) 其中 P(X) = ∑(P(X|Y) * P(Y)) 是所有类别的似然和
- 计算后验概率时 需要提取很多特征的联合概率分布 为了简化计算 引入了朴素贝叶斯假设 即 P(Xi,Xj|Y) = P(Xi|Y) * P(Xj|Y)
- 一旦某一特征 X 的概率为 0 那么整个后验概率就为 0 为了解决这个问题 引入了拉普拉斯平滑 即 P(X_i|Y) = (count(X_i, Y) + 1) / (count(Y) + |X|) 其中 |X| 是特征的取值个数 这样就可以避免概率为 0 的情况
- 训练过程:(以垃圾邮件分类为例)
- 计算每个分类的先验概率 比如 P(垃圾邮件) = 0.1 P(非垃圾邮件) = 0.9
- 根据训练集统计出每个特征的条件概率 比如 P(“免费”|垃圾邮件) = 0.8 P(“免费”|非垃圾邮件) = 0.1
- 对于一个新样本 根据贝叶斯定理计算后验概率 比如 P(垃圾邮件|“免费” “优惠”) = 0.2 P(非垃圾邮件|“免费” “优惠”) = 0.3 取概率最大的类别作为预测结果 即非垃圾邮件
- 优点
- 非常快速 文本分类效果好
- 当 iid 假设成立时 效果很好
- 维护简单 只需要更新先验概率和条件概率即可
- 缺点
- 假设过于简单 可能导致欠拟合
- Case:



L5 - KNN
- 基本思想:通过计算新样本与训练集中所有样本的距离 来找到与新样本最近的 k 个样本 然后根据这 k 个样本的类别来预测新样本的类别
- 距离计算:常用的距离计算方法有欧氏距离 曼哈顿距离 闵可夫斯基距离 余弦相似度等
- 算法过程
- 预处理数据 包括归一化或标准化 其中归一化可以用 Min-Max 标准化可以用 Z-Score
- Min-Max 归一化:将数据缩放到 [0, 1] 之间 X’ = (X - min(X)) / (max(X) - min(X))
- Z-Score 标准化:将数据转换为均值为 0 方差为 1 的分布 X’ = (X - mean(X)) / std(X)
- 计算新样本与训练集中所有样本的距离
- 找到与新样本最近的 k 个样本
- 根据这 k 个样本的类别来预测新样本的类别
- K 的选择
- 维诺图:将区域划分为不同的类别区域 使得每个区域的点到其种子点的距离最小
- 当 K 较小时 容易受到噪声的影响 会导致过拟合 边界过于复杂
- 当 K 较大时 容易受到样本不均衡的影响 会导致欠拟合 边界过于平滑
- K 合适时 分界线比较平滑
- 优点
- 简单直观 易于理解
- 无需训练
- 缺点
- 数据量太大时计算量大
- 数据维度太高时效果不好
L6 - 逻辑回归
- 逻辑回归是一种用于二分类问题的监督学习算法 虽然名字中有“回归”二字 但实际上是一种分类算法
感知机
- 模型假设:g(x) = w1x1 + w2x2 + w0 g(x)大于和小于 0 分别代表两个类别
- 训练过程:对于每一个数据 如果分类正确 则不做任何操作 如果分类错误 则 w’ = w + ηyx 其中 y 是样本的真实标签(±1)x 是样本的输入 η 是学习率
- 本质上就是一个单层的神经网络
- 缺点:判别函数输出的是两个离散点 没法进行梯度优化 并且我们只能知道样本属于哪个类别 但无法知道属于某一类的概率(置信度)
逻辑回归
- 逻辑函数:log(y/(1-y)) 其中 y 是样本属于某一类的概率
- 经推导 若样本呈正态分布 逻辑函数可以被表示为 wT * x + w0 即 x 的线性函数
- 再经反推得 y=1/(1+e^(-z)) 即 sigmoid 函数 其具有概率性质
- sigmoid 的导数:y=sigmoid(x) 则 dy/dx = y(1-y)
- 判别函数:g(x) = 1/(1+e^(-wTx+w0)) 即上面推导的逻辑函数 大于和小于 0.5 分别代表两个类别
- 损失函数:交叉熵损失函数
- CE(p, q) = -∑(p(x) log(q(x))) 其中 p(x) 是样本的真实分布 q(x) 是判别函数的输出
- 对于二分类 有 l=-y log(g(x)) - (1-y) log(1-g(x)) 其中 y 是样本的真实标签(0 或 1)g(x) 是判别函数的输出
- 训练过程:梯度下降法 不断调整 w 和 w0 使得损失函数最小化即可
- 优点
- 判别函数具有概率性质 可以代表样本属于某一类的概率
softmax 回归
- 对于多分类问题 可以使用 softmax 函数
- softmax 函数:softmax(z_i) = e^(z_i) / ∑(e^(z_j)) z 是原始的得分
- softmax 具有两个性质:当有一个较大值时 其输出值接近 1 其它值接近 0 并且其连续可微
- 判别函数:g(x) = softmax(wTx + w0) 即将逻辑回归的判别函数推广到多分类问题 输出的是一个概率向量 wTx + w0 也被称为 logits 即原始得分
- 损失函数:交叉熵损失函数 l=-∑(y_i log(g(x_i))) 其中 y_i 是样本的真实标签(one-hot 编码)g(x_i) 是判别函数的输出 简化后得到 l=-log(p_i) 其中 p_i 是预测样本属于第 i 类的概率 相当于最大化正确类别的预测概率
- 优化算法:梯度下降法
L7 - SVM
- 线性分类只能找到一个超平面来划分数据集 但是不能找到效果最优的超平面 通常距离各个类别的边界最远的超平面效果最好
- 如果超平面为 wTx+w0=0 且 wTx+w0=±1 为两个类别的边界 则两个超平面之间的距离为 2/||w|| 在给定约束(所有样本都在边界之外)的情况下 最大化这个距离即可 即一个最优化问题(二次规划问题)
- 核心思想:在所有能正确分类的超平面中找到间隔最大的超平面 经过数学形式化后成为一个最优化问题 目标变为 1/2||w||^2 方便求导优化
- 模型结构和逻辑回归一样 经过一个线性层
- 损失函数:hinge 损失函数 即 max(0, 1-y(wTx+w0)) 再加上正则化项||w||^2 前者代表约束条件(若分类正确且位于间隔外则为 0 否则有惩罚)后者代表间隔最大化 最终 L = λ/2||w||^2 + ∑(max(0, 1-y(wTx+w0))) / N 其中 N 是样本数量 y 是样本的真实标签(±1)w 是权重 x 是样本的输入
- 优化方法:梯度下降法 导数需要分类计算
L8 - MLP
- 基本思想:感知机基于人的神经元模型 一个感知机可以看作一个神经元 一个多层感知机可以看作一个神经网络
- 感知机的结构:y = f(wTx + w0) 其中 f 是激活函数
- 单层感知机只能解决线性可分问题 比如 xor 问题不能解决
- 引入隐藏层的多层感知机等价于单层感知机 无法解决非线性问题
- 引入非线性激活函数的多层感知机可以真正做到拟合非线性边界
- 阶跃函数不可导 使得优化困难 因此后续提出了 Sigmoid 函数、ReLU 函数等作为激活函数
- 最终的 MLP 可以看做是任意的非线性函数模型
- 训练过程:
- 正向传播:从输入层到输出层计算每一层的输出
- 反向传播:利用链式求导计算梯度 即从最后一层往前计算梯度 做到递归计算
- 参数更新:使用反向传播得到的梯度来更新参数
Deep Learning
- MLP 有两种 一种是浅层但是较宽的网络 一种是深层但是较窄的网络 其中后者在 2012 年的 ImageNet 比赛中取得了突破性的进展 从而引发了深度学习的热潮
- 深层 MLP 的优势在于可以模块化地学习特征 从而可以学习到更加复杂的特征 而浅层 MLP 需要指数级的神经元才能表示线性深度的组合
- 深度学习严格的定义是深度表征学习 即一层一层的抽象出数据的特征
- 常见的深度学习模型
- DNN:深度神经网络 即多层感知机 经常作为其他模型的中间层 而不直接使用
- CNN:卷积神经网络 适用于图像处理任务
- RNN:循环神经网络 适用于序列数据处理任务
- Transformer:适用于自然语言处理任务
L9 - LM
- 语言模型是一种用于预测下一个词的监督学习算法
Word Embedding
- 在构造模型之前 需要先对文本进行预处理 首先是文本的向量化(考试重点)
- one-hot 编码:将每个词映射为一个唯一的整数 维度太大 并且所有词之间互相正交 没有相似性
- Word2Vec:将每个词映射为一个低维的稠密向量(也就是嵌入)使得相似的词在向量空间中距离较近 有两种模型可以采用 其基本思想都是单词的语义和周围的单词(上下文)强烈相关
- CBOW(词袋模型):输入上下文单词 输出中心词
- 结构
- 输入层:输入上下文单词(也就是一个窗口中)的 one-hot 编码
- 矩阵 W:将 one-hot 编码映射为低维词向量 然后对词向量求和或求平均
- 矩阵 W’:输入平均词向量 输出 logits 代表中心词的概率大小
- 最终通过 softmax 函数将 logits 转换为概率分布 代表每一个单词是中心词的概率
- 训练:梯度下降法 当真实的中心词概率太低时 通过梯度下降法调整参数
- 最终矩阵 W 就是 word2vec 的映射表
- 结构
- Skip-gram(跳字模型):输入中心词 输出上下文单词
- CBOW(词袋模型):输入上下文单词 输出中心词
- 定义:语言模型的本质是预测下一个词的概率 即 P(wt|w1,w2,…,wt-1) 通过最大化这个概率来训练模型
- 语言模型需要支持变长输入、具有长期依赖性、保留语序信息等特性 于是引入了 RNN 模型
RNN
- RNN(循环神经网络)是一种具有记忆性的神经网络 每一次的输出由上一个时间步的隐藏状态和当前的输入共同决定 即 hi=f(hi-1, xi) 也就带上了之前所有数据的特征 适合预测时间序列数据与自然语言处理 注意这里的隐藏状态是针对层的 也即每一个隐藏层都会接受上一个时间步自己的输出
- 应用
- 语言分类:输入一个句子 输出一个向量 代表这个句子的类别
- 语句生成:输出的向量进行 softmax 处理 得到一个概率分布 代表下一个词的概率
- 理论上来说 只要能 tokenize 就可以用 RNN 来进行预测生成
- LSTM(Long Short-Term Memory):长短期记忆网络 是 RNN 的一种变体 通过门控机制来控制信息的流动 具体而言 LSTM 有三个门:遗忘门、输入门、输出门 遗忘门决定了之前的状态有多少会被遗忘 输入门决定了新的状态有多少会被加入 输出门决定了这个状态有多少会被输出 虽然 LSTM 仍不能并行 但是单个 LSTM 单元内部的计算的并行度较好 比较适合长期记忆的学习
L10 - Transformer
RNN Encoder-Decoder
- RNN Encoder-Decoder 是一种用于序列到序列的模型 由两部分组成 一个编码器和一个解码器 编码器将输入序列编码为一个固定长度的向量 c(一般是最后一层的隐藏状态)解码器将这个向量解码为输出序列(初始时输入 SOS 和作为初始隐藏状态的 c 随后自然生成直至 EOS)
- 应用
- 机器翻译:输入一个句子 输出翻译后的句子
- 对话生成:输入一个问题 输出回答
- 缺点
- RNN 的并行性差 训练速度慢
- RNN 对于长序列的理解能力较差 这是因为不论多长的序列都会被编码为一个固定长度的向量 对于长序列 向量无法包含所有的信息
- 为了适应变长序列 RNN 也可以引入注意力机制
- Encoder 不再将输入序列编码为一个固定长度的向量 而是输出每一个时间步(对应输入序列的每一个单词)的隐藏状态向量 H = [h1, h2, …, hn] 其中 n 是输入序列的长度
- Decoder 在每一步生成输出时 通过注意力机制计算当前时间步的上下文向量 c = ∑(α_i * hi) 其中 α_i 是注意力权重 代表了当前时间步对输入序列中第 i 个单词的关注程度
- 注意力权重也是一个可以训练的参数矩阵
Transformer
- Transformer 是一种基于注意力机制的模型 与之前的 RNN Encoder-Decoder 模型相比 其可以并行化训练 速度更快
- Transformer 并行化的关键是 Self-Attention 机制(考试重点)
- RNN 对于语句的理解是顺序的 即必须按照时间步逐个理解单词
- Self-Attention 机制是并行的 可以在同一时间理解所有单词 通过反复理解可以得到最终的语句表示
- 之所以叫自注意力 是因为 Q、K、V 的来源相同 即输入序列本身
- 具体而言
- 将每个单词 embedding 为一个向量 H
- 通过三个矩阵 Wq、Wk、Wv 将每个单词的向量映射为三个向量 q、k、v
- 计算每个单词组合的 q_i 和 k_j 的点积 α_ij 代表了单词 i 对单词 j 的注意力权重
- 用 sqrt(dk)和 softmax 函数将权重矩阵归一化 得到注意力权重 Aij
- Hi’ = ∑(Aij * Vj) 其中 Aij 是单词 i 对于单词 j 的注意力 Vj 是单词 j 的向量 这个 Hi’ 就是单词 i 的新的理解
- SA 的计算过程类似于矩阵运算 因此显然可以并行化 具体而言
- Q = H * Wq, K = H * Wk, V = H * Wv
- A = softmax(Q * K^T / sqrt(dk)) 其中 dk 是 K 的维度
- H’ = A * V
- RNN 可以保留语句的顺序 而 SA 机制是不保留顺序的 因此 TF 引入了位置编码(Positional Encoding)
- 一个位置对应一个唯一的位置向量 e_i 这个 e_i 会被加到单词的向量 h_i 上一起输入到模型中
- 将 RNN Encoder-Decoder 模型中的 RNN 替换为 Self-Attention 就得到了 Transformer 模型
- TF 还可以用 Resudual Connection 和 Layer Normalization 来加速训练
- Residual Connection:将输入直接加到输出上 使得模型更容易训练
- Layer Normalization:对每一层的输出进行归一化 使得模型更容易训练
- Attention Masks
- 在计算注意力权重时 需要对输入序列进行掩码处理 以防止模型看到未来的信息 或是被填充的部分影响
- 掩码一般是用负无穷来消除掉对应权重
- 掩码有两种
- Self-Attention Mask:用于掩码填充部分
- Cross-Attention Mask:用于 Decoder 忽略输入序列中填充部分
- Causal Mask:用于 Decoder 掩码未来的信息
- 训练方法:梯度下降
- TF 存在的问题是训练数据不够 当数据量较小时 容易过拟合 然而我们可以把所有语言任务视为同一个任务 也就可以统一所有语言数据进行训练 这也就是预训练模型和大语言模型的由来
- 完整模型结构:
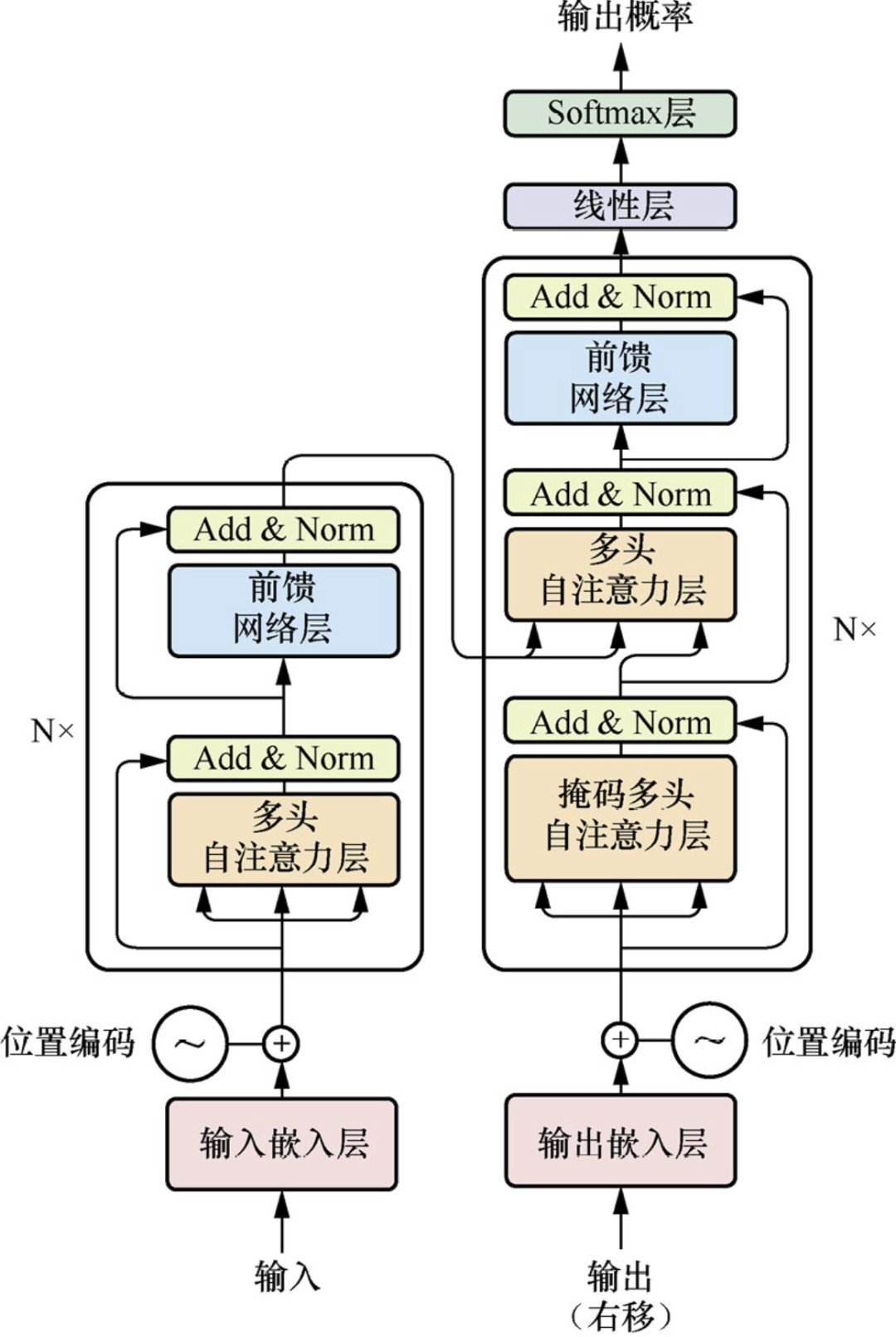
- 整个模型包括编码器、解码器、输入嵌入、输出嵌入以及最后的一个线性 softmax 层
- 编码器的架构很简单 有 N 个块 每个块中包含两个子层:多头自注意力层和前馈神经网络层 其中每个子层都有一个残差连接和层归一化 整个编码器的超参数只有 2 个 N 和 d_model 前者是块数 后者是每个块输入输出的维度(为了方便残差处理 输入和输出的维度是一样的)
- 每个子层的最终输出可以认为是 LN(x+Sublayer(x))
- Embedding:即将每个单词嵌入为一个向量
- Positional Encoding:为了保留序列的顺序信息 我们需要对每个单词的向量加上一个位置编码 这个位置编码是一个正弦函数和余弦函数的组合 这样可以保证每个单词的向量都是唯一的 这个位置编码和嵌入相加之后输入到多头自注意力层
- LayerNorm:BatchNorm 就是把一个 batch 的数据中的一个列进行归一化 而 LayerNorm 是把一个 batch 的数据中的每一行进行归一化 对于序列数据而言 前者是取出了一个特征上整个 batch 和 seq 的数据 而后者是取出了一个样本的整个 seq 和所有特征的数据 如果序列数据的长度差别较大 BN 每次算出的均值和方差往往差别也较大 使得模型不稳定 泛化性差 而 LN 是对每个样本计算均值和方差 相对稳定、
- Multi-Head Attention:即将 Q、K、V 分成 h 组 然后分别计算每一组的注意力权重 最后将所有的注意力权重拼接起来 这样可以提取出不同的特征
- Feed-Forward Network:即对每个单词的向量做 MLP 这个和 RNN 的做法是类似的 RNN 中 MLP 的输入是上一个输出和当前输入 而这里 MLP 的输入就是经过注意力计算后的向量 都是对于已经做语义嵌入后的向量进行处理
- 我的理解:多头注意力层输入一个序列(嵌入) 这个嵌入代表对于每一个词的特征的理解 经过多头注意力层后 输出的还是一个嵌入 代表的还是对于每一个词的特征的理解 但是这个理解是基于自注意力机制的计算后 更加完善的理解 其特征更加的丰富和准确 至于 Q、K、V Q 和 K 分别代表单词 i 和 j 做点积就是计算单词 i 和 j 的相关性 V 代表需要取出单词 j
- 解码器的架构和编码器类似 只是多了一个子层:掩码多头自注意力层
- 掩码多头自注意力层:在计算注意力权重时 只考虑当前单词和之前的单词 这样就可以保证解码器是自回归的 具体实现中 会将 t 之后的注意力权重置为-inf
- 第一个掩码层输出的 Q 与编码器输出的 K、V 作为第二个子层的输入 这里可以理解为模型先理解当前已生成的序列 得到查询 Q 然后去输入序列中寻找相关的上下文信息 K、V 用于生成下一个单词
- 我的理解:第一个掩码层代表解码器对于已有输出序列的理解 第二个注意力层输入的代表了已有序列和输入序列 用注意力去查询重要的部分 输出最终的理解
L11 - LLM
Pre-trained Models
- 预训练模型有两步
- 预训练:在大规模的无监督数据集上进行训练 使得模型能够学习到语言的基本规律
- 微调:在小规模的有监督数据集上进行训练 使得模型能够适应特定的任务
BERT
- BERT(Bidirectional Encoder Representations from Transformers)是一种预训练模型 其使用了双向的 Transformer 编码器(双向指的是训练时同时考虑左右上下文 即不添加掩码)
- BERT 的预训练任务有两个
- Masked Language Model:随机掩码输入序列中的一些单词(即用 mask 替换)然后训练模型去预测这些单词
- Next Sentence Prediction:预测两个句子是否相邻 即预测语句 B 在语句 A 后面的概率
- 预训练流程
- BERT 输入的文本是一个句子对 其中第一个句子是 A 第二个句子是 B 然后用一个特殊的分隔符 [SEP] 将两个句子分开 在句子 A 的开头加上一个特殊的开始符号 [CLS] 作为整个句子的表示
- 输入的 token 需要进行嵌入 这个嵌入是一个向量 这个向量是由三个部分组成的
- Token Embedding:即将每个单词嵌入为一个向量
- Segment Embedding:即将每个句子嵌入为一个向量 用于区分句子 A 和句子 B
- Position Embedding:即将每个单词的位置嵌入为一个向量 用于保留序列的顺序信息
- MLM 需要对输入的文本进行掩码处理 随机选择 15%的单词进行掩码 然后将掩码的单词替换为 [MASK] 其他的单词不变 为了和微调时的输入保持一致 需要做以下处理
- 80% 的概率替换为 [MASK]
- 10% 的概率替换为随机的单词
- 10% 的概率不变(但是要用于预测)
- NSP 输入的文本是一个句子对 A 和 B B 有 50%的概率是 A 的下一个句子 50%的概率是随机的句子
- BERT 的微调任务是将预训练的模型应用到特定的任务上 比如要做文本分类
- 只需要在 BERT 的基础上加一个线性层和 softmax 层作为分类器即可
- BERT 不适合生成任务 只能用于分类任务
GPT
- GPT(Generative Pre-trained Transformer)是一种预训练模型 其使用了单向的 Transformer 解码器 只能用于生成任务(单向指的是训练时只考虑左上下文 即添加了掩码)
Fine-tuning
- 微调即根据特定任务的数据集来训练模型 使得模型能够适应特定的任务
- hugging-face 提供了很多开源的预训练模型 可以直接下载下来进行微调
- 微调需要的计算量比较大 PEFT(Parameter Efficient Fine-Tuning)是一种微调方法 其只需要微调模型与任务相关的一部分参数 而不是全部参数
- LoRA(Low-Rank Adaptation)是一种 PEFT 方法 其通过将模型的权重矩阵分解为两个低秩矩阵来减少参数量
- LLaMA 是一个微调工具
Prompt Engineering
- 提示词(Prompt)是一种用于引导模型生成特定输出的文本 其可以是一个问题、一个句子或一个段落
- 最基本的 Prompt 是直接给出问题或任务的描述
- Few-shot Prompt:给定一些示例来引导模型生成特定输出
- Chain-of-thought Prompt:给定一些推理过程来引导模型生成特定输出
- ReAct Prompt:给定一些反应过程来引导模型生成特定输出
RAG
- RAG(Retrieval-Augmented Generation)是一种结合了检索和生成的模型 其通过检索相关的信息来增强生成的能力
- 具体而言
- 首先根据输入的文本检索相关的信息
- 然后将检索到的信息与输入的文本一起输入到生成模型中
- 最后生成模型根据输入的文本和检索到的信息生成输出
- RAG 由 3 个部分组成
- Embedding:将输入的文本和检索到的信息映射为向量
- Vector Store:存储向量化的信息
- LLM:生成模型
L12 - CNN
- 核心思想
- 全连接神经网络处理图像分类具有以下问题
- 果使用传统的向量作为输入 那么一旦物品产生小位移 就会导致向量大幅度变化
- 对于图像输入来说参数太大 就算计算资源足够 过大的参数也往往会导致过拟合
- 除此之外 全连接神经网络把图片作为一个向量输入 丢失了空间信息 并且看不到局部信息
- 显然我们需要一个位移无关且局部相关的特征表示方式 这个方式就是卷积 使用卷积核提取特征就是 CNN 的核心思想
- 题外话 卷积核模仿的是人类细胞的感受野 其会识别特定的特征
- CNN 往往还有 stride、padding、pooling 等操作
- stride:卷积核每次移动的步长
- padding:在输入图像的边缘添加零值 使得卷积核可以覆盖到边缘的像素
- pooling:下采样操作 用于减少特征图的大小 减少参数计算量 防止过拟合 并且使得模型更具鲁棒性(因为池化对于小的位移和变形不敏感 具有平移不变性)
- 全连接神经网络处理图像分类具有以下问题
- 一些经典 CNNs
- LeNet:最早的卷积神经网络 由 Yann LeCun 提出 用于手写数字识别
- AlexNet:2012 年的 ImageNet 比赛中获胜的卷积神经网络 由 Alex Krizhevsky 提出
- VGGNet:2014 年的 ImageNet 比赛中获胜的卷积神经网络 由 Karen Simonyan 和 Andrew Zisserman 提出
- ResNet:2015 年的 ImageNet 比赛中获胜的卷积神经网络 由 Kaiming He 提出 其使用了残差连接(Residual Connection)来解决深度网络训练困难的问题
- 计算公式
- 卷积层输出大小:Hout = (Hin - K + 2P) / S + 1(向下取整)
- Hin:输入大小
- K:卷积核大小
- P:padding 大小
- S:stride 大小
- 池化层输出大小:Hout = (Hin - K) / S + 1(向下取整)
- Hin:输入大小
- K:池化核大小
- S:stride 大小
- 卷积层参数量:K * K * Cin * Cout + Cout * has_bias
- K:卷积核大小
- Cin:输入通道数
- Cout:输出通道数=卷积核数
- has_bias:是否有偏置项
- 感受野大小:RFi = (RF{i-1} - 1) * S + K
- RF_i:第 i 层的感受野大小
- RF_{i-1}:第 i-1 层的感受野大小 RF_0 = 1
- S:stride 大小
- K:卷积核大小
- 全连接层参数量:(Cin + has_bias) * Cout
- Cin:输入维度
- Cout:输出维度
- has_bias:是否有偏置项
- 卷积层输出大小:Hout = (Hin - K + 2P) / S + 1(向下取整)
L13 - CV
图片分割
- 图片分割是计算机视觉中的一个重要任务 其目的是将图像中的每个像素分配给一个类别
U-Net
- 基本思想:是一种 image2image 的模型 先通过池化、卷积进行下采样提取特征图 再通过合适的上采样操作将特征图恢复到原图大小
- 逆卷积
- 一次卷积操作可以等价于对输入图像乘一个矩阵 这个矩阵被称为卷积矩阵
- 同理 想要把特征图放大 只需要对输入图像乘一个转置卷积矩阵
- 逆卷积操作就是一个可以等价于对输入图像乘一个转置卷积矩阵的操作 其可以将特征图恢复到原图大小
- 逆卷积包括两步操作
- 在特征图的每个像素之间插入(s-1)个零
- 对上采样后的特征图进行卷积操作
- 特征图为 d * d 卷积核为 k * k 则逆卷积的输出大小为 (d-1) * s + k - 2p 其中 s 是步长 p 是填充大小
- 模型结构:
- 编码器:由多个卷积层和池化层组成 逐层降低特征图大小
- 解码器:由多个逆卷积层和卷积层组成 逐层恢复特征图大小
- 跳跃连接:解码器中每一层的输入包括了编码器对应层的特征图 以及解码器上一层的输出 这使得解码器可以更好的获取全局信息
目标检测(掌握思路)
- 目标检测是计算机视觉中的一个重要任务 其目的是在图像中找到目标的位置和类别
- 对于单目标而言 分类非常简单 只需要一个卷积神经网络就可以完成 位置检测则需要给出一个坐标和高宽来表示目标的位置
- 选择搜索算法:对于多目标而言 需要先生成目标可能出现的候选区域 选择搜索算法可以高效的生成候选区域
- 生成初始区域:使用图像分割算法将图像分割成多个小区域
- 合并区域:计算相邻区域的相似度 递归合并相似度高的区域 直到所有区域都被合并为止 合并过程所有的中间结果都会被保存下来作为候选区域
- 生成候选框:对每个候选区域进行筛选 形成最终的候选框
- RCNN(Region-based CNN)
- 使用选择搜索算法来生成候选框(约 2000 个/图)
- 对每个候选区域 缩放到固定尺寸 使用预训练好的 CNN(比如 AlexNet 输出层替换为目标类别+背景的分类器)提取出特征图
- 对每个特征图进行分类和回归 分类基于 SVM 预训练好用于决定候选框是否包含目标 回归基于线性回归 预测框的偏移 用于修正候选框的位置和大小
- 缺点是候选框太多 速度非常慢
- Fast RCNN
- 使用选择搜索算法来生成候选框(约 2000 个/图)
- 将整张图像输入到 CNN 中 得到一个特征图
- 对每个候选框 在特征图上进行 RoI(Region of Interest)池化操作 即将候选框映射到特征图对应区域 作为其特征图 然后使用 max 池化缩放到固定尺寸
- 将 RoI 池化后的特征图输入到全连接层进行分类和回归 分类基于 softmax 回归基于线性回归
- Fast RCNN 解决了 RCNN 速度慢的问题 缺点是选择搜索算法生成候选框的速度仍然较慢
- Faster RCNN
- 使用一个轻量级的 CNN(比如 VGG16)作为特征提取器 得到一个特征图
- 将特征图输入给 RPN(Region Proposal Network)来生成候选框 RPN 是一个小的 CNN 网络 特征图被划分为多个 anchors 每个 anchor 输入给 CNN 预测每个 anchor 是否包含目标 以及目标的偏移量 最终生成一组候选框
- 对每个候选框 在特征图上进行 RoI 池化操作 即将候选框映射到特征图对应区域 作为其特征图 然后使用 max 池化缩放到固定尺寸
- 将 RoI 池化后的特征图输入到全连接层进行分类和回归 分类基于 softmax 回归基于线性回归
- Faster RCNN 解决了 Fast RCNN 中选择搜索算法生成候选框的速度慢的问题 但是仍然需要对每个候选框进行 RoI 池化操作
- YOLO(You Only Look Once)
- 使用一个 CNN 输入全图 输出一个封装好的向量 维度为 (S, S, B * 5 + C) 其中 S 是网格大小 B 是每个网格预测的边界框数 C 是类别数
- 每个网格预测 B 个边界框 每个边界框包含 5 个值(x, y, w, h, confidence)和 C 个类别概率
- 将置信度乘以类别概率 得到每个类别的最终置信度 删去所有类别置信度都低于阈值的边界框
- 对每个网格的边界框进行非极大值抑制(NMS)来去除检测到同一个目标的多个边界框
- YOLO 的优点是速度快 但是精度不如 Faster RCNN
其它任务
Image Captioning
- 图像描述本质上是翻译任务 因此可以用 Encoder-Decoder 模型解决 即将图像编码为一个向量 然后将这个向量解码为描述 可以使用注意力机制来增强模型的能力 也可以把图片的特征图作为输入向量 构造带自注意力机制的 CNN 模型 甚至可以 CNN 作为 Encoder 部分 Transformer 作为 Decoder 部分
ViT
- ViT(Vision Transformer)是 由 Google 于 2020 年提出的一个图像分类模型 使用了 TF 的架构 将图片视为多个 patch 输入给 TF 进行训练
- ViT 将输入的图片划分为 16x16 的 patch 一个 patch 相当于一个 word 一张图片相当于一个语句序列 一个 patch 展平后投影得到的向量相当于一个 word embedding 位置编码类似于 NLP 是 patch 在图片中的位置
- 模型架构
- 假如输入的图片是一个 224x224 的 RGB 图片 将其划分为 16x16 的 patch 得到 196 个 patch 每个 patch 展平后投影得到的向量是一个 768 维的向量(因为 3 个通道)
- patch 向量先经过一个 768x768 的矩阵 被称为线性投影层 将每个 patch 的向量投影到一个 768 维的空间中 这个矩阵是可学习的 输出的向量称为 patch embedding
- 类似于 BERT ViT 在整个 patch 序列的开头加上一个特殊的向量 [CLS] 也是 768 维 这个向量在 TFE 中也会和其它所有向量互相作用 因此可以理解为这个向量是整个图片的表示 最终 CLS 向量用于分类
- 位置编码相当于一个表格 记录了每一个位置的编码向量 也就是一个 197x768 的矩阵 将位置编码和 patch 的向量相加
- 最终输入 TFE 的是 197 个 768 维的向量 其中第一个是 [CLS] 向量 后面 196 个是 patch 向量 一个 Encoder 可以包含多个多头注意力块
- 消融实验
- 论文提到 ViT 也可以将输出的 patch embedding 输入一个全局平均池化层 然后进行分类 其效果和 CLS 向量的效果差不多(但是需要的学习率不一样) 但是为了保持原有的 TF 架构 论文采用了后者 从而证明 TF 原生的架构就可以高效处理 CV 任务
- 论文提到 位置编码可以采用 1-D 的(1 2 3…) 也可以采用 2-D 的(1,1 1,2 1,3…) 也就是说 1-D 的是 196 个 768 维的向量 而 2-D 是 14+14 个 384 维的向量代表第 i 行和第 j 列的位置编码 然后只需要将两个向量拼接成 768 维的向量即可 最终实验证明位置编码的格式无所谓 因此还是采用了和 TF 一样的 1-D 编码
- 归纳偏置
- CNN 包括主要的 2 个归纳偏置:局部性和平移等变性
- TF 却没有这些归纳偏置 是全局理解序列的 因此论文认为小数据集上不如 CNN 是正常的 在大数据集下两者性能可以媲美
- 论文也提到混合 CNN 和 TF 的模型 也就是用 CNN 来处理 patch 得到 embedding 在小数据集上表现较好
- ViT 可以作为 IC 的编码器部分 后接普通的 TF 解码器等作为文本解码器即可进行图像描述生成
VLM(Vision Language Model)
- VLM 是可以同时理解图像和文本的多模态模型 一般由视觉编码器、文本编码器、融合层、生成器组成
- CLIP(Contrastive Language-Image Pre-training)
- 基本思想:将图片和文本分别编码 嵌入到同一个向量空间 目标是让相似的图片和文本在这个空间中相似度更高
- 损失函数:图片和文本的对比损失 代表希望正确的图片文本对的相似度最大
- 模型结构
- 视觉编码器:将图片编码为向量 如 CNN 或 ViT
- 文本编码器:将文本编码为向量 如 Transformer
- 融合层:将图片和文本的向量映射到同一个向量空间
- 推理时只需要找到内积最大的文本图片对即可
- 应用:图文检索、内容过滤
- VLM with Adapted LLM
- 用 LLM 作为 文本解码器
- 将图片输入给图片编码器 然后投影到和文本嵌入一致的维度 拼接后一起输入到 LLM 中 最终生成文本
- LLaVA 就是这样的模型 现在大部分的大语言模型都是这样的做法
L14 - Clustering
K-Means Clustering
- K-Means 是一种无监督学习算法 其目的是将数据集划分为 K 个簇 使得每个簇的内部相似度最大 而不同簇之间的相似度最小
- 具体步骤
- 随机选择 K 个初始中心点
- 将每个样本分配到离其最近的中心点所在的簇
- 更新每个簇的中心点 为该簇中所有样本的均值(也就是质心)
- 重复步骤 2 和 3 直到中心点不再变化或达到最大迭代次数
- 复杂度
- 时间复杂度:O(n * k * d * i) 其中 n 是样本数 k 是簇数 d 是维度 i 是迭代次数
- 空间复杂度:O(n + k * d)
- 如何确定 K?
- 肘部法则:通过计算不同 K 值下的 WCSS 来选择 K 值 通常选择下降速度骤减的拐点
- 轮廓系数(Silhouette Coefficient):用于衡量数据点与所属簇的紧密度和与其他簇的分离度 越大表示聚类效果越好 可以计算不同 K 的整体轮廓系数(所有数据点轮廓系数的平均值)来选择 K 值
- 如何选择合适的初始中心点
- K-Means++:在随机选择第一个中心点后 根据当前中心点的距离来选择下一个中心点 使得新选择的中心点距离当前中心点尽可能远
- 应用
- 图片分割
- 文本聚类
- 图片压缩:将图片的颜色空间划分为 K 个簇 然后用每个簇的中心点来表示该簇中的所有像素
- 优点
- 简单易实现
- 线性时间算法 非常高效
- 缺点
- 局部最优 最终解是不确定的
- 对于初始中心点的选择敏感
- 假设簇是球形的
- 需要数据可以求均值
L15 - Dimensionality Reduction
- 降维是将高维数据映射到低维空间的过程 其目的是减少数据的维度 使得数据更容易处理和可视化 本质上是减少特征之间的相关性 提取出独立的新特征
- 常见的降维方法包括 PCA 和 Auto-encoder
PCA
- 基本思想:通过线性变换将数据投影到一个新的坐标系中 使得新坐标系中的数据方差最大化
- 比如一组数据 X=[x1,x2,x3,…,xn] 采用新坐标轴 u1 和 u2 那么 zi=uiT*xi 就是新坐标系轴下的投影 Z=UT*X 就是经过转换后的所有坐标 我们需要找到的就是 ui 使得 var(uiT*X)=uT*S*u 最大 其中 S 是原始数据的协方差矩阵
- 形式化问题(一个二次规划问题)
- 目标函数:max(uT*S*u)
- 约束条件:||u||=1 即 u 是单位向量
- 通过拉格朗日条件
- L(u, λ) = uT*S*u - λ(||u||^2-1)
- 对 u 求导数 令其为 0 得到 S*u=λ*u
- 也就是对于协方差矩阵 S 求特征值和特征向量 求得的特征向量 u 就是解 特征值就是对应主成分方向上的方差
- K 的选定:info loss=1-∑(λi/∑λi) 其中 λi 是特征值 即降维后保留方差的百分比 代表降维的信息损失率 通常选定损失率大于 0.95
- 具体步骤
- 对数据进行标准化 (均值为 0 方差为 1)
- 计算协方差矩阵 S
- 计算协方差矩阵 S 的特征值和特征向量 按照特征值从大到小排序
- 选择前 K 个特征向量作为新的坐标系
- 将数据投影到新的坐标系中 得到降维后的数据
- 应用
- 人脸识别:将人脸图像降维为多个特征向量 每一个新的人脸都可以表示为这些特征向量的线性组合
- PCA 本质上是一个神经网络 提取出了原数据的主成分特征
Auto-encoder
- Auto-encoder 是一种非线性降维方法 其通过神经网络来学习数据的低维表示
- 模型结构
- 编码器:将输入数据编码为一个低维的表示
- 解码器:将低维的表示解码为原始数据
- 损失函数:最小化输入数据和解码器输出数据之间的差异
- Deep Auto-encoder:将深度神经网络作为编码器和解码器 编码后的向量被称为隐编码(latent code)
- Denoising Auto-encoder:在输入数据中添加噪声 然后训练解码器恢复原数据 使得模型可以进行数据清洗、图像去噪等任务
- AE 和 PCA 的区别在于 PCA 是线性的 AE 是非线性的 但是两者可以看做殊途同归 都是在对数据进行降维
- 应用:图片搜索 先将数据降维之后再做相关性搜索 可以找到相似的图片
L16 - Generative Model
- 生成模型是指通过学习数据的真实分布来生成新的数据的模型 通过概率分布 模型可以生成符合某些特征的数据
GAN(概念为主)
- GAN(Generative Adversarial Network)是一种生成模型 其通过对抗训练来学习数据的真实分布
- 模型结构
- 生成器(Generator):生成新的数据
- 判别器(Discriminator):判断数据是真实的还是生成的
- 假设数据 x 的真实分布是 p_g 我们通过生成器 G 来拟合这个分布 也即 G(z;θg) 其中 z 是一个符合 p_z 分布的噪声向量(维度可以和输出不一样)θg 是 G 的参数
- 判别器 D(x;θd) 用于判断输入的 x 是真实数据还是生成数据 其中 θd 是 D 的参数 输出的值是一个概率值 0-1 之间
- G 的损失函数是 log(1-D(G(z))) 即希望骗过 D
- D 的损失函数是 log(D(x))+log(1-D(G(z))) 即希望正确判断真实数据和生成数据
- 因此最终的损失函数为这个损失函数是一个对抗性损失函数 最终会达到一个纳什均衡 即 D 和 G 都无法再继续优化损失函数
1
min_G max_D V(D,G) = E_x~p_g[log(D(x))] + E_z~p_z[log(1-D(G(z)))]
- 具体流程
- 从真实分布中采样数据 x 从噪声分布中采样数据 z
- 输入数据到判别器 D 中 计算损失函数
- 根据损失函数更新判别器 D 的参数
- 循环 1-3 步 k 次
- 从噪声分布中采样数据 z
- 输入数据到生成器 G 中 计算损失函数
- 根据损失函数更新生成器 G 的参数
- 循环 1-7 步 直到收敛
- 可以看到超参数 k 会影响对抗训练的有效性 k 过大会使得 D 更新过快 导致损失函数接近于 0 使得梯度消失 k 过小则会使得 D 更新过慢 导致损失函数基本不变 使得 G 无法更新
- GAN 的变体
- DCGAN:使用卷积和逆卷积神经网络作为生成器和判别器 其具有 latent vector arithmetic 的特性 类似于戴眼镜的男人-不戴眼镜的男人+不戴眼镜的女人=戴眼镜的女人
- Conditional GAN:在生成器和判别器中加入条件变量 使得生成的数据具有特定的属性 相当于一个 image2image 的模型(图像翻译)
- Cycle GAN:用于无监督的图像翻译 其通过循环一致性损失来训练模型 使得无需配对数据就可以训练模型实现图像风格的转换 两个生成器 G 分别将 A 风格的图像转换为 B 风格的图像和 B 风格的图像转换为 A 风格的图像 两个判别器 D 分别判断 A 风格的图像和 B 风格的图像是否真实 损失函数基于原图和模型经过两个生成器后转换回来的图像
- GAN 的缺陷是必须要借助判别器来指导生成器训练 如果需要不同特征的图片生成 就需要不同的判别器 VAE(Variational Auto-encoder)通过 AE 学习数据的特征 从而做到直接生成不同特征的图片
VAE
- VAE(Variational Auto-encoder)是一种生成模型 其通过变分推断来学习数据的真实分布
- AE 本身可以做到将图片编码为特征向量 然后解码回原始图片 但是无法做到从这个特征向量生成相似图片(因为向量附近的其他向量生成的可能是无意义噪声)即向量空间中有效的区域是离散的 因此我们希望 AE 编码出的是一个分布 而不是一个向量
- 训练过程
- 编码器:输入图片数据 输出均值向量 μ 和方差向量 σ 均值就代表了特征 而方差代表了图像可以偏离特征的程度
- 重参数化:从均值和方差向量中采样一个向量 z=μ+σ*ε 其中 ε 是从标准正态分布中采样的噪声 保证了 z 的分布是连续的 从而可以传播梯度
- 解码器:输入 z 输出重构的图片
- 损失函数:最小化重构损失和 KL 散度
- 重构损失:最小化输入数据和解码器输出数据之间的差异 通常用均方误差(MSE)或二元交叉熵
- KL 散度:最小化编码器输出的分布和标准正态分布之间的差异
- Loss = E[||x-x’||^2] + KL(q(z|x)||p(z))
- 梯度下降 反向传播
- VAE 本质上将特征向量的空间通过正则化变成了具有连续性和完整性的分布
- 缺点:潜编码维度远小于输入数据 且生成是一步完成的
Diffusion Model
- Diffusion Model 是一种生成模型 其通过逐步去噪声来生成新的数据 可以解决 VAE 生成图片模糊的问题
- 训练过程
- 从真实数据中采样数据 x0
- 将数据逐步添加噪声 直到变成标准正态分布
- 学习一个去噪声的模型 D(x, t) 来预测每一步的噪声 一般是一个带有时间步嵌入的 U-Net 而损失是相同时间步的真实噪声和预测噪声之间的均方误差
- 从标准正态分布中采样数据 xt
- 使用去噪声模型 D(x, t) 来逐步去噪声 直到得到新的数据 x0
L17 - RL
MDP
- 强化学习属于机器学习中与监督学习和无监督学习并列的分支 其核心思想是在缺少标签数据的情况下 通过与环境的交互来学习一个策略 使得模型可以在给定的状态下选择一个最优的动作(或策略)
- 马尔可夫决策过程(MDP)是强化学习的基础模型 核心观念是马尔可夫性 也就是当前状态只与前一个状态有关 与之前的状态无关
- RL 的形式化定义
- 基本要素
- 状态空间 S:表示所有可能的状态
- 动作空间 A:表示所有可能的动作
- 策略 π:表示在给定状态下选择的动作 是一个条件概率分布
- 奖励函数 R:表示在给定状态下选择的动作所获得的奖励
- 回报函数 G:奖励随时间的积累 其中折扣因子 γ 用于控制未来奖励的权重
- 基本流程
- 给定当前状态 s_t
- agent 根据策略 π 选择一个动作 a_t
- agent 执行动作 a_t 环境根据动作 a_t 转移到下一个状态 s_t+1 并返回奖励 r_t(需要注意 环境的转移可能是一个概率分布)
- agent 根据奖励 r_t 和下一个状态 s_t+1 更新策略 π
- 重复 1-4 直到达到终止状态
- 基本要素
- RL 的目标:找到一个最优的策略 π 使得在这个策略下 回报 G 的期望值最大化
- 这个期望值有两种形式 第一种是价值函数 V_π(s) 即状态 s 下 之后持续执行 π 策略所获得的期望回报 用于评估给定策略 π 下状态 s 的价值
- 第二种是动作价值函数 Q_π(s,a) 也就是在状态 s 下 执行动作 a 后 之后持续执行 π 策略所获得的期望回报 用于评估给定策略 π 动作 a 的价值
- Bellman 方程
- 任何状态下的回报期望都可以拆解为当前状态的即时奖励和下一个状态开始累积的未来奖励 这样的递归关系被称为 Bellman 方程
- V(s) = E[R_t + γV(s_t+1)|s_t=s]
- Q(s,a) = E[R_t + γQ(s_t+1,a’)|s_t=s,a_t=a]
- 寻找最优策略的方法
- 基于价值函数的方法:学习出准确的价值函数 然后让 agent 始终选择最大价值的策略 比如 Q-learning SARSA 等
- 基于策略的方法:直接学习策略本身 使得策略的长期回报最大化 比如 REINFORCE TRPO PPO 等
- 如何选择行动:前者使用 ε-贪婪策略来选择动作(前期探索 后期利用) 后者则直接按照动作的概率分布来选择
- 如何更新策略:前者基于贝尔曼方程更新价值函数 后者则会将对应策略的概率进行调整(比如获得正奖励就增加概率 负奖励就减少概率)
- 其中价值方法中更新策略包括 Monte Carlo(MC)方法和 Temporal Difference(TD)方法
- MC 方法:计算多个回合的平均值来估计价值函数 这使得模型方差较大 但是偏差较小
- TD 方法:Q(s,a)’ = Q(s,a) + α[R_t + γmaxQ(s_t+1,a’) - Q(s,a)] 基于最优贝尔曼策略 总是选择 Q 最大的动作 使用即时奖励和 2 个估计值来估计价值函数 这使得模型方差较小 但是偏差较大
- 优化算法的超参数
- 更新频率:更新策略的频率 比如可以一回合更新一次 也可以每个时间步都更新
- 传播深度:更新策略时 向后传播多远 比如可以只传播到当前状态 也可以传播到更远的状态
- 优化公式:比如价值算法可以用 TD 也可以用 MC
Q-Learning
- Q-learning 是一种基于价值函数的方法 其主要思想是通过学习状态价值函数 Q(s,a) 来选择最优的动作
- 算法流程
- 随机初始化 Q(s,a) 表格
- 基于状态 s 使用 ε-贪婪策略来选择动作 a 即概率 ε 选择随机动作 1-ε 选择 Q 值最大的动作
- 得到奖励 r 和新状态 s’ 更新 Q(s,a)’ = Q(s,a) + α[r + γmaxQ(s’,a’) - Q(s,a)] 其中 α 是学习率 γ 是折扣因子
- 转移到新状态 s’ 重复 2-3 步直到达到终止状态
- 注意 更新 Q 值时 选择了新状态 s’下最大 Q 值的动作 a’ 和实际执行的策略可能是不一致的 这就是 Q-learning 的 off-policy 特性
DQN
- DQN 是 Q-learning 的一种变种 其主要思想是使用深度神经网络来近似 Q(s,a) 的值 而非使用表格来存储 Q(s,a) 的值
- DQN 包含三个部分
- Q 网络:输入状态 s 输出 Q(s,a) 向量 目的是学习实际 Q 值
- 经验回放:一个表格 存储 agent 过去的经验(s,a,r,s’) 通过随机采样来打破数据之间的相关性
- 目标网络:和 Q 网络结构相同 目的是学习下一个状态后的折扣 Q 值
- 算法过程
- 生成训练数据:
- agent 根据 ε-贪婪策略在 Q 网络的输出中选择一个动作 a_t
- 执行动作 a_t 观察到奖励 r_t 和下一个状态 s_t+1
- 将 (s_t,a_t,r_t,s_t+1) 存入经验回放表格中
- 重复一定次数 得到批量的训练数据
- 训练 Q 网络:
- 随机从经验回放表格中采样一批数据(s,a,r,s’)
- 输入状态 s 计算 Q 网络的输出 选取对应动作的 Q 值 即 Q(s,a)
- 输入状态 s’ 计算目标网络的输出 选取最大的 Q 值 即 maxQ(s’,a’)
- 计算损失 L = MSE(Q(s,a),r+γmaxQ(s’,a’)) = Σ(Q(s,a)-r-γmaxQ(s’,a’))^2 / batch_size
- 使用反向传播算法来更新 Q 网络的参数
- 更新目标网络:
- 重复 1-2 一定次数后 再将 Q 网络的参数复制到目标网络中
- 生成训练数据:
- 可以看到 DQN 基本遵循了原始的 Q-learning 的思想 其中
- 经验回放的作用是打破数据之间的相关性(可以满足独立同分布)并且神经网络需要批量数据来训练
- 目标网络的作用是避免 Q 函数更新过快 导致模型不稳定
SARSA
- SARSA 和 QL 的唯一区别在于
- SARSA 是 on-policy 策略 也就是实际执行的策略和用于学习的策略一致
- 也即 会在真正选择了下一步的动作后 才会更新上一步的 Q 值
策略梯度算法
- 策略梯度算法是基于策略的方法 其本质是梯度上升法
- 目标函数是:J(θ) = E[R|π_θ] 也就是在当前策略下的期望回报 在实际中 我们对这个策略进行多次采样得到批量的轨迹 τ 然后计算 J(θ)的梯度
- 策略梯度定理告诉我们可以用采样的轨迹来估计 J(θ)的梯度 具体推导比较复杂 公式如下:其中 ∇logπ_θ(a|s)是策略的得分函数 代表了当前策略向动作 a 选择的倾向 而 Q(s,a)是当前状态下的动作价值函数 代表了当前状态下选择动作 a 的价值 因此梯度上升会使得策略倾向于提高价值大的动作的概率
1
∇J(θ) = E[∑∇logπ_θ(a|s)Q(s,a)] = E[∑∇logπ_θ(a|s)(r+γV(s'))] - 计算出梯度后即可更新策略:
- θ’ = θ + α∇J(θ) 其中 α 是学习率
Baseline
- 我们注意到整个梯度的计算中包含两项
- 第一项是 ∇logπ_θ(a|s) 也就是当前策略的梯度
- 第二项是 Q(s,a) 也就是当前状态下的动作价值函数
- 如果我们可以缩减某一项的尺度大小 就相当于给整个乘积值做了一个缩放 自然就可以减少方差
- Baseline 方法的核心思想就是将第二项减去一个基准值 b(s) 使得整体的方差变小 这个基准值需要保证无偏性 一般可以选择 Q(s,a)的均值作为基准值 也就是 V(s)
REINFORCE
- REINFORCE 是一种基于策略的方法 其主要思想是通过采样的轨迹来估计 J(θ) 的梯度
- 算法流程
- agent 根据当前策略 π_θ 采样多条轨迹 τ = (s_0,a_0,r_0,s_1,a_1,r_1,…,s_T,a_T,r_T)
- 对于每条轨迹的每一个时间步 t 计算 G_t = ∑γ^k-t * r_k (k=t+1,…,T) 也就是从时间步 t 开始到终止状态 T 的回报值
- 对于每条轨迹的每个时间步 得到三元组(s*t,at,G_t) 用于更新策略 θ’ = θ + α∇J(θ) = θ + α*γ^t*G_t*∇logπθ(a|s) 这里的 γ^t 是为了保证每一个三元组对于梯度的贡献是相同的 也即原公式中计算期望时是对每个(s,a)等权重求和
- 重复 1-3 直到收敛
- 由于 G_t 是一个随机变量 因此 REINFORCE 的方差较大 但是偏差较小 可以引入 baseline 方法来减少方差
Case: AlphaGo
- 策略网络:输入当前棋盘状态 输出每个可能动作的概率分布 通过监督学习来预训练(使用人类棋谱作为训练数据)通过自我对弈进行优化
- 价值网络:输入当前棋盘状态 输出当前状态的价值(胜率)通过蒙特卡洛预演来训练(通过自我对弈生成胜负结果 并进行回归)
- MCTS(Monte Carlo Tree Search):一种基于随机模拟的搜索算法 用于高效的寻找最优决策 AG 使用 MCTS 来选择最优动作 避免了固定策略网络的局限性和暴力搜索的低效性
- MCTS 包含四个步骤
- 选择(Selection):从根节点开始 根据 UCT(Upper Confidence Bound for Trees)选择一个子节点 直到到达叶子节点
- 扩展(Expansion):在叶子节点上扩展一个新的子节点
- 模拟(Simulation):从新扩展的子节点开始进行随机模拟 直到到达终止状态 利用了快速走子网络和价值网络来加速模拟
- 回溯(Backpropagation):将模拟结果回传到根节点 更新每个节点的访问次数和总奖励
- MCTS 包含四个步骤
Actor-Critic
- Actor-Critic 是一种结合了基于价值函数和基于策略的方法 其主要思想是使用一个价值函数来估计当前策略的价值 然后使用这个价值函数来更新策略
- baseline 方法提到过如何通过引入一个基准值来减少方差 而 A-C 算法中这个 baseline 就是状态价值函数 V 这使得梯度公式中的 Q(s,a)可以被替换为 Q(s,a)-V(s) 这个函数也被称为优势函数 A(s,a) 也就是在当前状态下 选择动作 a 的优势
- 我的理解:首先 V 是 Q 在不同动作下的期望值 因此 Q-V 不会改变整个期望值 然后 减去这个均值使得梯度中的后一项(Q(s,a)-V(s))的绝对值变小 这也就使得整个梯度项的方差变小了
- Actor-Critic 包含两个部分
- Actor:负责选择动作的策略网络 其输入状态 s 输出动作的概率分布 π_θ(a|s)
- Critic:负责估计当前策略的价值函数 其输入状态 s 输出价值 V(s)
- 具体流程
- Agent 执行一个时间步 t 得到(s,a,r,s’)
- Critic 根据当前状态 s 和动作 a 计算 V(s) 根据下一个状态 s’ 和当前策略的输出计算 V(s’)
- Critic 计算出 TD 误差 δ = r + γV(s’) - V(s)
- Critic 使用损失函数 L = MSE(δ) 来更新神经网络的参数
- Actor 更新策略 θ’ = θ + α∇J(θ) = θ + α∇logπ_θ(a|s)A(s,a) 其中 A(s,a) = Q(s,a)-V(s) = r + γV(s’) - V(s) = δ (实际上是无偏估计)
TRPO
- TRPO 是一种基于策略的方法 其核心思想是对模型的更新进行约束 从而保证模型性能单调不减 防止出现学习率过大导致模型性能下降的情况
- 信任域即对于模型参数更新的约束 在 TPRO 算法中 这个约束是基于 KL 散度的 即更新前后的策略 π 和 π’ 之间的 KL 散度不能超过阈值 δ 本质上也就限制了策略不能变化太多
- TRPO 将参数的优化转换为一个最优化问题 其约束就是上面提到的信任域 而目标函数则是 L(θ) = E[π’_θ(a|s) * A(s,a) / π_θ(a|s)] 根据证明可以得到 只要在约束内 L(θ)有所提升 那么模型性能 J(θ)必定单调不减 因此只需要用这个优化的 θ’ 来替换 θ 即可
- 实际应用中 上述最优化问题过于复杂 通常使用线性化的方法来简化 具体过程我也细看 在此不赘述
PPO
- PPO 是对于 TRPO 的一种改进 其主要思想是改进目标函数 使得计算复杂度降低
- 有两种类型的 PPO 它们都丢弃了 KL 散度的约束 对目标函数 L 进行了一定的修改
- PPO-Clip:使用一个剪切的目标函数 使得模型的更新不会超过一个阈值
- PPO-Penalty:使用一个惩罚项来约束模型的更新
- PPO-Clip 为目标函数中的 r*t(θ) = π’*θ(a|s) / π_θ(a|s) (也被称为重要性采样比率)添加了一个剪切项这使得如果策略分布变化过大 clip 会限制目标函数 L 的增长 从而梯度不会过大 也就限制了 θ 的更新
1
L_CLIP(θ) = E[min(r_t(θ)A(s,a),clip(r_t(θ),1-ε,1+ε)A(s,a))] - PPO-Penalty 则是直接在目标函数中添加一个 KL 散度的惩罚项其中 β 是一个动态变化的超参数 当 D_KL 过大时 β 会增大 反之减小 也就限制了 θ 的更新
1
L_PENALTY(θ) = E[r_t(θ)A(s,a)] - β * D_KL(π_θ(a|s),π'_θ(a|s)) - 两者的本质都是在限制目标函数 L 不会增长过大 从而限制 θ 的更新幅度
- 其中 PPO-Clip 算法在实际应用中效果更好 实现更简单
L18 - Optimization
Challenge
- Local Minima:局部最优是指在某个区域内的最小值或最大值 也就是梯度为 0 且 Hessian 矩阵大于 0 的点
- Saddle Point:鞍点是指在某个方向上是最小值 在另一个方向上是最大值的点 也就是梯度为 0 但是 Hessian 矩阵不是正定的点
- Vanishing Gradients:平坦区域是指梯度接近于 0 的区域 也就是梯度的范数非常小的区域
Learning Mode
- 在线学习:在线学习是指模型在每次接收到新的数据时都进行更新 而不是等到所有数据都准备好后再进行更新 这种方式可以减少内存的使用 但是需要注意模型的稳定性
- 离线学习:离线学习是指模型在所有数据都准备好后再进行更新 这种方式可以保证模型的稳定性 但是需要更多的内存
- BGD(Batch Gradient Descent):批量梯度下降是指在每次更新时使用所有数据来计算梯度 收敛更快 但是单个 epoch 的计算量较大 并且可能会陷入局部最优
- SGD(Stochastic Gradient Descent):随机梯度下降是指在每次更新时只使用一个样本来计算梯度
- Mini-batch Gradient Descent:小批量梯度下降是指在每次更新时使用一小部分样本来计算梯度
Optimization Algorithm
- SGDM(Stochastic Gradient Descent with Momentum):类似于物理中的动量 其会随着 epoch 不断积累 从而使得参数在梯度下降时具有惯性 可以加速收敛并减少振荡
- Adaptive Learning Rate:自适应学习率是指根据梯度的历史信息来调整学习率 使得模型在不同的参数上使用不同的学习率 这样可以加速收敛并减少振荡
- AdaGrad(Adaptive Gradient):根据每个参数的历史梯度来调整学习率 学习率和历史累积梯度平方和的平方根成反比 使得每个参数的学习率都不同 适用于稀疏数据
- RMSProp(Root Mean Square Propagation):类似于 AdaGrad 但是使用指数衰减平均来计算每个参数的学习率 使得学习率不会过小 适用于非平稳数据
- Adam(Adaptive Moment Estimation):结合了 SGDM 和 RMSProp 的优点 使用动量和自适应学习率来更新参数 适用于大多数场景
《机器学习》课程笔记
https://nwdnys1.github.io/2025/02/19/归档/ML/