SJTU-REINS
PHAROS
灯塔项目基于流控分离思想的无人机管理系统 希望通过云边协同计算框架对于无人机的整体态势进行计算和分析 让无人机自己通过安全空间等态势数据控制规划路径
CEDS
CEDS 是黄子昂学长的硕士毕业论文中设计的云边融合存储系统 大概包含以下几个部分:
边缘数据就近存储机制
大部分云边融合系统会将数据存储于资源富足可扩展的云端数据库中 但这会带来很多不必要的传输开销 利用边缘节点本身的存储能力 可以将数据就近存储 大大减少传输延迟
然而数据的就近存储会带来其他问题 比如原本全都位于云端中心的数据 由于就近存储就会分布在不同的边缘节点上 针对此问题 CEDS 提出一种基于 Rosetta 过滤器的全局索引机制 简单来讲 这个过滤器能够实现一个数据表内任一字段的范围过滤 即给定一个字段的某一范围 在常数时间内返回这个表是否存在这个范围内的数据 基于此种过滤器 加上基于时间划分的数据分表 可以做到在很短的时间内定位到某一个时间范围内的数据分表 并快速判断哪些分表内存在本次范围查询相关的数据 这就是 CEDS 的全局索引机制 基于此种索引 CEDS 在云端仅需存储数据表的元信息摘要(包括过滤器的 bitarray) 同时这也将为后文的查询下推提供便利
查询任务拆分下推
大部分云边存储系统基于边缘节点的存储数据 每次查询会将相关的数据表全部聚合到云端后进行筛选 产生了很多不必要的传输开销 CEDS 基于任务划分 将查询和聚合任务下推给各个相关的边缘子节点 减少带宽开销
具体而言 一次查询会先向云端中心索要本次查询可能涉及到的所有数据分表 以及这些分表存储在哪些边缘节点上 其方法可以简单的由之前提到的过滤器实现
获取到节点列表后 只需要把子查询任务分发给这些节点即可 每个子节点会进行相关的范围查询(节点内存在常规的索引来加快查询)并把查询结果返回 最终在查询节点进行数据聚合任务 把结果返回给用户
负载感知数据迁移
数据就近存储定会存在不均衡现象 由于查询任务划分给子节点并发执行 查询的延迟显然由查询时间最大的子查询决定 如果某些节点上的数据查询次数特别多 导致超出边缘节点的承受范围 导致子查询阻塞 就会导致所有涉及的查询延迟显著变高 为了防止此种情况出现 CEDS 会监测并记录每段时间内边缘节点的查询资源开销 比如记录前 3 分钟内某一节点的内存占用 一旦超过 1G 就判定存在热点数据 并将热点数据迁移到云端来减缓此节点的压力
此种策略是折中的策略 理论上可以达到最均衡的方案肯定是为每一个边缘节点根据查询开销动态分配性能资源 但这在现实中肯定不可行 因此使用较为折中的策略来解决数据不均衡分布的问题
技术栈调研
Redisearch
- 项目使用了 redisearch 建立设备数据的地理索引 实现实时数据查询的加速 即把经纬度作为 GEO 类型的元素编写索引
- 具体实现
- 文档参考:https://redis.io/docs/latest/develop/interact/search-and-query/indexing/(redis不同类型的索引如何使用)https://redis.readthedocs.io/en/stable/examples/search_json_examples.html#Projecting-using-JSON-Path-expressions(将 JSON 数据添加到索引的示例代码)
- redis 实例需要使用 redis-stack 项目中使用 python 因此安装 pip 库的 redis 即可
- 具体代码见项目中的
realtime_map.py文件 只需要先创建 schema 描述索引的字段类型 然后添加索引即可
Apache Avro
- 项目使用了 apache avro 进行数据的压缩 包括:
- 设备传输数据给 realtime_map 与 data_receiver
- 节点计算态势数据时向其他节点发送
/query请求查询 reatime_map - 节点通过消息队列传输态势数据给中心
- 具体实现
- 文档参考:https://avro.apache.org/docs/
- python 需要安装 avro 库 java 则通过 maven 导入 avro 依赖
- 需要预先编写好数据的 schema 语法见文档 编写好后即可使用 avro 的序列化与反序列化方法进行数据的压缩与解压
- python 中数据类型比较自由 使用 dict 类型即可操作 但是 java 的数据类型比较严格 avro 本身提供一个 record 类封装数据 但是我使用了 fastjson 库的 json 类型来操作数据 这就导致必须要编写一个转换函数进行转换 并且这个转换需要递归分类进行 一旦类型对应不上 序列化时就会报错
时空索引
- 时空索引是一种将时空数据进行编码以便于快速查询的技术 我们可以先简单认为时空索引需要解决这样的查询:查询某一个时间段内某个空间范围内所有的数据
- 先从空间索引开始说起 目前主流的空间索引可以分为三种:哈希、树以及空间填充曲线
- 哈希思想主要是通过网格哈希索引来实现的 也就是把已有的地理空间划分为网格 每个网格相当于一个哈希桶 哈希索引里就会存储每一个网格内有哪些数据 假如需要查询某一个范围内的所有数据 只需要先根据范围找到对应网格 然后再在哈希桶内找到对应数据即可 这个方案偏理论 实际工程不太用 对于灯塔项目 一个网格可能会有很多数据 尤其是不同时间段的数据 会导致哈希桶内数据量过大 失去意义
- 基于树的索引包括四叉树、R 树等
- 四叉树仍然是一种网格索引 但是它是一种递归的网格索引 不断四划分空间直到触发阈值为止 对于范围查询 四叉树需要递归的找到所有被包含的节点
- R 树是 B 树在高维空间的扩展 其结构很简单 适合静态空间对象的索引
- 先引入几个概念 BB 即 Bounding Box 是一个包含了空间对象的矩形 MBB 则是最小的 BB
- R 树的非叶子节点存放(BB,ptr)的键值对 叶子节点则存放(MBB,ptr)的键值对 叶子节点的 ptr 直接指向了空间对象数据的位置 其可以是质点 也可以是几何对象
- 需要进行范围查询时 R 树和四叉树一样 需要递归寻找被范围包含的节点
- 基于降维的索引通常使用空间填充曲线来实现 GM 部分已经详细讲过了 简单概括就是使用递归二分把高维数据映射到 bytearray 然后 Geohash 会通过 base32 编码得到字符串
- 加入时间维度后 有三种主流的实现方式 即基于时间分片、基于空间分片以及时空维度同时进行索引
- 基于时间分片是目前最主流的时空索引方式 比如 ES 使用空间填充曲线、PG 使用 R 树作为空间索引等 然后数据按照时间进行分片 个人认为如果灯塔的历史数据分析不需要跨很大的时间段 是可以使用这种方式的
- 基于空间分片即把空间网格化后分表 由于查询需求 很少被实际应用
- 时空同时进行索引 在 GM 中的 Z3 索引中有实现 大致可以理解为把时间也进行二分后和空间数据一起编码为 bytearray 在时空尺寸不匹配时会有严重的空间放大问题 详见京东 JUST 的论文
- 另外 轨迹数据比较适合空间填充曲线 R 树等基本可以不考虑 空间填充曲线若使用 B+树 可能仍存在写入性能差的情况 但是很多非关系型数据库采用的是 LSM 树结构 写入性能会好很多
- 综上 要么基于时间分片 要么时空一起编码
- 实际上 时空一起编码的索引 还是需要按时间分片 否则会有严重的空间放大问题
- 既然如此 就变成决定时间参不参与编码了
- 从感性上讲 我觉得时间参不参与不太影响查询性能 对于一个时空查询 其先会按照时间被分到不同分片上 中间的分片都是占满了时间段的 因此时间编码失去意义 只有两端的分片是可以用时间编码剪枝的 如果我们的查询时间范围总是大于一个分片的时间范围 那么时间参与编码意义是不大的
- 另外还有一个查询是直接 scan 还是先递归到基本分辨率后再 scan 的问题 我认为直接 scan 即可 因为磁盘上的随机访问仍然需要扫过未查询的数据 只不过省去了判断数据是否符合条件的过程 而递归查询范围这个过程可能本身就比较慢 JUST 是直接 scan 的
- 参考:https://zhuanlan.zhihu.com/p/663029637
GeoMesa
- GM 本身是一个类似于索引引擎的工具 首先需要选取合适的存储系统 要么 Redis 要么 HBase 等数据库 或者也可以直接通过 FS 存储 但是性能较差
- 现有的 redisearch 只支持 2d 数据的复合索引 要引入高度的话 可能只能遍历筛选 取决于独占空间部分需不需要 3d point
- 我们使用 GM 的目的是为了加速大量历史数据的查询 进行对历史数据的分析 而对于数据的写入与实时性并无要求 那么有两种方案
- 先考虑如何使用 mongodb 存储数据 然后通过 GM 进行查询
- 一种是保留现有的 mongodb 数据库 也就是近期数据仍向 mongodb 写入 然后定期(比如 1 天)把数据迁移到适合存储大量时空数据的数据库中(比如 HBase) 并且这个迁移过程通过 GM 实现(比如把 mongo 数据批量读到内存里 在通过 GM 写入 HBase)也就自动创建了时空索引 后续查询也就提高了性能 (代码量会小一点)
- 另一种则是抛弃 mongodb 直接通过 GM 持续写入数据 大致流程就是通过 mqtt 接受消息 把消息里的数据解析为 GM 的 simplefeature 类 然后通过 writer 写入 HBase 里 自动建立索引 省去了 mongodb 的部分 但是代码量会大一点
- 方便切换其他数据库指的是最后存储历史数据的数据库 索引层可以固定
- GM 现有的 API 都是大型分布式数据库 如果要测试 可以先部署两个容器试试
- GM 支持空间索引和时空索引 其中时空索引支持 2d point+时间 或是 2d 非 point(polygon line 等)+时间 其中 POINT 类型不知道是否支持 3d redis 由于本身不支持 3d 数据类型 所以没法存储 HBase 还没研究
- 原理部分
- GM 如何写入数据?(以 HBase 为例)
- 参考:https://zhuanlan.zhihu.com/p/164645879
- 插入一个 feature 时 进行以下几步操作
- 预处理 假如数据没有 id 生成 uuid 然后为数据添加合适的属性 方便插入 HBase 表 为了防止数据倾斜 最终对于 id 进行哈希 放入对应分区
- 计算索引值 GM 会找到数据的 geo 属性和 date 属性 提取出数据 计算索引值 其中时间数据为了适应 GeoHash 机制 采用了 BinnedTime 机制 即相对于 1970 年 1 月 1 号形成有限的 chunk 接下来开始计算索引 geo 数据为 double 类型 dtg 则为 long 类型 先进行标准化等处理后 最终通过编码得到索引值
- 索引值会被编码为 byte 数组 写入 HBase 表中
- 最后数据被序列化 写入 HBase 表中 默认使用 kryo 序列化 也可以使用 avro
- GM 如何进行数据的序列化?
- 参考:https://zhuanlan.zhihu.com/p/164647326
- 分两步 分别是序列化 feature 和 type 为什么需要序列化 type?因为插入数据时需要判断是否共用连接 GM 会把 type 序列化后存放在缓存里 方便后续反序列化出来进行判断 相当于一个全局的 schema
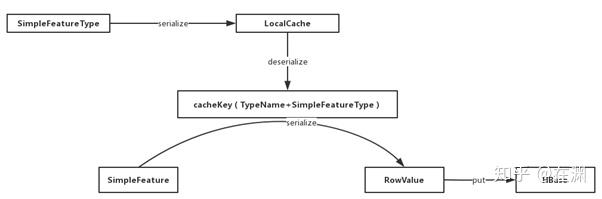
- 具体序列化过程略 可以视为和 avro 一样根据 schema 压缩为二进制数据
- GM 如何进行数据的索引?
- 参考:https://zhuanlan.zhihu.com/p/164748160
- Z2 索引:将二维空间编码为一维 以经纬度数据为例 通过空间填充曲线决定了数据的唯一顺序 也就映射到了一维整数上(这个过程相当于分别不断二分经纬度) 从而支持 1d 的键值索引 当需要进行 2d 的范围查询时 递归的寻找所有被区域包含的字符串 然后通过二分查找快速找到所有数据 或者对编码作主键建立 B+树索引
- Z3 索引:将二维空间和时间编码到一维 时间按照 time period 切分 取每一段内的 offset 作为二分的依据 然后和空间数据一起编码为 bytearray 这种方法具有显著的空间放大问题 后续会讲到
- XZ2 索引:将二维非点对象编码为一维 与 Z2 类似 通过找到空间对象的 mbb 来进行编码 相当于找到 Z2 编码中 mbb 的左下角方块的编码
- XZ3 索引:将二维非点对象和时间编码为一维 类似
- GM 如何写入数据?(以 HBase 为例)
TrajMesa
- JUST 的前身 基于 GM 实现的分布式 NoSQL 轨迹查询引擎
- 工作可以分为三部分:预处理、建立索引以及查询
- 预处理
- 建立索引与存储
- 论文提到 传统的垂直存储(也就是一个点存一行)对于轨迹数据来说不适合 包括查询一个轨迹比较慢、IO 次数多等问题 因此 TM 采用了水平存储 一行存一个轨迹 包括轨迹的元数据(mbr、时间范围等)、点 list(经压缩)、签名(一个 4*4 的编码来描述轨迹的形状)、其他属性
- TM 存在两份轨迹数据的副本表 分别是 IDTI 和 SRI 即 IDTQ 的索引表和 SRQ 的索引表
- IDTI 表的 Key 为
shard(随机数)+ 设备 id+BinNum(距离 RefTime 的第几个 Bin)+ EleCode(Bin 内的时间戳)+ 轨迹 id - SRI 表基于 GM 的 XZ2 索引实现 Key 为
shard + PosCode(与签名类似的 2\*2 编码 细化轨迹形状)+ XZ2(XZ2 产生的编码)+ 轨迹 id注意签名是基于 mbr 的 而 PosCode 是基于 XZ2 空间的
- IDTI 表的 Key 为
- 查询
- 支持 4 种查询:某一个设备在一段时间内所有轨迹的查询(IDTQ)、空间范围查询(SRQ)、相似性查询(SQ)以及 knn 查询(KNNQ)
- IDTQ:查询窗口=
可能的shard+设备 id+与时间范围相交的BinNum+每个Bin的偏移范围然后通过并发扫描 并删去不符合条件的轨迹 - SRQ:查询窗口=
可能的shard+与空间范围相交的XZ2编码+每一个XZ2子空间对应的PosCode - SQ 和 KNNQ 讲的比较晦涩 暂时没看懂
JUST
- 参考:https://zhuanlan.zhihu.com/p/300606530
- 基于 TM 作为底层存储的完整数据引擎系统 我们主要看其更新的时空索引部分
- Z2T 索引
- Z3 索引用于时空数据的编码 然而存在空间放大问题 即索引中时间的粒度过大 会涉及到很多不必要的数据 为了解决这个问题 JUST 提出了 Z2T 索引
- Z2T 索引很简单 就是把时间分片 索引变为
Num(T)+Z2其中 Num(T) 是时间分片的编号 查询时相当于先按时间范围剪枝 然后扫描 Z2 索引的 min-max 范围
- XZ2T 索引
- XZ2T 索引用于非点对象的编码 与 Z2T 类似 只是把 Z2 换成了 XZ2
- 我其实不懂上述索引和按时间分片有什么区别
- 除此之外 JUST 还实现了 SQL 查询和存储引擎 包括 Plugin Table(预定义 schema 的表)、View Table(缓存查询中间结果为 DF)
JUST-Traj
- 结合了 JUST 和 TrajMesa 的优点 实现了一个轨迹数据管理系统
- 索引
- XZ2+索引:即 TM 里 SRI 的索引 XZ2 再加上一个 PosCode
- XZT 索引:即 TM 里的 IDTI 索引 BinNum+EleCode
- XZ2+T 索引:按时间分片后的 XZ2+索引
其他时空引擎
- GeoMesa:支持各种分布式数据库以及本地 fs
- 基本原理如上 是把高维数据使用 Z 曲线编码为字符串 然后查询时使用递归 支持 2d+时间的索引
- 尝试过 cassandra 和 redis 查过文档 没找到支持 3d POINT 的方法 其 srid 也只支持 4326 也许默认只能用于经纬度
- 文档:https://www.osgeo.cn/geomesa/index.html
- PostGIS:是 PostgreSQL 的一个插件 支持空间索引 存储 3d 空间数据 甚至支持 GeoServer 接入
- 原理:有三种索引 GIST BRIN 和 SP-GiST 如果后续决定使用 可以做性能测试
- GiST 即通用搜索树 支持各种数据类型 PG 实际上是在这个基础上实现了 R 树
- BRIN 是一种轻量级索引类型 专为处理非常大的表而设计 它通过存储数据块范围(block range)的摘要信息 而不是每个数据行的索引值 从而显著减少索引的存储空间和维护成本 简单来说 有点像 LSM 树 存储了每个分块的最值 从而可以快速定位到某个范围内的数据
- SP-GiST 是一种支持分区搜索树的通用索引方法 意为空间分区的 GIST 适用多维空间数据 通过四叉树、kd 树等递归分割数据
- 文档中写到:坐标可以包含可选的 Z 和 M 坐标值。 Z 坐标通常用于表示高程。 M 坐标包含一个度量值,该值可以表示时间或距离。 如果几何图形值中存在 Z 或 M 值,则必须为几何图形中的每个点定义这些值。 如果几何图形具有 Z 或 M 坐标,则坐标尺寸为 3D; 如果它同时具有 Z 和 M,则坐标尺寸为 4D。
- 也就是说可以存储 4d 的 POINT(x,y,z,m) 并支持上述三种索引 我简单试了一下 是可以存储 4d 的 如果要使用 就考虑把时间数据进行分片 肯定不能存整个时间戳
- 文档:http://postgis.net/docs/manual-3.5/
- 原理:有三种索引 GIST BRIN 和 SP-GiST 如果后续决定使用 可以做性能测试
- Big Query:是 Google 的一个云数据仓库 支持 SQL 查询 支持空间数据类型
- 和 redisearch 有点像 支持存储 GEO 类型数据 并且进行空间查询 但是不支持时空索引
- 另外 google 的数据库区域基本都在欧美 而且要付费 甚至 api 可能还需要代理 基本排除这个方案
- 文档:https://cloud.google.com/bigquery/docs?hl=zh-cn
- Snowflake:是一个云数据仓库 支持 SQL 查询 和 Big Query 类似 支持 GEO 类型数据 以及一些空间查询 不支持时空索引 并且也需要付费 也可以排除
- RedShift:亚马逊的云数据仓库 亚马逊云账户需要绑卡 因此我没有做测试
- 看了下文档 和 PG 一样支持 ZM 的 POINT 类型
- 文档:https://docs.aws.amazon.com/redshift/latest/dg/welcome.html
- GeoLake:基于湖仓的空间数据层 没找到相关文档 看 github 介绍 应该是支持 ZM 的空间类型数据 但是没有提及时间数据
- GeoWave:和 GM 类似的索引软件 支持分布式数据库和 fs 等 支持 3 维空间数据和时间 并且可以选择多种索引 基本上 GW 对于分布式键值数据库就像是 PG 对于 PostgreSQL
- 试着用了一下 bbox 查询语法不支持 3 维 大概率不支持三维空间查询 不知道文档里说的支持 3 维存储和索引是什么意思
- 文档中介绍空间索引时也举了 3 维+时间的例子 原理和 GM 一样 递归分解 代码语法基本也和 GM 一样
- 文档:https://locationtech.github.io/geowave/overview.html
- python 接口:https://locationtech.github.io/geowave/latest/pydocs/
- Elastic Search:分布式搜索引擎 查看了文档 支持 geo 类型的空间数据 但是仅限于 2d 经纬度数据 可以通过复合条件查询实现 3d+时间的范围查询 不知性能如何
- 总结
- GM 和 GW 的索引原理差不多 GW 声称支持 3d 空间数据 但是还未找到用法 如果找到了则可以直接使用 另外 Z3 索引存在空间放大问题 可能需要测试性能
- PostGIS 支持 4d 空间数据 可以把时间数据分片后作为 M 维存储 但是需要进一步测试性能 GL 应该和 PG 差不多 但是前者显然更完善成熟
- 几个云数据库基本排除 都只支持空间索引
- ES 支持时空数据的查询 但是不清楚具体查询用到的索引如何
- 如果都不支持 自己实现 无论时间参不参与编码 都需要先把时间分片 我觉得时间参与编码意义不大 因为时间字段是可以自然有序的
GiST
- 参考:https://habr.com/en/companies/postgrespro/articles/444742/
- GiST 和 B+树类似 区别在于 GiST 的可扩展性 B 树只支持大于小于等于的比较操作 而 G 可以支持相对位置运算符(R 树的左侧右侧等) 亦或是 RD 树的交集等运算符 在某种意义上 我们可以认为 G 是一种接口 是各种索引实现的一个基础框架
- 结构:平衡树 所有叶节点的深度相等 每个节点代表一个集合区间(也就是一个谓词条件)且节点之间可以有交集 根节点是全集合区间 越往下集合区间越小 在搜索数据时使用 consistent 函数逐级作 dfs 搜索 将所有满足搜索条件的节点返回
- 基于 R 树:R 树将平面拆分为多个矩形 一个节点代表一个矩形 叶节点代表空间对象 一致函数则是判断矩形是否相交 如果对空间数据进行 G 索引 则采用 R 树作为基础
- 基于 RD 树:这是 PG 对于全文搜索采用的索引结构
SP-GiST
- 参考:https://habr.com/en/companies/postgrespro/articles/446624/
- 从名字可以看出 SP-GiST 是对于 G 的一种扩展 SP 指的是空间分区 SP 索引适用于任何值域空间可以递归划分为非相交区域的数据
- 结构:非平衡树 因为每个节点的区域都是不相交的 每个内部节点存储子节点的指针 以及一个前缀值(可以被视为是所有子节点都满足的谓词) 叶节点存储实际数据的指针以及数据的值 搜索过程仍然以 consistent 函数为基础 即递归判断节点的 prefix 是否满足搜索条件
- 基于四叉树:四叉树递归划分二维平面 内部节点的 prefix 即为四叉树的区域中心 叶节点则存储实际数据 可以是链表
- 基于 kd 树:kd 树递归划分多维空间 prefix 是 kd 树的划分线坐标 叶节点存储实际数据
- 基数树:基数树用于对字符串进行索引 prefix 是字符串的前缀 叶节点存储实际数据
- SP 索引不支持排序以及唯一性约束 不去不支持在多个列上建立
CODE
- 空间查询:https://postgis.net/docs/manual-3.5/using_postgis_query.html#using-query-indexes
- PG 的空间数据类型:https://postgis.net/docs/manual-3.5/using_postgis_dbmanagement.html#PostGIS_Geometry
- https://postgis.net/workshops/postgis-intro/3d.html
- 学会如何创建索引并进行查询了 其中 3d 空间查询需要使用 intersects 函数等来模拟 另外 没法使用 gevel 来查看索引表数据 不知道如何验证八叉树
FEDERATED LEARNING
- 背景与联邦学习相似 区别在于客户端上传的是扩散后的贝叶斯模型 由服务器进行数据生成和对齐 并训练模型
- 总体流程是
- 客户端通过本地数据训练一个贝叶斯模型 提取出了数据的特征
- 客户端将贝叶斯模型进行扩散处理 生成一个相似但是不同的贝叶斯模型
- 客户端将扩散后的贝叶斯模型上传到服务器
- 服务器用扩散后的贝叶斯模型进行数据生成和对齐
- 服务器将生成的数据进行训练
- 贝叶斯模型可以保留非线性的因果关系 而 PCA 只能表达线性关系
- 之所以不用 diffusion 直接生成数据 一是过于简单可能会被破解 二是直接 diffuse 数据可能会破坏表格数据的因果关系 而贝叶斯模型可以保留这点
背景知识
FL
- 联邦学习的背景是数据隐私问题 由于数据隐私问题 客户端无法将数据上传到服务器进行训练 然而世界上绝大多数可用数据都是私人数据 许多模型的训练已经面临数据稀缺的问题 因此谷歌提出了联邦学习的概念 期望数据可以保留在本地进行训练 将模型参数上传到服务器进行聚合 服务器将聚合后的模型参数下发到客户端进行进一步训练 最终收敛得到一个全局模型
- 联邦学习的基本流程
- 服务器下发初始的全局模型参数到客户端
- 客户端使用本地数据进行训练一个周期
- 客户端将训练好的模型参数上传到服务器
- 服务器将所有客户端的模型参数进行聚合 一种简单的聚合方法是对所有客户端的模型参数进行平均
- 服务器将聚合后的模型参数下发到客户端
- 重复 2-5 直到收敛
- 联邦学习可以调整的参数
- 客户端的选择:通常只会选择部分客户端进行训练
- 客户端的训练超参数:比如学习率、训练周期等
- 模型参数的聚合方式:平均、加权平均等
- 联邦学习本身并不能保证数据隐私 需要结合差分隐私等技术来保证数据隐私 比如对数据进行加噪声处理
- 联邦学习的类型
- 横向联邦学习:客户端之间的数据特征相同 但是数据量不同 比如不同医院之间的病人数据
- 纵向联邦学习:客户端之间的数据量相同 但是数据特征不同 比如同一批人在银行和医院的数据
- 联邦迁移学习:客户端之间的数据量和特征都不同 需要迁移到同一特征空间进行训练
GFlowNet
- GFlowNet 是一种新的生成模型 主要目的是采样出多样化且高奖励的样本
- GFN 解决的问题是过拟合 传统方法(比如 RL)往往追求一个最大值 这使得模型容易过拟合 在某些场景中 比如分子生成 会导致生成的分子不够多样化 而 GFN 生成的是一个分布 其中高奖励的分子具有高概率 保证了生成的分子多样性
- 采样的过程基于一个 DAG 节点代表状态 边代表动作 通过一个随机游走的方式来采样出一个分布 训练的目的是让汇点的流量与奖励函数相等 也就使得采样的分布与奖励函数成正比
- GFN 中的 Policy 是一个条件概率分布 代表了当前节点 s 采样到下一个节点 s’的概率 前向策略是从 s 采样到 s’的概率 反向策略是从 s’反推到 s 的概率 由此一条路径的采样概率可以表示为前向策略或反向策略的乘积
- 一般策略 P 用一个神经网络来参数化建模 输入是当前节点 s 输出是下一个节点 s’的概率分布 训练时 损失函数是基于流平衡条件的 也就是最终的策略会使得流量平衡 并且终态节点的流量与奖励函数成正比
Diffusion
- Diffusion 是一种新的生成模型 其主要思想是通过对数据进行加噪声处理 然后再去噪声来生成数据
- 模型包括 2 个部分
- 正向扩散:对数据进行加噪声处理 使得数据逐渐变为高斯分布
- 反向扩散:对数据进行去噪声处理 使得数据逐渐变为真实数据
- 正向扩散一般使用固定的加噪流程 比如生成高斯分布的噪声逐步添加到数据中 使得数据逐渐接近纯噪声
- 加噪声实质上是对输入数值和一个正态分布的随机数进行加权平均 这样的线性组合使得去噪非常简单 因此反向扩散往往学习的是噪声 而不是完整图像 大大减少了模型的复杂度
- 反向扩散则需要训练一个神经网络来预测噪声 即输入 xt 输出需要去除的噪声 然后从 x_t 中取出噪声得到 x{t-1} 反复迭代直到得到 x_0
- 反向扩散的损失函数一般是实际噪声和预测噪声之间的均方误差或 KL 散度等
- 当模型训练完毕后 可以通过一个随机噪声向量作为输入 经过反向扩散的过程来生成数据 这些数据会和训练数据特征相似
DALLE2
- DALLE2 是 OpenAI 提出的一个文本生成图像的模型 其主要使用了 CLIP 模型进行文本和图像的编码 然后使用 diffusion 模型进行图像的生成
- CLIP 是一种对比学习模型 其输入文本图像的 pair 包括正例和负例 通过对比学习的方式来学习文本和图像的共同表示 使得正确的文本和图像在特征空间中的距离更近 反之则更远
- 本质上有点像使用 CLIP 监督 prior 模型 来实现文本转图像向量 最后再用 diffusion 模型来实现图像的生成
GAN
- GAN 是一种生成对抗网络 其主要由生成器和判别器组成 生成器负责生成图像 判别器负责判断图像的真假 通过对抗训练的方式来优化生成器和判别器的参数
- 具体而言 生成器输入一个随机噪声向量 通过一系列的卷积层和反卷积层来生成图像 判别器输入生成器生成的图像和真实图像 做一个二分类来判断图像的真假 生成器的目标是骗过判别器 使得生成的图像被判别器判断为真实图像 判别器的目标是正确判断图像的真假
- 缺点包括
- 由于需要训练两个网络 训练过程不稳定
- 生成的图像多样性不足
Auto-Encoder
- Auto-Encoder 是一种无监督学习模型 其主要由编码器和解码器组成 编码器负责将输入数据编码为一个低维的表示 解码器负责将低维的表示解码为原始数据 由于模型只是在自训练 所以被称为自编码器
- DAE 是一种变种的自编码器 在编码前对输入数据进行加噪声处理 模型不容易过拟合 因为把冗余的信息去掉了
- VAE 是一种变种的自编码器 其编码器不再生成一个特征 而是生成一个高斯分布 使得模型可以进行采样 进行图片的生成
RL
- 强化学习属于机器学习中与监督学习和无监督学习并列的分支 其核心思想是在缺少标签数据的情况下 通过与环境的交互来学习一个策略 使得模型可以在给定的状态下选择一个最优的动作(或策略)
- 马尔可夫决策过程(MDP)是强化学习的基础模型 核心观念是马尔可夫性 也就是当前状态只与前一个状态有关 与之前的状态无关
- RL 的基本要素
- 状态空间 S:表示所有可能的状态
- 动作空间 A:表示所有可能的动作
- 策略 π:表示在给定状态下选择的动作 是一个条件概率分布
- 奖励函数 R:表示在给定状态下选择的动作所获得的奖励
- 回报函数 G:奖励随时间的积累 其中折扣因子 γ 用于控制未来奖励的权重
- RL 的基本流程
- 给定当前状态 s_t
- agent 根据策略 π 选择一个动作 a_t
- agent 执行动作 a_t 环境根据动作 a_t 转移到下一个状态 s_t+1 并返回奖励 r_t(需要注意 环境的转移可能是一个概率分布)
- agent 根据奖励 r_t 和下一个状态 s_t+1 更新策略 π
- 重复 1-4 直到达到终止状态
- RL 的目标是找到一个最优的策略 π 使得在这个策略下 回报的期望值最大化 这个期望值被称为价值函数 V_π(s) 即状态 s 下 之后持续执行 π 策略所获得的期望回报
- 除了状态价值 V 以外 还有状态动作价值 Q_π(s,a) 也就是在状态 s 下 执行动作 a 后 之后持续执行 π 策略所获得的期望回报
- Bellman 方程
- 任何状态下的回报期望都可以拆解为当前状态的即时奖励和下一个状态开始累积的未来奖励 这样的递归关系被称为 Bellman 方程
- V(s) = E[R_t + γV(s_t+1)|s_t=s]
- Q(s,a) = E[R_t + γQ(s_t+1,a’)|s_t=s,a_t=a]
- 寻找最优策略的方法
- 基于价值函数的方法:学习出准确的价值函数 然后让 agent 始终选择最大价值的策略 比如 Q-learning SARSA 等
- 基于策略的方法:直接学习策略本身 使得策略的长期回报最大化 比如 REINFORCE TRPO PPO 等
- 如何选择行动:前者使用 ε-贪婪策略来选择动作(前期探索 后期利用) 后者则直接按照动作的概率分布来选择
- 如何更新策略:前者基于贝尔曼方程更新价值函数 后者则会将对应策略的概率进行调整(比如获得正奖励就增加概率 负奖励就减少概率)
- 其中价值方法中更新策略包括 MC 方法和 TD 方法
- MC 方法:计算多个回合的平均值来估计价值函数 这使得模型方差较大 但是偏差较小
- TD 方法:使用即时奖励和 2 个估计值来估计价值函数 这使得模型方差较小 但是偏差较大
- 优化算法的超参数
- 更新频率:更新策略的频率 比如可以一回合更新一次 也可以每个时间步都更新
- 传播深度:更新策略时 向后传播多远 比如可以只传播到当前状态 也可以传播到更远的状态
- 优化公式:比如价值算法可以用 TD 也可以用 MC
Q-Learning
- Q-learning 是一种基于价值函数的方法 其主要思想是通过学习状态价值函数 Q(s,a) 来选择最优的动作
- 使用 ε-贪婪策略来选择动作
- 使用 Bellman 方程来更新 Q(s,a) 即
- Q(s,a)’ = Q(s,a) + α[R_t + γmaxQ(s_t+1,a’) - Q(s,a)] 其中 α 是学习率 γ 是折扣因子
- 可以看到 QL 假设下一步选定的是下一步状态中 Q 值最大的动作 并以此计算 Q 值的误差
- 这样的策略也被称为 off-policy 策略 也就是实际执行的策略和用于学习的策略不一致
DQN
- DQN 是 Q-learning 的一种变种 其主要思想是使用深度神经网络来近似 Q(s,a) 的值 而非使用表格来存储 Q(s,a) 的值
- DQN 包含三个部分
- Q 网络:输入状态 s 输出 Q(s,a) 向量 目的是学习实际 Q 值
- 经验回放:一个表格 存储 agent 过去的经验(s,a,r,s’) 通过随机采样来打破数据之间的相关性
- 目标网络:和 Q 网络结构相同 目的是学习下一个状态后的折扣 Q 值
- 具体流程
- 生成训练数据:
- agent 根据 ε-贪婪策略在 Q 网络的输出中选择一个动作 a_t
- 执行动作 a_t 观察到奖励 r_t 和下一个状态 s_t+1
- 将 (s_t,a_t,r_t,s_t+1) 存入经验回放表格中
- 重复一定次数 得到批量的训练数据
- 训练 Q 网络:
- 随机从经验回放表格中采样一批数据(s,a,r,s’)
- 输入状态 s 计算 Q 网络的输出 选取对应动作的 Q 值 即 Q(s,a)
- 输入状态 s’ 计算目标网络的输出 选取最大的 Q 值 即 maxQ(s’,a’)
- 计算损失 L = MSE(Q(s,a),r+γmaxQ(s’,a’)) = Σ(Q(s,a)-r-γmaxQ(s’,a’))^2 / batch_size
- 使用反向传播算法来更新 Q 网络的参数
- 更新目标网络:
- 重复 1、2 一定次数后 再将 Q 网络的参数复制到目标网络中
- 生成训练数据:
- 可以看到 DQN 基本遵循了原始的 Q-learning 的思想 其中
- 经验回放的作用是打破数据之间的相关性(可以满足独立同分布)并且神经网络需要批量数据来训练
- 目标网络的作用是避免 Q 函数更新过快 导致模型不稳定
SARSA
- SARSA 和 QL 的唯一区别在于
- SARSA 是 on-policy 策略 也就是实际执行的策略和用于学习的策略一致
- 也即 会在真正选择了下一步的动作后 才会更新上一步的 Q 值
策略梯度算法
- 策略梯度算法是基于策略的方法 其本质是梯度上升法
- 目标函数是:J(θ) = E[R|π_θ] 也就是在当前策略下的期望回报 在实际中 我们对这个策略进行多次采样得到批量的轨迹 τ 然后计算 J(θ)的梯度
- 策略梯度定理告诉我们可以用采样的轨迹来估计 J(θ)的梯度 具体推导比较复杂 公式如下:
1
∇J(θ) = E[∑∇logπ_θ(a|s)Q(s,a)] = E[∑∇logπ_θ(a|s)(r+γV(s'))] - 计算出梯度后即可更新策略:
- θ’ = θ + α∇J(θ) 其中 α 是学习率
Baseline
- 我们注意到整个梯度的计算中包含两项
- 第一项是 ∇logπ_θ(a|s) 也就是当前策略的梯度
- 第二项是 Q(s,a) 也就是当前状态下的动作价值函数
- 如果我们可以缩减某一项的尺度大小 就相当于给整个乘积值做了一个缩放 自然就可以减少方差
- Baseline 方法的核心思想就是将第二项减去一个基准值 b(s) 使得整体的方差变小 这个基准值需要保证无偏性 一般可以选择 Q(s,a)的均值作为基准值 也就是 V(s)
REINFORCE
- REINFORCE 是一种基于策略的方法 其主要思想是通过采样的轨迹来估计 J(θ) 的梯度
- 核心思想是
- 具体流程
- agent 根据当前策略 π_θ 采样多条轨迹 τ = (s_0,a_0,r_0,s_1,a_1,r_1,…,s_T,a_T,r_T)
- 对于每条轨迹的每一个时间步 t 计算 G_t = ∑γ^k-t * r_k (k=t+1,…,T)
- 更新策略 θ’ = θ + α∇J(θ) = θ + α∇logπ_θ(a|s)G_t
- 重复 1-3 直到收敛
- 可以看到 REINFORCE 的核心思想是使用 Monte Carlo 方法来估计 J(θ)的梯度 也就是通过采样的轨迹来估计 Q(s,a) 也就是说 轨迹的实际回报值 G_t = ∑γ^k-t * r_k (k=t+1,…,T) 代表着当前状态下的动作价值函数 Q(s,a)
- 由于 G_t 是一个随机变量 因此 REINFORCE 的方差较大 但是偏差较小 可以引入 baseline 方法来减少方差
Actor-Critic
- Actor-Critic 是一种结合了基于价值函数和基于策略的方法 其主要思想是使用一个价值函数来估计当前策略的价值 然后使用这个价值函数来更新策略
- baseline 方法提到过如何通过引入一个基准值来减少方差 而 A-C 算法中这个 baseline 就是状态价值函数 V 这使得梯度公式中的 Q(s,a)可以被替换为 Q(s,a)-V(s) 这个函数也被称为优势函数 A(s,a) 也就是在当前状态下 选择动作 a 的优势
- 我的理解:首先 V 是 Q 在不同动作下的期望值 因此 Q-V 不会改变整个期望值 然后 减去这个均值使得梯度中的后一项(Q(s,a)-V(s))的绝对值变小 这也就使得整个梯度项的方差变小了
- Actor-Critic 包含两个部分
- Actor:负责选择动作的策略网络 其输入状态 s 输出动作的概率分布 π_θ(a|s)
- Critic:负责估计当前策略的价值函数 其输入状态 s 输出价值 V(s)
- 具体流程
- Agent 执行一个时间步 t 得到(s,a,r,s’)
- Critic 根据当前状态 s 和动作 a 计算 V(s) 根据下一个状态 s’ 和当前策略的输出计算 V(s’)
- Critic 计算出 TD 误差 δ = r + γV(s’) - V(s)
- Critic 使用损失函数 L = MSE(δ) 来更新神经网络的参数
- Actor 更新策略 θ’ = θ + α∇J(θ) = θ + α∇logπ_θ(a|s)A(s,a) 其中 A(s,a) = Q(s,a)-V(s) = r + γV(s’) - V(s) = δ (实际上是无偏估计)
TRPO
- TRPO 是一种基于策略的方法 其核心思想是对模型的更新进行约束 从而保证模型性能单调不减 防止出现学习率过大导致模型性能下降的情况
- 信任域即对于模型参数更新的约束 在 TPRO 算法中 这个约束是基于 KL 散度的 即更新前后的策略 π 和 π’ 之间的 KL 散度不能超过阈值 δ 本质上也就限制了策略不能变化太多
- TRPO 将参数的优化转换为一个最优化问题 其约束就是上面提到的信任域 而目标函数则是 L(θ) = E[π’_θ(a|s) * A(s,a) / π_θ(a|s)] 根据证明可以得到 只要在约束内 L(θ)有所提升 那么模型性能 J(θ)必定单调不减 因此只需要用这个优化的 θ’ 来替换 θ 即可
- 实际应用中 上述最优化问题过于复杂 通常使用线性化的方法来简化 具体过程我也细看 在此不赘述
PPO
- PPO 是对于 TRPO 的一种改进 其主要思想是改进目标函数 使得计算复杂度降低
- 有两种类型的 PPO 它们都丢弃了 KL 散度的约束 对目标函数 L 进行了一定的修改
- PPO-Clip:使用一个剪切的目标函数 使得模型的更新不会超过一个阈值
- PPO-Penalty:使用一个惩罚项来约束模型的更新
- PPO-Clip 为目标函数中的 r*t(θ) = π’*θ(a|s) / π_θ(a|s) (也被称为重要性采样比率)添加了一个剪切项这使得如果策略分布变化过大 clip 会限制目标函数 L 的增长 从而梯度不会过大 也就限制了 θ 的更新
1
L_CLIP(θ) = E[min(r_t(θ)A(s,a),clip(r_t(θ),1-ε,1+ε)A(s,a))] - PPO-Penalty 则是直接在目标函数中添加一个 KL 散度的惩罚项其中 β 是一个动态变化的超参数 当 D_KL 过大时 β 会增大 反之减小 也就限制了 θ 的更新
1
L_PENALTY(θ) = E[r_t(θ)A(s,a)] - β * D_KL(π_θ(a|s),π'_θ(a|s)) - 两者的本质都是在限制目标函数 L 不会增长过大 从而限制 θ 的更新幅度
- 其中 PPO-Clip 算法在实际应用中效果更好 实现更简单
论文研读
联邦学习
- Causal Discovery with Reinforcement Learning
- 背景:从一组变量中发现因果结构是大量研究正在进行的工作 一大类的方法是基于评分的 通过为每一个有向图 G 指定一个评分 S(G) 并在 NPH 的搜索空间中寻找最优图 为了避免空间过大 某些方法依赖局部启发式方法强制无环性 论文提出使用强化学习搜索出最佳评分的 DAG 其中使用编码-解码模型从数据生成 DAG 图 并计算包含预定义和两个无环性惩罚的 reward 函数 最终通过策略梯度和随机化方法来优化模型
- 模型定义
- 核心公式为:xi = fi(xpa(i), θ) + εi
- 其中 xi 是变量 i 的值 xpa(i) 是 i 的父节点的值 θ 是参数 εi 是噪声(一般是高斯分布)
- f 可以是线性的(比如矩阵)或者非线性的(比如神经网络)
- 这里可以理解变量 i 是数据的一个特征或者一个属性
- 论文需要做的事情本质上就是通过数据集 X(包含多个 x 向量 代表采样的数据)来学习出 DAG 图的结构 以及每个节点的函数 fi
- 模型结构
- 从 X 中采样 n 个样本 Xl 重塑为 S 其中每一个向量代表了 Xl 中一列的值 我们希望通过 S 生成一个二元邻接矩阵 A 使得 A 是 DAG 且有最佳评分
- 编码器采用 Transformer 的编码器结构 记输出的向量为 enc_i
- 解码器是单层的 g_ij(W1,W2,u)=u^T*tanh(W1*enc_i + W2*enc_j) 其中 u 是可训练的 将 gij 输入 sigmoid 中 根据伯努利分布采样概率 得到 Aij 其中忽略所有的对角线元素
- 论文提到解码器还可以选择 Transformer 解码器等其他模型 但是单层解码器效果最佳 推测是因为编码器已经学习到了足够的信息
- 强化学习
- 使用 Actor-Critic 的方法来优化模型
- 预定义的评分函数采用了 BIC 评分 包含了两项 第一项是模型对于数据的似然函数 第二项是参数复杂度的惩罚项
- 无环性采用 h(A) = trace(e^A)-d 当 h=0 时 A 是无环的 另外因为 h(A)极小 为了避免使用极大的惩罚权重 添加另一个惩罚项来平衡
- 最终的 reward=-[S(G+λ1I(G 不属于 DAGs)+λ2h(A))] 其中 λ1 和 λ2 是可调的超参数
- 论文提到 新的 reward 作为优化 不一定等价于不带无环性惩罚的最大化评分函数的优化 为此 论文证明了当 λ1 和 λ2 符合某个条件时 两者是等价的 在实际应用中需要选取合适的 λ1 和 λ2
- Actor 包括了编码器和解码器 输入是采样的数据 S 输出是 DAG 其中编码器的输出 enc_i 作为解码器的输入
- Critic 是一个简单 2 层的前馈神经网络 输入为编码器的输出 输出是预测的 reward
- 训练时 目标函数 J 是即时奖励 即当前采样数据下此策略网络的期望奖励 可以认为折扣因子 γ=0
- 状态 s 可以理解为随机采样的数据 而动作 a 则是生成的 DAG
- Actor 的优化基于 REINFORCE 算法 具体而言 对 actor 作多次采样生成批量的 DAG 矩阵 然后计算 reward 也就可以估计出梯度 进行反向传播更新
- Critic 的优化则是使用均方误差来更新 也就是预测 reward 和实际 reward 之间的均方误差
- 最终遍历所有生成的 DAG 计算 reward 选择最优的 DAG 而非找到最优的策略网络
- 为什么论文不直接使用梯度上升法?因为奖励函数不可导 本质上是用 critic 来拟合奖励函数(注意是针对某一个完整数据集 X 拟合 reward 函数 而不是泛化到所有数据集生成的 DAG 可以理解为记住了数据集的特征来评估 DAG)
- 计算 reward 的耗时非常大 论文提到过记录已有的 reward 并且对 BIC 进行分解计算
- GANBLR: A Tabular Data Generation Mode
- 背景:GAN 是一种生成模型 但是在表格数据生成上存在可解释性不足等问题 论文将 GAN 的 ANN 架构替换为经典贝叶斯模型
- 具体而言 将生成器和判别器都替换为 BN
- FedTS(LZH)
- 背景:联邦学习中 边缘设备的计算资源往往存在差异 为了充分利用高计算资源 客户端需要引入不同复杂度的模型 也就导致了模型的异构性 fedts 通过知识蒸馏帮助大模型辅助小模型训练 解决了模型异构性的问题 现有研究基本上关注的是数据特征的异构性 并且传统蒸馏需要师生模型共享数据 违反了隐私保护的原则 就算是针对于模型异构性的研究 也需要额外数据集来蒸馏 带来了额外的计算开销
- 场景建模:k 个客户端 分为教师 T 和学生 S 其中 T 的计算资源较强 S 的计算资源较弱 模型为神经网络 进一步拆分为特征提取器 f 和分类器 g 师生共享相同的分类器结构 而在内部分别共享相同的特征提取器 目标是最小化所有客户端的损失函数之和
- 传统知识蒸馏的目标函数为师生模型分类结果分布的 KL 散度 问题在于需要共享数据集
- 解决问题的核心思想是在客户端之间共享生成器 G(代表了全局蒸馏出的知识) 具体而言 G 将标签 y 映射到特征向量 z 可以看做是分类器 g 的逆过程 但是是全局的
- 生成器 G 在聚合阶段(客户端上传模型参数之后)由服务器进行训练 从数据集中随机采样出 c 作为训练数据 目标函数是最小化所有客户端的 g 对于 G 输入 c 后输出的 z 与真实标签 c 的损失函数 简单理解就是让 G 尽可能泛化的拟合所有客户端 g 的逆过程 其中权重参数 w 控制 G 向不同客户端的学习程度 与数据集中的客户端样本数量成正比 并且通过 rk 控制师生模型差异 在迭代初期 教师模型占比较大 随着迭代进行 学生模型占比逐渐增大 最后 有研究表明高置信度的客户端有更高的学习价值 它们又往往具有较低信息熵 因此权重参数的最后一项是信息熵的倒数的 softmax 归一化
- 生成器 G 训练完后 其参数被下发给客户端 客户端在本地训练阶段将 G 用于知识库指导训练 f 和 g 本地客户端 k 的损失函数包括 4 项
- 本地数据集的损失函数 代表本地模型对数据集预测的误差
- 本地模型 f 与全局生成器 G 的损失函数 代表 f 与 G 的相似度
- 本地模型 g 与全局生成器 G 的损失函数 代表 g 与 G 的相似度 其中标签数据 ys 是全局随机采样的 保证 g 的泛化性
- 本地模型 f 输出的特征向量的正则项 用于获得更紧凑的特征空间
- 训练过程相当于利用了全局蒸馏的知识加速了本地模型的训练 一方面使得 f 可以生成正确的特征 另一方面使得 g 获得更好的泛化性
- 第 2 项中 如果本地数据集只包含某些类别的标签 那么其 f 模型应该是无法学习到其他类别的特征的
- 本地客户端训练需要下发 3 个模型参数 f、g 和 G 其中 G 模型由上一步训练完成 而 f 和 g 需要进行全局聚合
- 对于 f 直接采用数据集大小比例作为权重进行加权平均 分别对 T 和 S 聚合出 ft 和 fs(为何 f 可以直接加权?)
- 对于 g 若客户端之间的标签分布不均匀 会导致 g 的训练过拟合 此时不能简单按照数据集比例 pk 进行加权 调整后的权重 ak 除了需要接近 pk 以外 还需要考虑客户端的 g 与其他所有客户端的 g 的平均余弦距离 这使得和其他客户端差异越大的 g 权重越小 反之则越大
- 整体流程如下
- 初始化模型参数 f、g 和 G
- 选取样本客户端 k 进行本地训练
- 服务器通过客户端上传的 g 训练 G
- 服务器聚合 f 和 g 并下发给客户端
- 重复步骤 2-4 直到收敛
- EFFICIENT DIVERSITY-PRESERVING DIFFUSION ALIGNMENT VIA GRADIENT-INFORMED GFLOWNETS
- 背景:扩散模型已经被广泛应用于各种生成任务 现如今大部分扩散模型的规模巨大 因此人们往往希望基于已有的预训练模型进行微调 通常使用奖励函数进行 然而传统 RL 存在收敛慢 多样性不足的问题 即使使用 GFN 也仍有优化空间 论文提出一种基于奖励函数梯度信息与预训练模型和微调模型的残差信息的损失函数 实现了高效的微调
- GFN 的 DB 条件决定了损失函数 此外 GFN 和扩散模型天然具有可结合性 只需要将采样过程改为按时间采用即可
- 论文提出的第一个损失函数基于奖励函数的梯度信息 通过对原 DB 条件进行求导 可以得到前向和后向的 δ-DB 条件
- 仅仅通过 δ-DB 条件进行微调 可能会过度优化奖励 从而忽略了预训练模型的先验知识 若将微调模型和预训练模型的 δ-DB 条件相减 会消去相同的后向策略函数 可以得到残差 δ-DB 条件
- 论文还进一步用前向预测技巧优化了流残差函数 最终得到损失目标
- 可以看到 当前许多论文的研究方向都是找到一个合适的损失函数
- DAGNN
- GNN 是针对图输入的神经网络 而 DAGNN 则特化于 DAG 图
- 背景:MPNN 是基于消息传递的神经网络 其每一层输入的特征向量依赖于上一层输出的特征向量 以及对节点邻居进行聚合后的特征向量 DAGNN 在 MPNN 的基础上进行了改进 聚合操作的输入将依赖于当前层的父节点 这要求节点是可以拓扑排序的 符合 DAG 的特性 对于源点 聚合算子的结果是 0 另外 全局特征向量是每一层对于所有汇点进行池化后的输出
- DAGNN 同样融入了注意力机制 也就是会计算节点之间的注意力权重作为聚合时的加权系数
- DAGNN 引入双向处理 正向处理完毕之后 将 dag 反向 然后再对特征向量做一遍输入 得到的特征向量中 对汇点分别进行池化操作 然后拼接 相当于原图的源点和汇点
- 拓扑批处理 使得 DAGNN 可以通过并行加速训练
TODO
小论文
- 去掉联邦学习 主题变为数据发布
- 引用https://arxiv.org/abs/2211.06919
- INTRO 中的不足 放到相关工作中 并补充相关工作篇幅
- 形式化证明模型的隐私保护
- 基线模型需要加入隐私保护的方法(比如差分隐私等传统方法) 或者说明基线模型有针对隐私保护做处理
- 若实验成功 则加入威胁模型
- Intro
- 背景是当前机器学习任务缺少优质数据 因此有许多生成模型 但是需要隐私保护
- 新模型有哪些优势(对应贡献)
- 指标的综合评价 到最优点的距离?
毕设
- 实验
eps100只有covertype搞不定 先取出
PATEGAN 没有给出如何处理离散特征的方法 因此先用取整来解决 如果不行再使用 sigmoid+onehot+argmax 的方案
可能的对比实验:正则项是否需要?prob 取多少?模型复杂度需要调大吗?
连续特征:预处理用 stand√ minmax 还是 quantile?可以先用变分高斯模型拟合参数?可以对长尾分布的特征作对数预处理?设计条件生成?并关注一下连续特征是否优化的比离散特征更好(由于 nll 的尺度问题)
- ecoli 上 quan 和 stand 区分不大 因此在 concrete 上试了一下 发现 stand 指标更好
- 试了一下混合高斯分布 结果非常差 不太清楚原因
- 用 GS 相关性距离较差 有自环 相关性距离较差 其余指标差不多
- WD 和相关性距离上 0.6 明显差一点 0.7 0.8 略微好一点 ML 指标 0.6 略好一点 0.7 0.8 差不多 隐私指标 0.6 略微好一点 0.7 0.8 差不多
可以保留正则项 但是不强制无环图 W 可解释为特征之间的相关性程度 消融实验可以是与完全不用掩码的模型对比
从现实角度讲 原来阐述的单向因果关系存在局限性 比如一个简单的假设 x=3y 两个特征之间当然互相依赖 并且 x 的概率分布和 y 的概率分布也可以互相确定 模型在采样时 可以选择先采样 x 此时 x 根据边缘分布采样 然后根据 y 对 x 的依赖关系 采样出 y 反过来亦可 在这里我们用 mask token 代表未采样的语义 相当于告诉模型 此时你不能依赖特征 y 来采样 而应该直接根据边缘分布采样 至于为什么 x 和 y 都既可以根据边缘分布 也可以根据条件分布采样 是因为 x=3y 的关系中 x 具有某一个概率分布时 y 也就具有了一个确定的概率分布 反之亦然 两者都是可以通过边缘分布确定的 在具有更复杂的依赖关系的情况下 也可以先确定某些特征的边缘分布 然后根据依赖去确定剩下的特征 过程是随机的 总结一下 我们认为真实数据用简单的 DAG 也就是单向的因果结构来表示 是不足的 若双向的相关性表现为因果关系时 可以是先确定 x 然后采样 y 也可以反过来 也就是说这条边有时正向有时负向
现有评估隐私保护的思路则存在问题:假如隐私保护指标做不到最优 评委往往质疑你模型的性能 需要找出一个可以说服评委的 评估综合性能的方法 或是专门和隐私保护的 baseline 做对比?
PHAROS
理想空间:扣去固定建筑物以及其它无人机 即在大圈数据里加入安全空间即可
静态的元数据存一下 然后提供无人机能力数据和位置数据的 api
java 这边的 avro 由于我使用了 fastjson 导致需要先解析为 jsonobject 再进行使用 需要手动分类序列化 未来可以考虑直接使用 avro 的 record 类
avro 的压缩 如何自动生成 schema 文件?如何定义统一的 realtime_map 的 schema?(环境变量)
索引层
- 目前基于点存储查询写 以后可以拓展到轨迹数据
- 需要结合之前的查询下推实现中心的查询接口 目前用 http 简单实现
- cassandra 的表名不可以带斜杠 目前用下划线替代
- 目前 GM 的 schema 是固定为 taxi 的 后续加入转换逻辑适用于不同设备 转换逻辑可以是启动时发送请求获取 schema 然后存在内存里待用
- GM 的时间索引可能不如遍历筛选 未测试
边缘节点
- 向邻居节点发送请求可以并发 不过由于 http 有长连接机制 请求应该不会重新建立连接 且一个设备的计算最多也就发送 3 个请求(大多数情况是 1 个) 所以并发处理的意义不大
- realtime_map 中接收消息时的 time 和消息中的 time 有延迟 差不多是 2s 不知道为什么
- 节点刚好处于区域边界时可能会有问题 暂时没做测试
- 断开连接时如何告知节点 目前是心跳计时实现的 考虑是否要更加实时(反正会去重 其实无所谓)
- 数据格式变了导致 datahandler 需要重新写
中心
- 现在并发处理消息的逻辑比较简单 就是一个 List
里面存了 n 个单线程池 每次请求根据时间戳取模分配一个线程池处理 不知道是否均匀 - 中心下发态势数据是 for 循环+publish 不知道 mqtt 的 publish 是不是异步的 可能需要多线程或者至少保证异步发送
- 现在并发处理消息的逻辑比较简单 就是一个 List
安全空间
- jedis 中取出的 Document 类中的 properties 不知道为什么是$={}的格式 导致必须要解析 string
- center 与 sm 的通信需要发送独占空间 数据比较大 除了让 zhd 进一步压缩以外也可以使用 avro 进行压缩
FL
- 同态加密 隐私计算 SIGMOD ICDE VLDB 解决联邦学习的另一方向 b 站有视频
- 现在的架构基于隐私性和数据采样 如何扩展为多样性和数据增强?如何生成插值数据 原数据中不存在的值
Other
- 多智能体相关
- 查论文 谷歌学术 图书馆网站的电子数据库 VLDB ICDE SIGMOD ICDM EDBT 等会议 一是空间索引相关 二是查询优化 queryplan 清华李国良 ai 优化查询计划
- 后续可能要参与的工作
- SQL 生成 类似的 灯塔的索引层也可以通过自然语言生成查询 最终返回结果 其中转换过程自己定 比如 NL 转换为时空具体范围 然后进行查询 或者转化为具体的查询窗口 另外比较重要的是 要根据数据的存储进行优化 这个是比较抽象的 具体方式可以用本地的 LLM
- 发票的图神经网络 对于边敏感的神经网络可以用于识别行贿违法的 pattern 然后用模型学习并推理出哪些是异常的 另外还有个知识图谱
- kfm 在做查询下推相关 我可以看看相关论文 结合到索引层