《应用系统体系架构》课程笔记
预备知识:如何用 Docker 快速部署本地环境?
这门课程将会学习很多技术栈 同时也就势必需要配置很多环境 如果还像以前一样 前端用 npm 手动启动 后端用 IDEA 启动 数据库作为自启动服务 那么后续要装的环境只会越来越多 越来越难管理 不说系统盘会不会爆炸 启动一次完整的项目可能都要花半天 因此使用 Docker 来配置本地的环境 做到一键启动
从前端 Vite 项目开始
和服务器上的部署都类似 不过我们通常本地的操作系统都是 Windows 官方推荐安装一个图形化前端 Docker Desktop 链接放这里:https://docs.docker.com/desktop/install/windows-install/ 安装完后需要配置虚拟环境 网上文档里都有教学 我就不赘述了 本人是使用了 HyperV
还是编写 Dockerfile 和服务器上的部署不同 为了追求本地开发的效率 我们不能再通过先编译生成静态文件复制到容器内部来部署了 这样子部署 开发时无法热重载 代码更改看不到效果
考虑到本地开发 源代码都是在的 不妨利用挂载来进行热重载 因此采用下面的 Dockerfile:
1
2
3
4
5
6FROM node:18-alpine
WORKDIR /frontend
# 只设置启动命令
CMD ["npm", "start", "--", "--host"]也就是和本地一样直接启动
--host参数是用于暴露端口的 不设置的话宿主机无法访问这个端口然后编写一下 docker-compose 文件 和服务器上部署区别不大 加上一个挂载即可
1 | |
- 最后可以用命令行一键拉起 后续也可以在 Docker Desktop 里使用 GUI 来启动 里面还提供了终端、日志、浏览文件等功能 很方便
后端 Spring Boot
后端的思路是一样的 也是挂载后直接运行即可 注意 maven 的本地依赖也要挂载 要不然每次都需要重新下载 下面贴一下代码
Dockerfile:1
2
3
4
5
6
7FROM maven:3.8-openjdk-17
WORKDIR /backend
CMD ["mvn", "spring-boot:run"]
EXPOSE 8080docker-compose.yml:
1
2
3
4
5
6
7
8
9
10
11
12backend:
image: ebook-backend
container_name: ebook-backend
ports:
- 8080:8080
networks:
- my-network
volumes:
- ../backend:/backend
- E:/.m2/repository:/root/.m2/repository #挂载本地仓库
env_file:
- ../deployment/backend/.envps:本人测试后发现容器内编译+启动大概需要十几秒 而 IDEA 启动却只需要 3-4 秒 不知道这其中的差别在哪 因此还是采用 IDEA 来启动项目
MySQL 数据库
- 和服务器上部署无区别 另外提一嘴 既然服务器上已经部署了数据库了 其实就无需再在本地配置数据库容器了 直接连服务器方便又省心 Redis 也是同理的
9.23
谈谈应用架构
应用服务器首先为了安全考虑(比如数据库的端口不能暴露) 可以把应用和数据库、文件服务器等分开部署 通过内网访问 防止外网攻击
随后可以添加分布式缓存服务器 利用服务器的内存来增加读取速度 考虑到缓存需要少写 设计数据库时就可以把一张表拆分为只读数据和多写数据
请求一多 就需要负载均衡服务器来进行转发 比如 nginx 有一些新的问题就需要解决 比如分布式 session 的处理
数据一多 数据库就需要分布式部署 利用主从复制就可以做读的负载均衡 以及容灾备份 为了充分利用资源 可以轮流设为主节点 防止从节点过冷 为了保证主节点的可用性 还需要哨兵等中间件
图片音频一多 就需要 CDN 服务器来进行内容分发 为了单一访问 还需要一个反向代理服务器来代理这些 CDN 服务器
为了代码简单 可以把缓存、数据库、文件服务器的操作统一抽象成一个 API 形成统一数据访问网关
出现 NoSQL 数据库和搜索引擎后 数据访问的逻辑会更复杂 继续在网关里统一编写
为了处理异步通信 需要消息服务器
不同的应用服务器也可以提取出公共的服务 形成微服务架构 等待应用调用
服务的有状态和无状态
http 协议是无状态的协议 即没有办法记住用户的状态
有状态的服务是需要占用资源的 比如把实例放在内存里 但是不能无限扩大 如果要限制资源大小 又会因为 LRU 等策略导致缓冲池的抖动
因此 要尽量使用无状态的服务 保留必需的有状态实例
Spring Bean 的作用域(以一个 service 为例)
- singleton:全局单例(默认)
- prototype:每调用一次就创建一个新的实例
- request:每进行一次 http 请求就创建一个
- session:一次会话创建一个实例
- application:一个 ServletContext 生命周期创建一个实例
- websocket:一次 websocket 对话创建一个实例
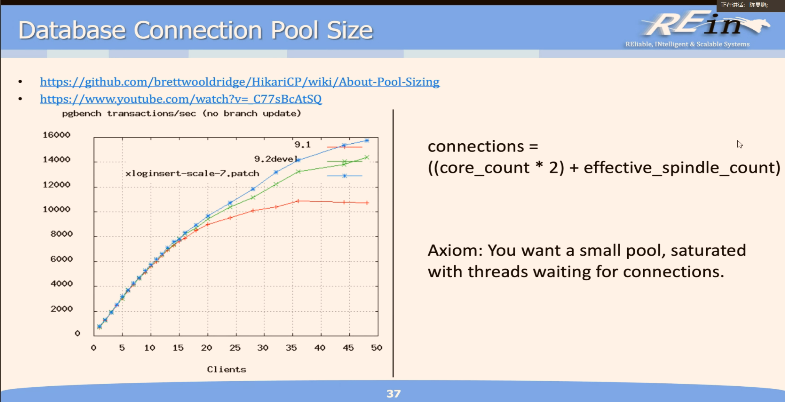
数据库连接池=核心数*2+有效硬盘数 与用户数无关 连接池本质上也是线程 超出 CPU 核心数会导致线程切换 降低性能 超线程可以使得一个核心同时处理两个线程 另外连接池实例除了连接 CPU 还需要 IO 因此再加上硬盘数
作业:会话计时器
- 在 Controller 和 Service 层都使用了 session 作用域的 scope
- Service 层使用 session 的原因:
- 用户会话保持的时间是一个状态 需要有状态的服务 使用默认的单例的话 每个用户获取到的 service 都是同一个实例 无法为每一个用户维护不同的状态 所以显然不用单例模式 同理的 如果选用 prototype 同一个用户每一次调用会获取到不同的服务 每次都会获得一个新的计时器 自然也不符合要求
- 而既然要求一个会话维护一个状态 那么 session 作用域是最好的选择 即一个用户如果有新的会话 调用的 service 就会新创建一个实例 做到一次会话对应一个计时器对应一个状态 实现为每一次会话记录持续时间
- Controller 层使用 session 的原因:
- 如果服务层使用了 session 作用域 而控制层却使用单例作用域 因为控制层只被创造一次 也就只进行一次依赖注入 也就是说控制层实际上只会调用同一个服务层实例 那么服务层的 session 作用域也就无效了 当然也可以手动注入 bean 但是单例的并发性能不好 同理如果是 prototype 作用域 多个 controller 也只会调用同一个服务层实例 是没有必要的
- 和服务层一样使用 session 作用域是最好的选择 同一个会话的所有请求对应控制层 这个控制层又会对应注入一个服务层
9.25
异步通信模型
为什么需要异步模型(而不用同步模型):
上层和接口还是紧耦合的
缺少调用保障
软件声明
没有请求的 buffer
过于强调请求响应模型
交流是不可靠的
通俗理解:同步模型下如果有超过服务器处理能力的高并发请求 所有超过阈值的请求都会被抛弃 而异步模型就可以塞入消息队列慢慢处理 直接响应用户 告知请求一定会被处理
如果请求数始终超过服务器能力 那么同步异步没有区别 都无法处理 只能提升资源
什么是异步模型:没有服务端和客户端之分 而是用消息中间件来处理异步信息 就好比你给室友发条 wx 叫他买早饭 你只需要发送出消息 不需要等待响应而阻塞 也不需要知道室友买早饭的过程
kafka 中有生产者和消费者 生产者(比如控制层)把消息放入类似缓冲区的 topic 区中 等待消费者(比如服务层)取出进行处理
客户端如何知道异步处理的结果?
- ajax 重新发一个请求确认
- websocket 推送
- 消费者完成任务后 把结果放入 topic 等待原来的生产者取出进行处理
java 提供一个 JMS 来进行消息处理 是异步且可靠的(一定会保障消息传输到)
JMS 消息的格式:
- 一个消息头
- 发送目标
- 发送模式
- 消息 ID
- 发送时间戳
- 相关消息 ID
- 回复给谁
- 有无转发
- 消息类型
- 过期时间
- 优先级
- 消息属性(可选 可以作为消息头的自定义扩展)
- 用户 ID
- AppID
- 转发数
- 组 ID
- 生产者和消费者的事务 ID
- 接受的时间戳
- 消息状态
- 消息体(可选)
- Text:一个 String 对象
- Map:一个键值对集合
- Bytes:一个字节数组
- Stream:一个流对象
- Object:一个可序列化的对象
- Message:上述五个消息类的父类
- 一个消息头
如何实现(JMS)
- 消息发布有两种类型 点对点和广播 一个通过 queue 一个通过 topic
- 向连接工厂获取一个连接 创建一个上下文和 JMS 服务器进行交互
- 通过上下文创建消息 进行发送和接受 发送时可以设置上述的 selector 接收异步的消息则需要创建一个 listener 来进行监听 在 onMessage 函数里编写处理操作
- 持久化订阅:创建一个持久化的消费者 订阅一个 topic 会把
所有未过期且未收到的消息接收 - 消息浏览器:只浏览消息 不消费
- 对于下订单 也就是控制层向某一个 topic 发送订单信息 服务层监听这个 topic 并消费每个订单消息
Apache Kafka
kafka 基于日志来存储消息 是只追加的数据 即使用时间戳来标记删除和更新 写的操作速度快
由于 topic 的消息是在内存中存储的 每个用户会维护一个目前读到的消息在内存中的偏移量 来保证每个用户读消息不会乱
topic 很大时可以用哈希分区 甚至可以形成集群 部署到不同服务器上 为了容灾还可以加复制因子参数 来进行备份
9.30
WebSocket
ws 是一个全双工的应用协议 即双向工作对等 底层是 TCP 协议
ws 应用会运行一个 endpoint 注册此 endpoint 的 uri 作为连接端点
连接建立包含两部分 握手和数据传输 使用 GET 向 endpoint 进行请求 会进行协议的升级 握手后协议升级为 ws
使用注解@ServerEndpoint 来注册一个 endpoint 作为服务端 OnOpen 函数中进行连接建立时的操作 OnMessage 函数进行收到消息时的操作 OnError、OnClose 同理
群发消息如果使用遍历是很慢的 因此需要把 sessionMap 开成并发安全结构 后续可以多线程处理
ws 支持自定义编码器 对于文本和二进制消息有两个接口 实现接口中的 encode 方法后即可自定义如何编码 同样也有解码器接口
通过编写 Message 类的子类 可以实现多种自定义消息类 在 decode 时就可以根据类别对应处理 多个 endpoint 就可以使用一个 decoder (也就是说 比如一个聊天室的 endpoint 一个点赞消息通知的 endpoint 聊天室可以有两种消息 Text 和 Image 点赞可以有一种消息 LikeM 三种消息都编码成文本 在同一个 decoder 里解码 分别解成三种子消息 然后根据消息类型分别处理)
对于下订单服务 当 listener 收到订单处理完成的消息时 应该把消息封装后通过注入的 ws 发送给对应用户 用户在前端需要先注册好 ws 服务 可以再下订单之前建立连接 收到 ws 消息后关闭连接
总结
- ajax 实现的是前端的异步处理 即用户点击发送请求后可以立即进行其他操作 收到响应后会自动处理
- 消息队列实现的是后端的异步处理 让服务的处理可以异步实现 由于异步无法使用响应让用户知道结果 就使用 ws 来实时通知用户
10.9
Transaction
基本概念
事务是一组操作的集合 保证这组操作要么全部成功 要么全部失败
事务的四个特性:ACID
- Atomicity:原子性 事务要么全部成功 要么全部失败
- Consistency:一致性 事务前后数据的完整性保持一致
- Isolation:隔离性 事务之间互不干扰
- Durability:持久性 事务一旦提交 数据就会永久保存
JTA 是 Java 提供的事务管理接口 使用@TransactionAttribute 注解来控制事务的传播属性
- REQUIRED:(默认)如果当前线程有事务就加入 如果没有就新建一个事务
- REQUIRES_NEW:无论如何都新建一个事务 这种属性可以让子方法的失败不影响父方法的事务
- SUPPORTS:如果有事务就加入 如果没有就不用事务
- NOT_SUPPORTED:不支持事务 遇到事务后挂起 当前方法执行完后再恢复
- MANDATORY:必须有事务 如果没有事务就抛出异常
- NEVER:不能有事务 如果有事务就抛出异常
- Spring 中此注解变为@Transactional(propagation = Propagation.REQUIRED)
事务的隔离
未隔离的事务可能会出现以下问题
- 脏读:事务 A 进行写入 写入过程中事务 B 读取到了未提交的数据 事务 A 后续进行了回滚 此时事务 B 读取到的数据就是不一致的
- 不可重复读:事务 A 读取第一次数据 之后事务 B 对同一个数据进行了写入 事务 A 再次读取数据时发现数据不一致
- 脏写:事务 A 进行写入 事务 B 也进行了写入 导致操作被覆盖
- 幻读:事务 A 需要查询满足某些条件的数据 在查询一次后 事务 B 插入了一条新的符合条件的数据 导致事务 A 再次查询时发现数据增加了新的“幻影”数据行
使用@Transactional 的 isolation 属性来设置隔离级别(从上到下隔离级别逐渐增高 常用可重复读)
- READ_UNCOMMITTED:允许读取未提交的数据 会出现脏读、不可重复读、幻读
- READ_COMMITTED:只能读取已提交的数据 避免了脏读 但是会出现不可重复读、幻读
- REPEATABLE_READ:确保同一事务内多次读取同一行数据是一致的(也即正在被读取的数据不能被修改)避免了脏读、不可重复读 但是会出现幻读
- SERIALIZABLE:事务完全串行化(为各个数据项上锁 甚至为表上锁)避免了脏读、不可重复读、幻读 但是性能较差
多数据库的写入
- 当存在多个数据源时 Tomcat 会自动使用分布式的事务 采用两阶段提交 第一阶段向所有数据库询问是否准备好 第二阶段若所有数据库都准备好则提交 否则回滚 此种处理仍会出现错误 但是概率较低 可以人工处理
锁机制
- 乐观离线锁:数据会被用户 session 读取后离线编辑 在写入更新数据时先查询数据的版本号 然后在更新时判断版本号是否一致 如果不一致说明基于旧数据进行了修改 则不进行更新 否则更新数据 并将版本号+1 适用于写远少于读的场景
- 悲观离线锁:加上写锁 保证只有一个线程可以写入数据 适用于写入操作频繁的场景
- Coarse-Grained Lock:粗粒度锁 一次锁住多个数据
- 乐观锁:给关联的对象加上共享的版本号(可以是内存也可以持久化) 如果对象的版本号被修改 其关联的对象将不能写入
- 悲观锁:给版本号上锁 保证只有一个线程可以写入
注:@Transactional 注解只能对于资源管理器(比如数据库 消息队列)事务有效 对于非资源管理器事务(比如局部变量 x++)无效
10.16
事务管理
- 事物的回滚和提交实际上是资源管理器通过 redo log、undo log 来实现的
可串行化调度
- 调度:并发事务的执行顺序
- 串行调度:事务完全按照顺序执行
- 并发调度:事务可以并发执行
- 可串行化调度:并发执行的事务的结果和串行执行的结果等价 则称这个并发调度是可串行化的 可串行化调度太多 通常只找子集
- 等价交换:两个事务交换位置后结果不变 比如交换两个读、交换两个不同数据的读写
- 冲突可串行化调度:通过等价交换把一个并发调度转化为串行调度 即可证明这个并发调度是可串行化的
- 无冲突的调度可以使用等价交换转换为串行调度 有冲突的调度则需要使用冲突图来判断是否可串行化
- 冲突图:事务之间的冲突关系 用图表示 有向边表示冲突 无环则可串行化
事务提交和回滚
数据库恢复机制:无非是单机多副本、主从复制、异地多机灾备等
策略
- 原子性
- 窃取:未结束事务可以将脏页落盘 占用内存少 但是影响原子性 需要 undo log
- 非窃取:未结束事务不能将脏页落盘 不影响原子性 占用内存多
- 持久性
- 强制:已完成事务必须落盘 不存在持久性问题 但是 IO 开销大
- 非强制:已完成事务可以不落盘 但是可能会丢失数据 需要 redo log
- 原子性
日志
- redo 用于持久性 undo 用于原子性
- 日志是磁盘文件 但是由于写入日志是不修改的 可以顺序写入 速度很快 比数据库的写入快很多
- 日志记录了每一次数据库的操作 包括事务的开始和结束范围等
- 按功能分类
- Undo Log:格式为<事务 ID 数据项 数据旧值> 用于回滚 在数据库写入之前写日志 一般还包含一个日志序号 LSN(Log Sequence Number)用于记录日志的顺序 可以是逻辑日志或物理逻辑日志
- Redo Log:格式为<事务 ID 数据项 数据新值> 用于重做 必须是物理日志
- 按性质分类
- 逻辑日志:记录事务中高层抽象的逻辑操作 相当于 SQL 语句 比如小明的账户减少了 100 元 不是幂等的 不能重复执行
- 物理日志:记录数据库的具体物理操作 比如某个页面的某个 offset 的数据由 A 改为 B 是幂等的 可以重复执行
- 物理逻辑日志:记录数据页面的物理信息 但是记录的是逻辑操作
- 日志的性质
- 幂等性:重复执行不会产生不同的结果 逻辑日志不满足
- 失败可重做性:日志执行失败后 可以通过重做达成恢复 逻辑日志不满足 因为一条逻辑记录可能对应多项数据修改 比如数据表和索引
- 操作可逆性:逆向执行日志可以撤销操作 物理日志不满足 因为数据页的偏移可能已经被修改 而物理逻辑日志可以通过页面前后指针来完成回滚
10.19
事务管理
- 数据库恢复方法
- 影子拷贝方法:所有写操作会在一个拷贝数据库上进行 提交事务时切换数据库指针 效率很低 难以支持高并发
- 基于 Undo Log 的恢复方法:恢复时找到所有未结束(需要回滚)的事务 反向扫描 undo log 恢复数据
- 基于 Redo Log 的恢复方法:恢复时找到所有已提交的事务 正向扫描 redo log 恢复数据 需要通过 checkpoint 机制来判断是否刷盘
- 补偿日志:Undo 日志的 Redo 日志 因为 Undo 是不具有幂等性的 不能重复执行 所以需要记录撤销动作 当 Undo 过程时又发生崩溃 保证 Undo 日志不会重复执行
多线程
如何创建一个线程实例(推荐使用第一种 因为 java 里一个类只能扩展一个类)
- 提供一个 Runnable 接口的实现类 重写 run 方法
- 扩展 Thread 类 重写 run 方法
Thread 类的方法
- sleep:让线程休眠一段时间 可以认为时间是准的
- interrupt:中断线程 会抛出一个中断异常 interrupted 则是判断是否被中断
- join:当前线程会阻塞的等待此线程执行完毕 参数是等待时间
- wait:让线程等待 直到被唤醒 会释放锁
- notify:唤醒一个等待的线程
Synchronized:一个关键字 修饰的方法或者代码块带锁 只有一个线程可以执行
- java 里其实每一个对象都有一个锁 sychronized 就是获取这个锁
- 每一个类也有锁 所以调用类的 static 方法也是保证同步的
- Reentrant Synchronized:可重入锁 一个线程可以多次获取同一个锁 用于递归和嵌套调用 防止产生死锁
原子性:java 规定 除了 long 和 double 以外的基本类型的读写是原子的 加上 volatile 关键字可以保证原子性
Liveness:活性 一个线程不会永远等待下去
- 死锁:两个线程互相等待对方释放锁
- 饥饿:一个线程一直无法获取到锁
- 活锁:两个线程因为不断响应而无法继续执行 并非阻塞
Guarded Blocks
- 单纯使用 while 循环来判断条件 确保线程间的协调 然而会浪费资源
- 注意 自旋锁并非完全无用 当线程的等待时间非常短 短到开销小于线程切换的开销时 自旋锁是更适合的选择
- 更有效的方法是使用 wait 和 notify 来进行线程间的通信
- wait 会使当前线程等待 并释放所有锁 notifyAll 会唤醒所有等待的线程 并使得其中一个线程获得锁 以此进行线程间的通信 常见的例子是生产者消费者模型 当队列为空 消费者等待 等生产者生产后通知消费者
Immutable Object:不可变对象 一旦创建就不能修改 适合多线程环境 因为不知道用户会如何读取数据 为了防止其他线程在读取时修改数据 只能把数据设为不可变 比如 final 和 private
10.21
高并发对象
- Lock Objects
- Executors:提供线程管理和创建 本质上就是一个线程池
- 并发安全的集合:比如 ConcurrentHashMap、CopyOnWriteArrayList
- Atomic Variables:原子变量 比如 AtomicInteger、AtomicLong
- ThreadLocalRandom:线程安全的随机数生成器
- Virtual Threads:轻量级线程 由于 OS 的线程数量有限 多个虚拟线程会复用一个 OS 线程 比如 server 就可以为每一个 client 连接创建一个虚拟线程
缓存
Memory Cache
- 为什么要手动管理
- 数据库自带的缓存不可控制 而且不在同一个进程中 而且很难做分布式缓存
- MemCached 可以缓存非数据库数据 比如一个请求的结果
- 比如 stock 这样多写的数据字段 不应该放到缓存里 应该从 book 类里拆分出来
- memcached 会把 chunk 根据大小不同分为很多等价类 选择合适大小的 chunk 来存储数据
- 分布式缓存首先节点间无需通信 只需使用哈希算法来确定数据位于哪个节点即可 需要用一致性哈希来进行数据分片 保证增加减少节点时数据的迁移量最小
- 缓存达到上限时 可以使用 LRU 直接删除缓存 也可以驱逐到磁盘上 因为可能是计算后的结果数据 所以还是比普通的请求要快的
Redis
- Redis 支持的值类型比较多 比如字符串、列表、集合、有序集合、哈希表 另外还支持主从复制和持久化
- Redis 还可以用于消息队列 把 Redis 当做一个发布订阅的中间件
- 11.25 补充
- Redis 需要设置 expire 时间 为了防止雪崩(一次性过期大量数据) 可以设置随机的过期时间
- 同时有大量的请求读取数据 会发生击穿问题(同时查询同一个数据) 可以使用互斥锁来解决 即第一个线程先把数据 load 到缓存里 后续线程就可以直接从缓存里读取
- 查询一个不存在的数据时 会发生穿透问题(每次都要查询数据库) 可以使用布隆过滤器来解决
10.23
Searching
文本的存储
- char:固定长度的字符 不管几个字符 都占 100 个字节
- varchar:可变长度的字符 只占用实际长度的字节 需要额外存储长度和偏移量
- text:可变长度的字符 不限制长度 实际上是存储一个指针指向一个存储在其他地方的数据
用 like 进行模糊查询时 会导致全表扫描 会很慢 先把文本数据结构化 建立关键词到 id 的反向索引
Lucene
Lucene 是一个 IR(Information Retrieval)工具包 提供了索引和搜索的功能 由 Apache 维护 适用于 Java 项目
Lucene 会为文本数据建立索引文档 存储到磁盘上 查询时搜索索引来找到文本数据
Lucene 的索引文件结构(注意 文档相当于数据库的一行记录)
- .fnm:<字段名,是否索引,是否向量化> 向量化是为了计算文档的相似度 实现这个字段的模糊匹配
- .tis:<字段名,记录值,文档频率> 记录值是字段的值 文档频率是这个记录值在多少文档中出现过 每一条记录值指向.frq 文件里的多条记录
- .frq:<文档 ID,出现频率> 每一条记录值指向.prx 文件里的多条记录
- .prx:<位置>
搜索的质量可以用召回率和准确率来衡量(recall & precision)
- 召回率=结果中正确的文档数/所有正确的文档数
- 准确率=结果中正确的文档数/结果中的文档数
Index Flie Formats
基本概念
- Index:一组文档的集合
- Document:一条记录 由多个 field 组成
- Field:一个记录的某个字段 包含多个 terms
- Term:一个词 不同字段下的同一个词是不同的 term
Inverted Index:倒排索引 指的是从 term 到 document 的映射 即一个 term 在哪些 doc 中出现过
一个 field 可以被 stored 或 indexed 如果被 indexed 可以被作为搜索的条件 如果被 stored 则在搜索出这个文档时 可以带上这个字段的值
Types of Fields
- TextField:文本字段 会被分词器分词
- StringField:字符串字段 不会被分词器分词
- IntPoint
- LongPoint
- FloatPoint
- DoublePoint
- SortedDocValuesField:用于排序的字段 以下四个都是
- SortedSetDocValuesField
- NumericDocValuesField
- SortedNumericDocValuesField
- StoredField:存储字段 不会被索引
Segments:index 太大时可以分段 分布式的存储到不同位置 比如可以按照某一个字段
time来分段 查询时就可以剪枝 和数据库的分区类似Document Number:文档的编号
Query
- TermQuery:单个字段、单个 term 的查询 不可以再分词
- BooleanQuery:多个查询的组合
- PhraseQuery:短语查询 匹配多个 term 的序列
- MultiPhraseQuery:多个短语的查询
- PointRangeQuery:范围查询 针对数值类型的查询
- PrefixQuery:前缀查询
- WildcardQuery:通配符查询
- RegexpQuery:正则表达式查询
- FuzzyQuery:模糊查询
Scoring
- 对于一次查询 可以对查询结果中的文档进行相关性评分 来展示最相关的文档 Lucene 支持自定义评分的模型 下面是几种默认的算法
- BM25:基于词频和文档频率的评分算法
- TF-IDF:词频-逆文档频率
- 评分=(词频*逆文档频率*字段长度归一化*字段权重)求和
- 词频是指一个词在此文档中出现的次数 比如 TOM 在 BOOK 中出现了 3 次 而 AND 在 BOOK 中出现了 30 次
- 逆文档频率是指一个词在所有文档中出现的次数的倒数 比如 BOOK 在所有的查询结果中一共出现了 1000 次 那么逆文档频率就是 1/1000
- IDF 相当于这个关键词的权重 一个关键词在所有文档中出现的次数越多 说明其对于查询的重要性越低 保证了一些常见词的权重降低
- 长度归一化(可选)是指对于不同长度的文档进行归一化 因为文档字段越长 容易出现关键词的次数越多 相当于词频变为了关键词出现的概率
- 字段 boost 权重(可选)是用户人为对于某一个字段的权重进行调整 比如 title 字段比较重要 可以给 title 字段的权重增加一些
- SimilarityBase:提供基类 用户可以继承这个类来实现自己的评分算法
- 对于一次查询 可以对查询结果中的文档进行相关性评分 来展示最相关的文档 Lucene 支持自定义评分的模型 下面是几种默认的算法
SOLR:对于 Lucene 的封装 提供一个 web 页面平台进行手动搜索
Elasticsearch
- 全文搜索 实时性好 字节目前在使用 原理是建立宽表 即关键字到 id 的反向索引
10.28
Web Services
Overview
- Web 指 web 协议 即不同协议都可以访问服务
- Service 指无视 OS 和语言的服务 一个接口可以实现多种协议的服务 独立于具体的实现
SOAP WS
SOAP(Simple Object Access Protocol):用于在网络上交换结构化的和类型化的信息 SOAP=XML+HTTP 即把 http 请求以 xml 格式发送
1
2
3
4
5
6
7
8
9<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope">
<soap:Header>
</soap:Header>
<soap:Body>
<m:GetStockPrice xmlns:m="http://www.example.com/stock">
<m:StockName>IBM</m:StockName>
</m:GetStockPrice>
</soap:Body>
</soap:Envelope>其中的 Envelope 是必须的 Header 是可选的 Body 是必须的
WSDL(Web Services Description Language):描述 web 服务的接口和实现的 XML 文档 结构类似于下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36<definitions name="StockQuote"
targetNamespace="http://example.com/stockquote.wsdl"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:tns="http://example.com/stockquote.wsdl"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<message name="GetLastTradePriceInput">
<part name="body" element="xsd:string"/>
</message>
<message name="GetLastTradePriceOutput">
<part name="body" element="xsd:string"/>
</message>
<portType name="StockQuotePortType">
<operation name="GetLastTradePrice">
<input message="tns:GetLastTradePriceInput"/>
<output message="tns:GetLastTradePriceOutput"/>
</operation>
</portType>
<binding name="StockQuoteSoapBinding" type="tns:StockQuotePortType">
<soap:binding style="document" transport="http://schemas.xmlsoap.org/soap/http"/>
<operation name="GetLastTradePrice">
<soap:operation soapAction="http://example.com/GetLastTradePrice"/>
<input>
<soap:body use="literal"/>
</input>
<output>
<soap:body use="literal"/>
</output>
</operation>
</binding>
<service name="StockQuoteService">
<port name="StockQuotePort" binding="tns:StockQuoteSoapBinding">
<soap:address location="http://example.com/stockquote"/>
</port>
</service>
</definitions>其中的 message 是消息的定义 portType 是接口的定义 binding 是绑定的定义 service 是服务的定义
- 系统 B 将一个接口通过 WSDL 文件暴露在网络上 其同时会生成一个代理 负责将 SOAP 消息转换为调用接口的方法 系统 A 先获取 WSDL 文件 然后生产一个代理类 其负责将方法调用转换为 SOAP 消息 并发送给系统 B 得到 SOAP 消息后 代理类会将其转换为方法的返回值
- 通常 SOAP 消息是通过 HTTP 的 POST 请求发送的 请求体内是一个 XML 文件
- 在 spring 中 可以使用
@WebService注解来暴露一个服务 会在指定 url 暴露 WSDL 文件 消费者只需要 wsimport 即可在本地当做一个类来调用
RESTful WS
- REST(Representational State Transfer):一种软件架构风格 设计风格而不是标准 通过 URI 来定位资源 通过 HTTP 方法来操作资源
- Representational:资源有不同的表示形式 每个资源都有一个唯一的 URI
- State:客户端的状态 即资源的表示形式 客户端自己维护
- Transfer:客户端的表示随着 URI 的变化而转移
- How to Design RESTful API(CRUD)?
- 用 method 来区分操作 用状态码来表示操作结果
- Create:POST
- Read:GET
- Update:PUT
- Delete:DELETE
- Advantages of REST
- 格式简洁 适合轻量级应用 不像 SOAP 那样需要复杂的解析 因此性能也更好
- 无状态 减轻了服务端的压力
- 数据驱动型 返回结果依赖于客户端的请求 降低了服务端的压力
- C&S 之间传输的只有数据 降低带宽使用
- 语义明了 易于学习 对程序员友好
- 除了 POST 请求外 其他请求都是幂等的 即多次请求的结果是一样的
Trade-offs
- Advantages of WS
- 跨平台跨语言
- 自描述性 使用 WSDL 可以很容易了解服务的参数和返回值
- 模块化
- 跨防火墙 通过 HTTP 和 HTTPS 可以穿透防火墙
- Disadvantages of WS
- 低生产力 需要多写很多代码 不适合单机应用
- 低性能 需要封装和解析 而且是纯文本传输 浪费带宽
- 不安全 需要 HTTPS 等其他方法
10.30
Micro Services
- 什么是微服务:将一个大型的应用拆分成多个小的服务 每个服务都可以拥有自己的数据库和接口 通过 HTTP 或者消息队列来通信 Spring Cloud 是最常用的微服务框架
- 为什么要使用微服务:高生产力(模块化便于开发)、高可扩展性、高可靠性(多个实例)、高可维护性(只需针对出问题的服务进行维护)
Spring Cloud
组成
- 服务发现:服务注册中心会把注册的服务信息保存 类似于<服务名,ip,端口>的键值对 使用网关来转发对应服务名的请求到对应的 ip 和端口
- 负载均衡:同样使用网关来实现
- 断路器:当某个服务不可用时 断路器会打开 避免请求堆积
- 监控:监控各个服务的状态并收集日志 用链路跟踪来确定哪个服务出了问题
- 消息队列(可选):使用消息队列来实现客户端和服务端的通信 减少微服务的延迟带来的影响 一个服务对应一个 topic
Eureka
- 一个服务注册中心 用于注册和发现服务
- 只需要加入依赖 配置端口 在服务模块里加上
@EnableEurekaClient注解即可注册服务
Spring Cloud Gateway
- 一个网关 用于转发请求到对应的服务
- 可以配置路由规则 对符合规则的路由进行各种处理 比如添加请求头、重定向等
- 微服务框架中可以用于客户端请求转发给对应的服务 比如
/api/book/**转发给book-service/**而book-service会被解析为 ip 和端口
Spring Cloud Function:一个用于构建无服务器应用的框架
- 什么是 Serverless:无服务器计算 无需维护状态 是一种事件驱动的计算模型 FaaS(Function as a Service)是一种 Serverless 的实现
我的理解就是把业务处理函数(比如图片处理)单独拆分出来作为一个微服务 让其他服务调用 如果是传统的服务模式 需要自己维护状态和调用(比如涉及到数据库的操作) 而无服务器模式则是无状态的 只需要传入参数和返回结果
- 只需要在函数上加上
@Bean注解即可将函数注册为一个服务
11.4
MySQL Optimization
Index
- 把数据表的某一个或多个字段的值作为键 实际数据行的指针作为值 存储在一个 B+ 树中 从而做到对数时间的查找
- 索引并非越多越好 因为会产生额外的空间开销和时间开销(UPDATE 时需要维护) 建议使用在必需的情况下(数据量大且查询频繁的字段)
- MySQL 的大部分索引(主键、唯一、普通)都是 B+ 树索引 除此之外 空间索引使用 R 树 内存表支持哈希索引 而 InnoDB 的全文索引是基于倒排索引的
- 聚簇索引:索引的实际位置和数据的实际位置一样 在 InnoDB 中主键索引就是聚簇索引
- 不建议在 NOT NULL 字段上建立索引 因为会增加空间开销 如果需要置空 可以人为使用一个特殊值来代替
- Index Prefixes
- 对于特别长的数据字段 只取数据的前 N 个字符做索引 可以减少空间开销
- 复合索引
- MySQL 最多支持在 16 个字段上建立索引 查询时从左到右匹配索引
- 最左匹配原则:从左往右匹配 如果是等值查询可以继续 否则就停止
- 升序与降序
- 使用
ASC与DESC来指定索引的顺序 默认为升序 - 查询时如果使用了
ORDER BY语句 会根据其顺序来匹配索引 匹配到了则会提高查询效率
- 使用
Foreign Key
- 如果对于不同字段的查询频率不一样 可以使用外键进行垂直分表 比如 users 拆分为 user_auth 和 user_info
Database Structure
- 字段
- 使用数值类型来存储数值可以减少空间开销 甚至可以使用 MEDIUMINT 代替 INT 来节省空间
- 尽量使用 NOT NULL 一方面对索引有好处 另一方面可以减少额外一位 bit 的空间开销
- Row Formats
- DYNAMIC:默认的行格式 适合 TEXT 和 BLOB 类型的字段
- COMPACT:适合大部分的数据类型
- COMPRESSED:适合重复的文本或数字字段 会进行前缀压缩
- REDUNDANT:存在大量冗余 不建议使用
- Index
- 主键需要尽可能小 可以采用自增的方式 也可以采用 UUID
- 自增由于只能顺序写入 需要很大的开销保证唯一性
- UUID 则可以分布式生成 但是会增加空间开销
- 仅在多读少写、数据量大的表上建立索引
- 索引键需要尽可能小才能保证速度 所以对于长字符串的字段可以使用前缀索引
- 主键需要尽可能小 可以采用自增的方式 也可以采用 UUID
- Joins
- join 的两列尽量使用相同的数据类型和字段名 可以加速 join 的速度
- Normalization
- 适当的范式化可以减少冗余 但是会增加 join 的开销 需要根据实际情况作取舍
- Data Type
- 尽量使用数值类型来存储类似学号的字段
- 使用 binary collation order 来对文本进行排序(如果不需要区分大小写)这会使得文本全部以二进制形式比较 减少开销
- 比较不同的字段时 尽量使用相同的字符集与排序规则 使得避免转换的开销
- 小于 8KB 的数据可以使用 VARCHAR 大于 8KB 的数据应该使用 BLOB 因为如果数据太大会导致一次访问内存页面连一个数据都读不完
Many Tables
- table_open_cache:打开的表的数量 即存储的 fd 的数量 比如当前有 200 个连接 一个连接最多可以打开 64 个表 那么 table_open_cache 就应该设置为 200*64=12800
- max_connections:最大连接数
Limits on MySQL
- MySQL 对于数据库和表的数量没有限制 只限于操作系统的限制
- MySQL 一张表最多只有 4096 个列 然而 InnoDB 引擎的限制是 1017 个列
- 在声明 MySQL 中一张表的字段类型时 一行数据最多 65535 字节
- 注意 BLOB 和 TEXT 类型的数据不会占用声明的字节数 而是 9-12 个字节的指针开销
- VARCHAR 类型的数据还会有额外的开销存储元信息 通常是 2 字节
- NULL 数据需要额外的 1 位来存储
- 在 InnoDB 引擎的实际存储中 一行数据最多存储不超过 innodb_page_size 的一半(实际会略小于一半)
- 声明时 VARCHAR 类型的长度可以超过 innodb_page_size 的一半 因为不知道实际存储的数据大小 在实际存储时如果超过了一半则会报错???
- CHAR 类型由于是定长 声明多少就会占用多少空间 所以总共加起来不能超过 innodb_page_size 的一半
11.6
MySQL Optimization
InnoDB Tables
Storage Layout
- 一旦表的大小达到几百兆 可以使用 OPTIMIZE TABLE 指令来优化表 会把碎片整理到一起 并重建索引
- 一个长主键会浪费磁盘空间 因此建议创建一列自增列作为主键
- 尽量使用 VARCHAR 而不是 CHAR 因为前者可以压缩空间 除非确定这个字段的长度是固定的(比如学号)
- 对于具有很多重复文本或数字的字段 考虑使用 COMPRESSED 行格式(比如学号都具有相同的前缀)对于数值类型 会选定一个基准值 然后存储相对于基准值的差值
Transactions
- 默认情况下 每一条 MySQL 语句会在一个事务里执行 因此会在每一条语句后落盘 会造成很大的额外开销 可以通过
SET AUTOCOMMIT=0来关闭自动提交 然后使用 START TRANSACTION 和 COMMIT 指令来手动提交 - 如果打开 AUTOCOMMIT InnoDB 会识别出只包含一条 SELECT 语句的只读事务 并优化性能(如复用缓存)
- 尽量避免在 INSERT、UPDATE、DELETE 大量的数据后执行事务的回滚 因此少做大事务
- 增加 buffer pool 的大小可以使得数据进行缓存 减少磁盘的读写 注意多个实例共享一个 buffer pool
SET INNODB_CHANGE_BUFFERING=all可以设置 UPDATE 和 DELETE 操作会被缓存 而不是直接写入磁盘 否则只有 INSERT 会被缓存- 一条大数据量的语句会导致锁表 尽量不要在过程中执行 COMMIT
- 长时间的事务由于锁表还会导致 InnoDB 无法在其他事务中操作数据 除非降低隔离级别
- 使用
START TRANSACTION READ ONLY可以手动指定只读事务 会提高性能
Bulk Data
- 在一次性导入大量数据时 可以暂时关闭自动提交 手动建立一次事务来导入数据 避免每一次 INSERT 都造成日志的写入
- 同理也可以通过 SET UNIQUE_CHECKS=0 和 SET FOREIGN_KEY_CHECKS=0 来暂时关闭唯一性检查和外键检查 提高性能
- 使用多行 INSERT 语句可以减少客户端和服务器之间的通信次数
- 对于自增字段进行大量 INSERT 时
SET INNODB_AUTOINC_LOCK_MODE=2而不是 1 此时会给每个线程分配一个自增值范围 而不是一个值 字段可能不会严格递增
Queries
- 因为主键会自动创建聚簇索引 所以尽量选择经常进行范围查询的字段作为主键
- 主键不要设为复合或者长字段 因为主键的值会被存储在每一个二级索引中
- 对于二级索引 尽量使用小复合索引而不是独立的单个索引 这样可以为多种查询提供优化
- 索引字段不要设置为 NULL
Disk I/O
- 提高 innodb_buffer_pool_size 的大小可以减少磁盘的读写次数
- 调整 INNODB_FLUSH_METHOD 参数为 O_DSYNC 会使得文件和文件元数据异步写入磁盘
- 调整 INNODB_FSYNC_THRESHOLD 参数 可以减少磁盘的写入次数
- 使用非旋转介质的磁盘可以提高随机访问性能 可以把数据文件放到 SSD 上 把日志文件放到 HDD 上
- 提高 innodb_io_capacity 参数的值可以提高磁盘的读写性能 从而避免 backlogs(checkpoints 和 log writes)
- 使用 TRUNCATE TABLE 而不是 DELETE FROM TABLE 因为后者还是会遍历每一行数据 前者则是直接删除指针 如果有外键 需要注意顺序
- 主键尽量避免修改 并且在创建表时就确定好
MEMORY Tables
- 内存表通常是用于临时存储数据的 非关键且只读少写的数据可以存在内存表里
- 内存表可以使用 HASH 或者 BTREE 两种索引 针对不同场景建立不同的索引
Caching
innodb_buffer_pool_chunk_size:缓存池的块大小 默认是 128MB--innodb_buffer_pool_instances:缓存池的实例数 默认是 1 最多是 64--innodb_buffer_pool_size:缓存池的大小 必须是实例数 * 块大小的整数倍 比如 16 个实例 128MB 的块大小 那么缓存池的大小就是 2GB 的整数倍 这是为了可以把缓存池均匀分配到不同的实例上- 建立多实例缓存池后 同一张表就可以在多个缓存池里缓存
- 缓存池的替换策略不是单纯的 LRU 而是根据数据的热度来替换 会把新数据放到 3/8 的队列位置 队里的数据被访问时则会被放到队尾 如果是冷数据则会迅速的被挤到队头移出 还会做一定的数据迁移 把热数据放到其他地方
- 预读取会把其他数据读取到缓存里 可以顺序预读取 也可以随机预读取
innodb_page_cleaners:将脏页落盘的清理线程数量 默认是 4 不会超过缓存池的实例数innodb_max_dirty_pages_pct_lwm:脏页的最大比例 默认是 10% 会触发脏页的清理 0 表示不会触发- 为了减少 warm-up 的时间 InnoDB 会把缓存池中最常用的页存到磁盘上 并在重启时直接 restore 到缓存池里 持久化的比例由
innodb_buffer_pool_dump_pct决定 默认是 25% - MySQL 还会缓存语句的处理结果
11.11
MySQL Backup and Recovery
Backup and Recovery Types
- Physical Backup:备份整个数据库的文件(.MYD、.MYI) 适合大型数据库 恢复速度快
- Logical Backup:备份数据库的逻辑结构 适合小型数据库 可以导入到其他 SQL 数据库中
- Online Backup:备份时数据库仍然在运行 会出现备份同时写入的问题 需要锁来保证一致性
- Offline Backup:备份时数据库停止运行 影响用户体验 一般数据量小
- Warm Backup:备份时数据库仍然在运行 但是禁止写入
- Local Backup:本地备份
- Remote Backup:远程控制机器进行备份
- Snapshot Backup:快照备份 增量备份的一种 在给定时间点提供整个数据库的逻辑备份 而不是整个数据库的物理拷贝 通过 COW 来记录每一次修改 当改变达到阈值后进行一次全量备份 MySQL 本身不支持 必须使用 LVM 或者 ZFS 等文件系统
- Full/Increment Backup:启动 MySQL 的 binlog 功能 可以记录每一次修改的日志 通过备份时的 binlog 来进行增量备份
- Backup 还可以做 schedule(定时备份)、compression(压缩备份)、encryption(加密备份) 不过 MySQL 本身不支持这些功能 需要使用其他工具
Database Backup Methods
- 建议选择企业版的 MySQL 默认是物理备份和热备份
- 如果使用社区版:
- 逻辑备份可以用 mysqldump 来实现 使用
--single-transaction参数可以在备份时不锁表 可读不可写 - 物理备份时需要保证内存落盘 使用
FLUSH TABLES tbl list WITH READ LOCK来落盘 同时上锁 可读不可写 - 使用
SELECT * INTO OUTFILE 'file_name' FROM tbl_name可以导出定界文本文件 只保存数据不保存结构 另外使用 mysqldump 加上--tab参数也可以导出定界文本文件 想要重新导入只需要使用LOAD DATA与 mysqlimport 即可 - MySQL 支持使用 binary log 来进行增量备份 当进行全量备份时 使用
FLUSH LOGS来切换日志文件 - 使用主从复制 老生常谈了 不赘述 只需要在崩溃时把从库提升为主库即可 备份恢复则是在从库上进行
- 如果使用 MyISAM 可以使用
REPAIR TABLE来修复表
- 逻辑备份可以用 mysqldump 来实现 使用
An Example
- 遇到断电或操作系统宕机时 我们可以认为磁盘数据是安全的 此时 InnoDB 会自动对 log 进行恢复
- 文件系统崩溃或其他硬件问题 导致磁盘数据损坏 需要格式化磁盘 并且需要从备份中恢复
- 假如每周日的 1 点进行一次全量备份 使用
mysqldump --all-databases --master-data --single-transaction > backup_{date}.sql指令 产生的文件就可以用于恢复 这个备份操作需要一个所有表上的全局读锁 - 使用
--log-bin启用 binlog 功能 binlog 会定期截断--delete-master-logs可以在全量备份时删除旧的 binlog - 假如周三的 8 点遇到了灾难 先恢复到周日 1 点的状态 然后使用
mysqlbinlog gbichot2-bin.000001 gbichot2-bin.000002 | mysql来恢复 假如一个 binlog 是一天 现在恢复到了周二 1 点的状态 - 最后使用
mysqlbinlog gbichot2-bin.000003 ... | mysql来恢复到周三 8 点的状态...表示周二 1 点到周三 8 点的所有 binlog 文件 - 日志和备份应该存储在和数据库不同的地方 保证安全
- 总结:
- 若数据库未损坏 InnoDB 会自动使用 log 进行恢复
- 若数据库损坏 使用以下策略防止数据丢失
- 启用 binlog 来进行增量备份
- 使用 mysqldump 来进行定期的全量备份
- 使用
FLUSH LOGS来定期切换新的日志文件
Using mysqldump
- mysqldump 是一个备份工具 可以备份数据库或者表 使用 mysqlimport 可以导入这些备份文件
- dump 文件可以用于恢复数据库 也可以用于主从复制 也可以用于实验
--tab会多生成一个 tab-delimited 文件 否则只生成一个 sql 文件--database相当于在文件中加上USE database语句 因此如果想要导入为其他名称的数据库 不要使用这个参数- 各种指令用法详见 ppt
Point-in-Time Recovery
- PITR 是一种增量备份 即将数据恢复到某个时间点的状态 在 MySQL 中可以使用 binlog 来实现
- 注意 mysqlbinlog 不应该起多个线程并行执行多个 binlog 内的语句之间可能会有依赖关系 正确做法是在一条指令内执行多个 binlog
- 使用
--start-datetime和--stop-datetime来查看小时间段内的 binlog 找到需要的 position - 使用
--start-position和--stop-position来指定恢复的范围 可以跳过一部分 binlog 这样就可以跳过某些失误的操作
11.13
MySQL partitioning
Partitioning Types
Range Partitioning:根据某个字段的范围来分区 即连续值
- RANGE 分区示例如下 创建了一个根据 joined 字段的 YEAR 来分区的表 范围规定必须为是单边开区间 方便后续添加新的分区和删除旧的分区进行合并 并且范围是连续升序的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (YEAR(joined)) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);- RANGE 也可以在多列上进行分区 比如
PARTITION BY RANGE COLUMNS (a, b, c)先比较 a 如果相等再比较 b 如果相等再比较 c - NULL 值会被放到最小的分区中
List Partitioning:根据某个字段的值来分区 即离散值
- LIST 分区示例如下 创建了一个根据 region 字段的值来分区的表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL,
region VARCHAR(10)
)
PARTITION BY LIST (region) (
PARTITION pNorth VALUES IN ('NORTH'),
PARTITION pSouth VALUES IN ('SOUTH'),
PARTITION pEast VALUES IN ('EAST'),
PARTITION pWest VALUES IN ('WEST')
);INSERT IGNORE INTO employees VALUES会忽略因为分区不匹配而插入失败的数据 比如上面的表中插入了一个 region 为 ‘OTHER’ 的数据会被忽略- 想要插入不属于任何分区的数据 可以使用
PARTITION pOther VALUES IN (DEFAULT)来插入 - NULL 会被当做某一个离散值来处理 如果没有对应的分区则会插入失败
- RANGE 和 LIST 的多列分区有如下限制
- 支持整数类型 包括 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT 不支持 FLOAT 和 DECIMAL 类型
- 支持日期和时间类型中的 DATA、DATETIME 其他的不支持
- 支持字符串类型 包括 CHAR、VARCHAR、BINARY、VARBINARY 不支持 TEXT 和 BLOB 类型 因为是指针
Hash Partitioning:根据某个字段的哈希值来分区 由用户定义
- HASH 分区示例如下 创建了一个根据 id 字段的哈希值来分区的表 哈希函数是对于分区数取模
1
2
3
4
5
6
7
8
9
10
11CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY HASH (id)
PARTITIONS 4;- 哈希函数也可以使用线性哈希函数 其扩展分区时需要迁移的数据较少 使用
LINEAR HASH来指定 - NULL 会被当做 0 来处理
Key Partitioning:根据某个字段的哈希值来分区 由 mysql 定义
- KEY 分区示例如下 创建了一个根据 id 字段的哈希值来分区的表 不指定列则会取主键
1
2
3
4
5
6
7
8
9
10
11CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY KEY (id)
PARTITIONS 4;- 也可以使用
LINEAR KEY来指定线性哈希函数 - NULL 会被当做 0 来处理
Subpartitioning:在分区内再根据某个字段进行分区 示例如下 先按照年份分区 每个年分区里按照天数继续分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (YEAR(joined))
SUBPARTITION BY HASH (TO_DAYS(joined))
SUBPARTITIONS 4 (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);- 也可以直接声明子分区数量和名称 形如
1
2
3
4
5
6
7
8
9
10PARTITION BY RANGE (YEAR(joined))
SUBPARTITION BY HASH (TO_DAYS(joined))(
PARTITION p0 VALUES LESS THAN (1991)(
SUBPARTITION s0,
SUBPARTITION s1,
SUBPARTITION s2,
SUBPARTITION s3
),
......
);
Partitioning Management
- RANGE 分区的范围应该尽量和未来的查询范围相匹配 使得查询可以在一个分区内完成
ALTER TABLE employees PARTITION BY RANGE (YEAR(joined)) PARTITIONS 4;会重新分区 但是会把数据全部拷贝一遍ALTER TABLE employees DROP PARTITION p0;会删除分区以及其数据 分区的范围仍然会保留连续性 也就是说其会合并到右边的分区ALTER TABLE employees ADD PARTITION (PARTITION p0 VALUES LESS THAN (1991));会添加一个新的分区 范围必须大于已有的分区 对于 LIST 则不能重复ALTER TABLE employees REORGANIZE PARTITION p0 INTO (PARTITION p0 VALUES LESS THAN (1991), PARTITION p1 VALUES LESS THAN (1996));会重新组织分区 可以分裂分区 也可以合并分区- HASH 和 KEY 不允许删除分区 因为数据会被重新分布 但是可以合并分区 使用
ALTER TABLE employees COALESCE PARTITION 4;来合并分区 ALTER TABLE employees EXCHANGE PARTITION p0 WITH TABLE employees_archive;会用分区交换表 但是表的结构必须和分区的结构一样 也不能有外键约束 不能有分区 表内不能有分区外的数据 加上WITHOUT VALIDATION可以跳过分区范围的检查 但是会真的插入不合法的数据 需要后续手动检查 这条指令可以用于归档数据、数据迁移等- 还有很多指令可以维护分区表
- REBUILD PARTITION
- OPTIMIZE PARTITION
- ANALYZE PARTITION
- REPAIR PARTITION
- CHECK PARTITION
Partitioning Pruning
- MySQL 中的 query plan 会自动根据分区的范围来进行分区裁剪 从而减少查询的开销
- 不只 SELECT 语句 也包括 UPDATE 和 DELETE 等语句
- 因此分区逻辑应该尽量和查询逻辑相匹配 使得查询可以在一个分区内完成
11.18
MongoDB & NoSQL
- 为什么需要 NoSQL
- 数据量超过 10M 后 RDBMS 的性能会急剧下降 因为 B+树的深度会增加
- RDBMS 无法处理非结构化数据 比如一篇文章的内容
- Big Data
- 结构化数据 尤其是轻量级的数据 非常适合使用 RDBMS
- 半结构化数据 比如 JSON XML 等
- 非结构化数据 比如图片、视频、音频、文本等
- RDBMS
- 数据量:在 GB 级别
- 访问方式:交互式 批处理比较难
- 结构:固定的 schema
- 约束:强约束
- 扩展:非线性的扩展性能
MongoDB
Basic Concepts
- Document:类似于 JSON 的数据结构 由键值对组成
- 每一个文档都有一个唯一的
_id字段+ - 键的顺序会区分不同的文档
- 键不能包含
.$null且不能是空字符串 且不能是_开头的保留字 - 键值是类型敏感和大小写敏感的
- 允许重复的键
- 每一个文档都有一个唯一的
- Collection:类似于表 由多个 Document 组成
- 不能以””命名 不能以
system.开头 - schema-free:不对文档的结构做任何限制
- 文档的分表需要遵循 data-locality 原则,即相关的文档应该存储在一起
- Subcollection:类似于垂直分表 但是表之间不会有任何关联 比如
blog.posts和blog.comments但是它们与blog之间没有关联 可以看做是 namespace
- 不能以””命名 不能以
- Database:类似于数据库 由多个 Collection 组成
- 不同的数据库会被存储到不同文件 也拥有不同的权限 最好的做法是一个数据库只存储一个应用的数据
- 保留数据库
- admin:存储用户信息
- local:存储本地数据 不会被复制
- config:存储分片信息 用于剪枝 因为 sharding 是按
_id来分片的
- 基本命令
show dbs:显示所有数据库use db_name:切换数据库show collections:显示所有集合db.collection_name.find():显示所有文档db.collection_name.find({key: value}):显示符合条件的文档db.collection_name.insertOne({key: value}):插入一个文档db.collection_name.insertMany([{key: value}, {key: value}]):插入多个文档db.collection_name.updateOne({key: value}, {$set: {key: value}}):更新一个文档db.collection_name.updateMany({key: value}, {$set: {key: value}}):更新多个文档db.collection_name.replaceOne({key: value}, {key: value}):替换一个文档db.collection_name.deleteOne({key: value}):删除一个文档db.collection_name.deleteMany({key: value}):删除多个文档db.collection_name.aggregate([stage1, stage2, ...]):聚合查询 可以进行统计、分组、排序等操作db.collection_name.drop():删除一个集合db.dropDatabase():删除一个数据库
Spring with MongoDB
- 需要导入 spring-boot-starter-data-mongodb 依赖
- 需要在配置文件中配置 MongoDB 的连接信息:
spring.data.mongodb.uri=mongodb://localhost:27017/test - 需要在实体类上加上
@Document注解 - 需要在 DAO 层继承 MongoRepository 接口
- 结合 JPA 时 将不需要 JPA 维护的字段加上
@Transient注解
Indexing
- Normal Index:
db.collection_name.createIndex({key: 1}):升序索引db.collection_name.createIndex({key: -1}):降序索引 - Geospatial Index:
db.collection_name.createIndex({key: "2dsphere"}):地理位置索引 值需要是含两个数值的数组 - 上述索引都可以在 Mongo Compass 中进行可视化创建
11.20
MongoDB
AUTO Sharding
- MongoDB 将 collection 分为小的 chunks 称为 shards
- 由于 MongoDB 的分片是自动的 用户无需关心数据的分布 数据库会为每个分片的 collection 创建一个 router 存储分片的元数据
- 当添加或减少 shard 时 MongoDB 会自动迁移数据 使得数据均匀分布
- shard 是一个服务器节点上的分片 一个 shard 包含多个 chunk MongoDB 会限制每个 shard 之间的 chunk 数量不能超过一定的阈值
- 用户选择用来分片的字段称为 shard key 按照 shard key 的值范围 数据会分为不同 chunk 当一个 chunk 的数据量超过阈值时 MongoDB 会自动分裂这个 chunk 并且把新的 chunk 迁移到其他 shard 上
- 新添加一个 shard 时 MongoDB 会把一部分 chunk 迁移到新的 shard 上 删除同理
- 有时不希望数据均匀存储 可以关闭 chunk 数量的限制 改用自己写的 balancer 保证数据访问的均衡
Neo4j & Graph Computing
- 一个异构图中的节点和边可以有不同的属性 在 ORM 中节点就是实体 边就是关系
- 关系型数据库的 join 操作是 O(n^2) 的 复杂度太高 导致某些关系复杂的查询涉及到大量的表连接 非常耗时
- 非关系型数据库虽然可以通过嵌套或引用来解决正向的 join 但是没办法进行反向映射
- 在图数据库里 这样的关系查询都可以转换为图的遍历操作 从而大大降低复杂度
Neo4j
Cypher:Neo4j 的查询语言
- Neo4j 中使用 ascii 码描述图的结构 比如
(John:Person {name: "John"})-[KNOWS]->(Mary:Person {name: "Mary"})-[:KNOWS]->(John)表示 John 和 Mary 之间互相认识 其中Person是节点的标签KNOWS是边的标签John是节点的引用 MATCH (n:Person)-[:KNOWS]->(m:Person) RETURN n, m表示查询所有认识的人
- Neo4j 中使用 ascii 码描述图的结构 比如
Neo4j 的数据模型
- 节点对应于实体 边对应于关系
- 有时复合关系可以用一个节点来表示 一个点赞关系可以用一个点赞节点来表示
Neo4j 的使用
- 可以单机部署 也可以集群部署 也可以嵌入到 Spring Boot 中
- 需要导入 spring-boot-starter-data-neo4j 依赖
- 需要在配置文件中配置 Neo4j 的连接信息:
spring.data.neo4j.uri=bolt://localhost:7687 - 需要在实体类上加上
@NodeEntity注解 - 使用
@Relationship注解来表示关系
Internals
- Neo4j 中 节点和边分开存储
- 节点占 15 Bytes
- inUse:是否被使用 (1 Byte)
- nextRelId:第一条边的 ID (4 Bytes)
- nextPropId:第一个属性的 ID (4 Bytes)
- labels:节点的标签的 ID (5 Bytes)
- extra:备用位 (1 Byte)
- 边占 34 Bytes
- inUse:是否被使用 (1 Byte)
- firstNode:起始节点的 ID (4 Bytes)
- secondNode:终止节点的 ID (4 Bytes)
- relationshipType:关系的类型 (4 Bytes)
- firstPrevRelId:起始节点的前一条边的 ID (4 Bytes)
- firstNextRelId:起始节点的后一条边的 ID (4 Bytes)
- secondPrevRelId:终止节点的前一条边的 ID (4 Bytes)
- secondNextRelId:终止节点的后一条边的 ID (4 Bytes)
- nextPropId:下一个属性的 ID (4 Bytes)
- firstInChainMarker:是否是链的第一条边 (1 Byte)
Neo4j 嵌入到 Spring Boot 中
- 在一些图计算中会用到 比如识别银行转账的洗钱行为 需要图神经网络来识别
Summary
- Neo4j 是一个图数据库
- 提供不同语言的 Driver
- 提供 Neo4j Browser 可视化工具
11.25
Log-Structured DB & Vector DB
- 不同的数据特性和访问模式需要不同的数据库 比如热点数据和 AI 模型
Log-Structured DB
LSM-Tree:Log-Structured Merge-Tree
- Basics
- 一种分层、有序、面向磁盘的数据结构 以 Append-Only 的方式写入数据
- 核心思想是利用磁盘的顺序写性能 但是牺牲了部分读取性能 适合写多读少的场景
- 分层为内存层和磁盘层 memtable 写满后会和 immutable
memtable 互换
- Pros & Cons
- 优点
- 插入性能高
- 空间放大率低
- 访问新数据快 适合实时数据
- 数据热度和 level 有关
- 缺点
- 牺牲了读性能(一次可能访问多个层)
- 读、写放大率高(读放大是因为查找旧数据时需要遍历很多 sstable;写放大是因为触发多次 compaction)
- 优点
RocksDB
由 Facebook 开发的 LSM-Tree 键值数据库 支持嵌入式存储
RocksDB 适于存储热点数据 当超过限制层数时 可以考虑迁移到其他数据库
Hybrid Transactional/Analytical Processing:混合事务/分析处理
- OLTP:Online Transaction Processing 在线事务处理
- 低延迟 高并发 数据量小 比如下订单
- 数据存储应该是行存储 保证一个记录的数据是连续的 避免随机访问
- OLAP:Online Analytical Processing 在线分析处理
- 高延迟 低并发 数据量大 比如后台统计数据
- 数据存储应该是列存储 保证一个字段的数据是连续的 避免随机访问
- OLTP:Online Transaction Processing 在线事务处理
RocksDB 为了支持 HTAP 将数据按照字段进行了拆分存储(也就是垂直分表)
- 不同字段的数据存储在不同的 Column Family 里
- 不同的 Column Family 共享 WAL 但是可以有不同的存储形式
- 需要进行 OLAP 的字段可以按列存储 需要进行 OLTP 的字段可以按行存储
写阻塞问题
- RocksDB 将数据写入内存后立马返回 后台会异步的将数据写入磁盘
- 显然 L0 层满时会阻塞内存落盘的过程 此时会导致写阻塞
- L0 往下的 Compaction 过程无法多任务执行
- Compaction 写放大严重 会导致磁盘性能成为瓶颈
- Solution
- 在 RocksDB 和数据源之间加一个收集分发层(比如 flink) 有许多 collector 负责缓存数据
- master 负责监控 collector 的状态 根据剩余内存大小进行负载均衡
读放大问题
- 需要访问所有可能的 sstable 才能找到数据
- Solution
- 通过 Bloom Filter 来过滤不可能存在的数据
- 在 RocksDB 中增加列式存储 适合 AP 处理
Vector DB
- 人工智能中往往会产生大量的向量数据用于表示特征等 传统的数据库无法很好的支持向量数据的存储和查询 因此需要专门的数据库来支持向量数据的存储和查询 其中查询大部分是相似度查询 即 ANN(Approximate Nearest Neighbor)查询
Index Algorithms
Random Projection:随机投影(加快 ANN 查询)
- 对于 m 维的向量 通过随机生成一个 m * n 的矩阵 将向量投影到 n 维空间中
- 可以用于降维 也可以用于升维 降维后可以方便做索引
Product Quantization:乘积量化
- 对于 m 维的向量 将其分为 k 个子向量 对这 k 个子向量做聚类 产生 k 个 codebook
- 当有对同样 m 维向量进行查询时 将其分为 k 个子向量 也进行聚类 得到 k 个 codebook 依据这些 codebook 找到比较相似的向量(比如两个向量的 codebook 都一样)来进行相似度查询
Locality-sensitive Hashing:局部敏感哈希
- 对于 m 维的向量 通过哈希函数将其映射到几个个含有多个位置的 bucket 中
- 进行查询时 同样将查询向量映射到 bucket 中 根据 bucket 中的位置来找到相似的向量
Hierarchical Navigable Small World :层次导航小世界
- 节点代表一组向量 边代表相似度
- 节点会与最相似的节点相连
- 通过一直向距离更近的节点导航来找到相似的向量(不一定是最相似的)
Similarity Measures
- Cosine Similarity:余弦相似度 即两个向量的夹角的余弦值
- Euclidean Distance:欧几里得距离
- Manhattan Distance:曼哈顿距离
- Dot Product:点积
Filtering
- 向量会带有元数据(比如图片、音频等) 这些元数据可以用于过滤 且也有索引
- 可以先查询出 top-k 的向量 再用元数据进行过滤 也可以先用元数据进行过滤再查询出剩余向量中的 top-k
Pinecone
- 只允许在本地运行客户端 通过 API 连接到云端的数据库
- 支持主从复制
11.27
Time Series DB & InfluxDB
- 时序数据具有以下特性
- 有时效性
- 格式简单
- 可以存差值
- 数据有时间戳
- 一般是监测、采样数据
InfluxDB
- Telegraf:InfluxDB 的数据采集工具 可以监控系统的各种状态 配合 InfluxDB 使用
- Key Concepts
- Flux:InfluxDB 的查询语言
- Timestamp:时间戳 存储在
_time列 以纳秒为单位 - Measurement:相当于表名 存储在
_measurement列 - Fields:字段 不参与索引 包含键与值 一旦查询就是全表扫描
- Field Key:字段名 存储在
_field列 - Field Value:字段值 存储在
_value列
- Field Key:字段名 存储在
- Tags:记录的标签 参与索引 相当于其他数据库的字段
- Series:一组相同 measurement、tag set 和 field key 的数据
- Point:一条记录 包含 measurement、tag set、field key、field value、timestamp
- Bucket:InfluxDB 的存储单元 类似于数据库 可以设置数据的保留策略
- Organization:组织 组织内的用户在一个工作空间中共享数据
- Design principle
- 按照时间升序存储 以提高性能
- 数据只追加 不修改不删除
- 高并发时 只保证查询到旧数据 不保证查询到最新数据 这是为了尽快返回结果
- 没有 ID 因为不需要查询单个数据
- 不会记录重复数据 只有数据变化时才会记录新数据 为了节省空间
- Storage engine
- Components
- TSM:Time Structured Merge Tree
- TSI:Time Series Index
- WAL:Write Ahead Log
- Cache
- InfluxDB 使用 line protocol 相当于发送 POST 请求来写入数据
- 一批数据发送到 InfluxDB 后会先压缩 然后写入 WAL 并且立马写入 Cache 后台定期将 cache 中的数据写入 TSM 注意 Cache 里的数据是热数据 所以不压缩
- TSM 树类似于 LSM 树 其 SST 中的数据按照 series key 排序 并且实际存储是列存储(适合时序数据分析) 存储差值以节省空间
- Components
- File Structure
- Engine path:存储引擎的路径
- data:存储 TSM 文件
- wal:存储 WAL 文件
- Bolt path:存储 BoltDB 文件 包含非时序数据 比如用户、控制面板等
- Configs path:存储 CLI 的配置文件
- Engine path:存储引擎的路径
- Shards
- Shard 内的数据会被编码并压缩存储 即冷数据
- Shard Group:包含一段时间范围内的数据 普通版一个 group 只有一个 shard 企业版可以有多个 shard
- 需要指定两个参数来创建 shard group
- retention period:数据保留时间 超过这个时间的数据会被删除 可以设为永久
- shard group duration:shard group 的时间范围 即多少时间划分一个 shard group
12.2
GaussDB
- 由华为开发的云原生数据库 基于 PostgreSQL
- 支持分布式事务、分布式语句优化、分布式存储、分布式计算
总体架构
- 分布式优化、执行与事务处理
- 分布式近数据计算:即尽量把计算下推到数据所在的节点
- 全链路并行编译执行:将语句预先编译好 后续填入参数即可 与解释执行相比性能更高
- 大规模并发事务处理
- SQL 解析优化器:包括 ROB、COB
- 多层级高可用容灾
- 故障自感知
- 多地多活容灾
- 云原生弹性伸缩架构
- 在线弹性伸缩:纵向扩展和横向扩展 前者是增加一个节点内的资源 后者是增加节点形成更大的集群
- 云原生分布式计算存储分离:内存与磁盘分离使用
- 负载均衡
- 多租户
- 智能优化
- ABO 优化器:基于 AI 的优化器
- 内置 AI 引擎:支持机器学习和深度学习
- 安全隐私
- 防篡改:区块链技术
GaussDB 分布式
- 分布式架构
- Coordinator Node:协调节点
- Data Node:存储数据
- GTM:分布式事务管理 使用 2PC 与 CSN(Commit Sequence Number)来保证事务的一致性
- 分布式优化器
- 根据语句生成查询计划
- 根据查询计划树进行重写 生成优化后的执行计划
- 分布式并行执行
- 多机多线程并行执行:节点内部可以多线程并发执行
- 向量执行:读取列存数据 利用 CPU 的多核提高速度
- 编译执行:大幅降低执行算子指令数量 提高执行效率
- 分布式事务
- 使用 CSN 管理全局事务号
- 采用 2PC 协议 第二阶段事务提交为异步 即所有节点准备好即可提交
- 分布式高精度时钟
- 使用北斗卫星来同步时钟
- 分布式查询优化
- 将计算下推到节点 减少数据传输
GaussDB 高可用
- 两地三中心容灾
- 两地:异地容灾 二一分布
- 三中心:A B C 三个数据中心 A B 为生产集群 位于同一地区 C 为容灾集群 位于另一地区
- 同城双集群 RPO=0:即零数据丢失
- 采用热备份 即请求同时发送到两个集群 切换时间几乎为零
- 而暖备份是指请求处理的结果同步给备份集群 如果主集群挂了 用户需要重发请求
- 冷备份是指周期性进行数据同步 如果主集群挂了 会丢失上次同步后的数据
GaussDB 云原生
- 分布式计算存储分离:计算存储解耦 独立扩展伸缩 允许远程 DMA(Direct Memory Access)访问
- 存储节点日志按需回放:方便节点崩溃后新节点的数据恢复
- 数据预分片:数据还未存在时就预先分片 缩短扩容时间 实现平滑扩容
- 哈希桶聚簇存储:采用一致性哈希 只需迁移少量数据即可实现扩容
- 映射表并行迁移:只需要迁移少量元数据映射表 无需迁移用户数据
- 多租户:一个数据库实例支持多个独立隔离的租户
- 数据库进行资源、数据的隔离以及弹性伸缩
- 租户进行资源弹性调度与资源管控
- 四种方案
- 分开部署在两个实例 维护一致性很差
- 部署在一个数据库的两张表
- 存在一张表 用一个字段记录租户的权限 不同的字段分到另外表 用外键关联
- 同 3 用行存不同字段 可能会很长
GaussDB 查询处理
- 查询处理
- ROB:基于规则的优化器
- 根据预定义的启发式规则来优化查询
- COB:基于成本的优化器
- 利用统计信息 通过代价估算来选择最优的执行计划
- 代价=IO+CPU+通信
- AOB:基于 AI 的优化器
- 借助强化学习等估计基数和代价
- ROB:基于规则的优化器
- 查询重写
- 谓词下推:在子表上执行谓词 然后 join
- 谓词上移:先 join 子表 再执行谓词
GaussDB 存储
- 存储概览
- 追加更新行存
- 原位更新行存
- 列存
- 内存
- 支持智能化互转
- 页面结构
- 行存储以页面为单位 页头存放元数据 页头后防止指向元组的行指针 而元组则反向从页尾向页头增长
- 追加更新
- 采用 MVCC 多版本机制 采用全局递增的事务号作为版本号 一个元组会记录 xmin 和 xmax 即何时插入与删除 用于判断可见性
- 将原记录的 xmax 改为当前事务号 使得原有行失效
- 将 id 改为新行的 id 指向新行 其 xmax 为 0
- 保留原有行的数据 用于回滚
- 数据位于不同位置 可以并发读写
- 原位更新
- 追加更新将老数据与新数据都存在数据空间 回滚需要扫描所有数据
- 原位更新使用单独的页面存储老版本数据
- 最新版本存在数据段原地 通过指针指向老版本数据
- 空闲空间管理
- 使用三层大根堆维护每个页面的空闲空间 快速找到最适配 size 的页面并更新空闲空间大小
- 缓冲区
- 使用环形缓冲区存放事务的读写请求
- 列存
- 基本单位是压缩单元(CU)
- 压缩方式包括差分编码、字典编码等 自适应选择
- 每个 CU 可以记录元数据 包括时间戳、最大值、最小值等 方便对于 CU 建立索引
- 内存
- 低延迟高吞吐 并行化
- 采用外部数据封装器 FDW 将外部的内存存储转换为内部的存储 比如 Redis
- HTAP
- 支持行列混合存储 自由切换
GaussDB 安全
- 安全全景
- 攻不破:AI 防 SQL 注入
- 进不来:防强制攻破(比如暴力破解)
- 拿不走:行级权限控制
- 看不懂:数据脱敏加密
- 改不了:区块链防篡改 可看不可改
- 赖不掉:审计 一旦有修改会记录操作者
- 信得过:通过第三方评测认证
12.4
Data Lake
- Data Lake 是一个存储池 以 raw format 存储各种文件和大对象数据 包含数据的 metadata
- 和 Data Warehouse 不同 数据湖写入数据时不作处理 等待后续需要时再作分析处理 因为并不确定数据的用途
- Data Lake vs Data Warehouse
- 数据格式:前者以 raw format 存储 后者以 processed format 存储
- 数据目的:前者未定 后者一定会用到
- 用户:前者是数据科学家 后者是商业用户
- 可访问性:前者可以快速读写 后者需要更多开销来处理数据
演化历程
- HDFS 为底层存储系统 MapReduce 为基本计算模型 Zookeeper 为协调服务
- HDFS 的批处理无法满足实时性高的场景(比如流处理场景)因此产生了 lambda 的”流批一体化”架构 数据既可以进行批处理也可以进行流处理
- 加大流计算的并发性与“时间窗口”概念 流批统一 即后面会提到的 将一段时间内的所有数据作为一个 batch 进行处理 从而流批处理可以统一
- Lakehouse:即湖仓一体化 在数据湖内嵌 ETL 功能 需要进行处理的结构化数据可以直接存储在数据湖中 其他数据也可以直接不做处理取出用于其他用途 数据湖上层是元数据层 根据元数据选择更上层的数据查询方式(SQL API、DataFrames API)
Delta Lake
- Delta Lake 是一个开源的数据湖解决方案
- 可以接受任何格式和来源的数据 并以高保真的方式存储
- 支持实时或批处理数据
- 可以使用包括 SQL、Python、R 在内的多种语言进行数据分析(这是因为其可以将数据转换为统一的格式 如 Parquet)
- Architecture
- 数据可以以 batch 或 stream 的方式写入 Delta Lake
- 输入的数据先以原始格式存储在 Ingestion Table 中
- 底层存储可以是 HDFS、S3、ADLS 等
- 数据进一步进行处理(比如去重、清洗)后存储在 Refined Table 中
- 进一步进行 Feature、Aggregation 等操作后 数据最终可以直接用于数据分析或机器学习
Apache Hudi
- Architecture
- 底层存储支持 HDFS、S3、ADLS 等
- 输入数据支持 MySQL、Cassandra、PostgreSQL 等
- 通过 Flink 接受数据到 Raw Table 中
- 进一步进行增量 ETL 后存储在 Derived Table 中
- 通过 Spark、Hive 等进行数据查询
- 支持使用 Spark、Hive、Flink 进行流水线处理
云边融合数据存储
- 哈哈 这不就是我正在做的灯塔项目吗
- 利用边缘计算资源来减轻云端的压力 减少带宽消耗
12.9
Clustering
- 集群的目的可以被概括为 RAS
- Reliability:消除了单点故障
- Availability:可用性提升为 1-(1-p)^n
- Serviceability:可以进行热维护与热更新
- Scalability:期望以线性提升性能
- 集群是一组服务器提供联合服务 在客户端的视角 集群就是单个服务器
- 负载均衡
- 集群的负载均衡就是反向代理 即将请求分发到集群中的某个节点
- 策略有轮询、最少操作数、IP 哈希(可以解决 session 粘滞问题)等
- failover 后的 session 保持有两种方式
- 要么 session 共享或广播 但是会浪费资源
- 要么集中在一个机器做 session 处理鉴权 但是会造成单点故障与性能瓶颈
- 请求 fail 的处理关键点在于幂等性
Nginx
Nginx 是一个高性能的 HTTP 和反向代理服务器
配置文件的写法可以见
从零开始部署自己的服务器与WEB技术栈两篇文章 我在这里只做一些简单的补充负载均衡策略有以下几种
- 轮询(默认)
- 最少连接数(least_conn)
- IP 哈希(ip_hash)
- 加权轮询(weight)
MySQL Cluster
- 使用 MySQL Shell 可以建立主从复制的 MySQL 集群 至少需要 1 个主节点和 2 个从节点
- 切换为 mysql-js 模式以输入 JavaScript 语句
- 使用
dba.checkInstanceConfiguration()来检查配置是否正确 - 如果配置不对 使用
dba.configureInstance()来检查哪些配置不对 可以输入y来一键配置 配置完需要重启 - 使用
dba.createCluster()来创建集群 - 使用
cluster.addInstance()来添加从节点 注意从节点也需要进行dba.checkInstanceConfiguration()检查 - 添加从节点时可以选择是复制还是增量备份
- 使用
cluster.status()来查看集群状态 - 使用
cluster.removeInstance()来移除节点 - 使用
cluster.dissolve()来解散集群
AI-1:全连接神经网络 & Keras
神经网络
- 基本原理
- 一个神经元的输入是一组向量的线性组合加上一个偏置量 神经元会把这个输入通过一个激活函数输出 作为下一层神经元的输入 激活函数可以是 sigmoid、tanh、ReLU 等
- 多个神经元组成一个层 多个层组成一个网络 一个神经网络可以看做是一个黑箱 我们的目的就是使用梯度下降法训练这个黑箱 使其的输入输出符合我们的要求 比如多分类
- 多分类问题采用 one-hot 编码 即向量代表 n 个类别 哪一位置 1 就是哪一个分类
- 使用 softmax 作为输出层的激活函数 就可以把输出转换为概率向量的形式 然后概率最大的那个就是预测的类别
- 基本结构
- 上层神经元和下层神经元连接对应一个权重
- 输入层是第一层 输出层是最后一层 隐藏层是中间的层
- 层之间的权重用矩阵表示 称为权重矩阵
- 净输入是输入的线性组合加上偏置量 也就是需要输入给激活函数的值
- 激活后的输出就是这一层的输出 也是下一层的输入
- 如何训练?
- 使用现有的网络做出预测
- 计算损失函数 量化预测和真实值的差距
- 对损失函数关于权重和偏置量进行求导 得到梯度
- 按照梯度相反的方向更新权重和偏置量
- 反向传播也就是一层一层返回去求导的过程
全连接神经网络
定义:每一层的神经元都和上一层的所有神经元相连 比如 4x4 的两层会有 16 个连接
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21model = Sequential([
Input(shape=(28, 28, ), batch_size=32),# 输入层 28x28 的图片
Flatten(), # 将图片展平为 1 维向量 也就是 784 x 1的输入
Dense(128, activation='relu'),# 全连接层 与上一层全连 也就是 784 x 128 的权重矩阵
Dropout(0.2), # 防止过拟合 随机丢弃 上一层 20% 的神经元输出 通俗理解就是防止神经网络只看到局部特征而误判
Dense(10, activation='softmax') # 输出层 10 个类别的概率向量
])
# 编译模型 优化器默认选择adam 损失函数是交叉熵 评估指标选择准确率
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# TensorBoard 可视化相关
logdir="logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
# 训练模型 输入训练集 代数为 10 次 回调函数为 TensorBoard
model.fit(x_train, y_train, epochs=10, callbacks=[tensorboard_callback])
# 评估模型 输入测试集 返回损失和准确率
model.evaluate(x_test, y_test)
# 保存模型为.keras文件
model.save("model.keras")
Keras
- Keras 是一个高级神经网络 API 把 TensorFlow、PyTorch 等深度学习框架封装到后端 提供了更加简单的前端接口
- 安装:先安装 anaconda 然后安装 keras 和对应的后端即可
12.11
Cloud Computing
- Grid Computing:云计算的前身 希望计算资源像电力一样即插即用 通过将自己的计算机资源放到网络上共享来实现(p2p?)
- Cloud Computing:将特定的计算资源 比如服务器 暴露并提供给其他人
- SaaS:Software as a Service 提供软件服务 比如 Office 365
- PaaS:Platform as a Service 提供平台服务 比如数据库、中间件等
- IaaS:Infrastructure as a Service 提供基础设施服务 比如虚拟机、存储等
- dSaaS:Data storage as a Service 提供数据存储服务 比如云盘、图床等
- 云计算的特性
- 灵活定价
- 弹性扩展
- 快速提供
- 预先虚拟化(提前划分好资源)
- Core teqs of Cloud Computing(以 Google 为例)
- MapReduce:分布式计算框架 负责云上的作业调度
- GFS
- Google 的分布式文件系统
- 通过 master 和 chunk server 来管理文件
- 使用 replica 保证数据的可用性 同时也带来了一致性问题
- 使用控制流和数据流分离的方式解决一致性问题
- Bigtable
- Google 的分布式数据库 适用于非常大的结构化数据存储
- 使用列族来存储数据 增强单表的表现能力 去掉表之间的关联 形成一个大表
- 使用元数据表存储数据的位置
- 和 LSMT 一样 数据先写入 memtable 然后写入 SSTable
- Memory
- 一般会进行计算存储分离
- Hadoop
- Apache 的开源分布式计算框架
- 使用 HDFS 作为底层存储
- 使用 MapReduce 作为计算框架
- Cloud Native(云原生):即开发、编译、部署都在云上进行 特点包括 serverless、容器化、CI/CD 等
Edge Computing
- 将计算资源放在靠近数据源的网络边缘 比如 CDN、边缘服务器等
- 好处包括 移动设备可以不用持续连接云端 以及减少了数据传输的延迟与带宽消耗
- Application
- Cloud Offloading:当节点的计算资源不足时 将计算任务分发到其他节点或者云上
- Video Analytics:视频无需发送到云 直接在摄像头上进行分析 在资源不足时再发送到云
- Smart Home:智能家居可以直接在家中的设备上进行计算
- 目前最多的是云边融合的模式
Graph QL
- RESTful 的风格是完全数据驱动的 无法细化描述用户的需求 比如只取出数据的某些字段
- GraphQL 是一种 API 查询语言 用于描述客户端如何请求数据
- Queries & Mutations
- Fields:需要返回的字段 比如:
1
2
3
4
5
6
7
8{
hero {
name
friends {
name
}
}
} - Arguments:参数 比如查询 id 为 1000 的人的 name 与 height:
1
2
3
4
5
6{
human(id: "1000") {
name
height(unit: FOOT)
}
} - Aliases:别名 当查询多个相同字段时可以使用 比如:返回数据会是:
1
2
3
4
5
6
7
8{
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}1
2
3
4
5
6
7
8{
"empireHero": {
"name": "Luke Skywalker"
},
"jediHero": {
"name": "R2-D2"
}
} - Fragments:片段 可以定义一些字段的集合 用于复用 比如:然后可以这样使用:
1
2
3fragment HeroFragment on Character {
name
}1
2
3
4
5
6
7
8{
hero {
...HeroFragment
friends {
...HeroFragment
}
}
} - Variables:变量 可以在查询时传入 比如:同时在查询时传入变量(即 variables={}):
1
2
3
4
5
6
7
8query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}1
2
3{
"episode": "JEDI"
} - Mutations:用于修改数据 比如:
1
2
3
4
5
6
7
8
9mutation {
createReview(
episode: JEDI
review: { stars: 5, commentary: "This is a great movie!" }
) {
stars
commentary
}
} - Inline Fragments:内联片段 可以在查询时定义片段 比如 hero 可能是人也可能是机器人:
1
2
3
4
5
6
7
8
9
10
11{
hero {
name
... on Droid {
primaryFunction
}
... on Human {
height
}
}
}
- Fields:需要返回的字段 比如:
- 使用
- 在后端预先写好 schema 文件 定义好接口与数据结构
- 当前端发送请求时 后端根据 schema 文件来解析与封装数据
AI-2:卷积神经网络
对于图像来说 全连接网络会导致参数过多 比如 100x100 3 通道的图像 有 30000 个参数 全连接层的参数会达到 30000x30000 个 因此需要卷积神经网络
为了提取局部特征 我们采用卷积核 卷积核是一个权重矩阵 通过卷积核和图像的卷积来提取特征 卷积核矩阵会和图像的一个区域做按位相乘 然后做累加得到一个值 这个值作为这个区域的特征 比如边缘特征的矩阵是
1
2
3-1 -1 -1
-1 8 -1
-1 -1 -1这是因为如果一个区域是边缘 这个累加就非 0 如果一个区域的颜色基本一致 这个累加就接近 0 这样就把边缘特征提取出来了
卷积核的尺寸可以是矩阵 一般为奇数 保证有一个中心点
对图像做卷积会导致图像的尺寸变小 因此需要 padding 来保持图像的尺寸 通常是在图像的外围填充一堆 0 保证卷积后的图像尺寸不变
卷积核的深度和图像的深度是一样的 比如 3 通道的图像就需要 3 个卷积核
池化:把一个区域的值映射到一个值上 比如最大池化就是把一个区域的最大值作为这个区域的值 目的是降低图像的尺寸 从而减少权重参数
如何训练?
- 卷积核矩阵的每一个数字都是一个参数
通俗理解 卷积网络负责把一个大图像提取特征为小图像 再把小图像输入到全连接神经网络里进行分类 从而大大减少权重参数 其中卷积层就是对图像做特征提取 池化层就是对特征图像做模糊处理
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15model = keras.Sequential(
[
Input(shape=input_shape, batch_size=32),
Conv2D(32, kernel_size=(3, 3), activation="relu"),# 二维卷积层 包含 32 个卷积核 每个卷积核是 3x3 的矩阵 这意味着会产生 32 个特征图像
MaxPooling2D(pool_size=(2, 2)),# 最大值二维池化层 池化核是 2x2 的矩阵
Conv2D(64, kernel_size=(3, 3), activation="relu"),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dropout(0.5),
Dense(num_classes, activation="softmax"),
]
)
model.summary() # 打印模型的结构 包括每一层的参数数量等参数计算:
卷积层:卷积核的数量 x (卷积核的尺寸 x 输入的深度 + 偏置量)
以上面第一个 conv 层为例 32 个卷称核 3x3 的卷积核 单通道 1 个偏置量 一共有 32 x (3 x 3 x 1 + 1) = 320 个参数 而输出的尺寸则是 32 x 26 x 26 x 32 即 32 个卷积核 26x26 的图像 批处理大小为 32
第二个 conv 层的输入应该是 32 张图像 每张图像有 32 个特征图 都是 13x13 的图像 这个 conv 层对于每张图像的 32 个特征图分别做卷积 产生 32 个特征图 然后做加权求和 产生 1 个特征图 于是输出就是 32 张 13x13 的图像 每张图像有 64 个特征图
同时第二层有 64 个卷积核 尺寸为 3x3 每个卷积核输入的特征图数量是 32 (相当于 32 通道) 所以参数数量是 64 x (3 x 3 x 32 + 1) = 18496
池化层:没有参数
以第一个池化层为例 2x2 的池化核 没有参数 输出的尺寸是 32 x 13 x 13 x 32 代表 32 个卷积核 13x13 的图像 批处理大小为 32
作业:使用 CNN 训练 CIFAR-100 数据集
- 将参数个数提高即可 加大 batch_size 可以提高收敛速度 基本上最后收敛在 0.97 左右
- 比较重要的是如何使用 GPU 进行训练 因为 CPU 实在是太慢了
- 参考链接:https://www.baidu.com/link?url=H3KSUXUjZ47N8E3A9JbgU_h0cexmuXSeWBVPDSXDHnAl_g5J2N0YLwwE_hCxyEaGh_LR1-P5btUiGp90MgiT_NAbksplygXvFMsF9auwMgi&wd=&eqid=84f566d90000822b00000003675c566a 大概就是要降级到 2.6 另外 cuda 可以用 conda 安装 不用装在本机上污染环境了
12.16
Container
- 容器是一种轻量级的虚拟化技术 用于隔离应用程序和环境 使用了 linux 的 cgroups 和 namespaces 技术
- Docker 是一个开源的容器引擎 使用了 Go 语言编写
- 使用:见隔壁笔记
- Named volumes vs Bind mounts
- 前者使用
docker volume create命令创建卷 并使用--mount source=xxx,target=xxx来将创建好的卷挂载到容器中 Docker 会自动管理卷的存储位置 通常用于无需访问数据的持久化 比如数据库 - 后者可以使用
-v参数来将本地文件夹挂载到容器中 通常用于需要访问数据的持久化 比如代码的热更新
- 前者使用
- 容器内部的分层主要是为了可以复用镜像 节省存储空间
AI-3:自然语言处理
NLP 是一种人工智能技术 用于处理和分析人类语言 包括:信息获取、文本分类、文档相似度推荐、机器翻译、聊天机器人、文本生成等方面
将词语变为向量的方法
- One-hot Encoding:将每个词语映射为一个向量 但是这样会导致维度爆炸
- 可以进行降维 比如每个维度是一种属性 身高、体重等
基本步骤
- 先构建语料库 比如历年的新闻 进行数据预处理 导出为方便处理的格式 比如 csv
- 使用默认的字典对语料库进行分词 得到自己的字典
- 对字典进行过滤 比如删去所有只出现一次的词语 以及常用词语
- 使用 BOW(Bag of Words)模型将语料库的每句话转换为向量
- 使用 TF-IDF(Term Frequency-Inverse Document Frequency)模型对语料库构建权重
- 使用 N-Gram 模型发现语料库中的短语(即多个词语的组合)
- 使用 Genism 的 LDA 模型进行语料库的分类
- 使用 LSI(Latent Semantic Indexing)模型进行语料库的分类 然后可以用余弦来计算相似度
使用 MLP 进行文本分类
- MLP 是多层感知机 也就是全连接神经网络
- 准确率不高
使用 CNN 进行文本分类
- 有一组已经分类的文本数据集 进行数据预处理 把词语转换为 n 维向量
- 使用 CNN 进行一维卷积 每一个卷积层相当于提取了 n 个单词之间的关系 池化层进一步收缩了单词 下一个卷积层相当于提取了 n*n 个单词之间的关系
使用 TextCNN 进行文本分类
CNN 如果数据中句子长度不一 会导致对于过短的句子强行填充 会导致效果不好
相比于 CNN TextCNN 只是多了一层 concat 层 把每一个池化层的结果拼接在一起在进行全连接 相当于提取了不同规模的短句的关系特征 适合句子长度不一的文本分类
示例代码:(多了一层 concat 层)
1
2# 合并3个Max Pooling 层
cnn = Concatenate(axis=1)([mp1, mp2, mp3])
12.18
Hadoop
- Hadoop 是一个开源的分布式计算框架 用于大规模数据处理
- Modules
- Common:公共模块 提供了一些 Util 类
- HDFS(Hadoop Distributed File System):Hadoop 的分布式文件系统
- YARN:负责任务调度与集群的资源管理
- MapReduce:基于 YARN 的分布式计算框架 负责并行处理大规模数据
- Ozone:分布式对象存储 用于存储大规模键值对
- 启动比较繁琐 自己看 ppt 吧
MapReduce
Overview
- Input:输入的数据集 划分为多个 split (其实就是 HDFS 的 block 默认大小是 64MB) 每个 split 由一个 mapper 处理
- Map:负责处理每个 split 产生形如(map,2),(map,3)的键值对 写入 Intermediate File
- Combine:(可选)在 worker 本地对 Map 的输出进行合并 比如(map,2),(map,3)合并为(map,5) 从而减少传输的数据量 注意不是所有任务都适合 Combine 比如求平均值就不能
- Shuffle:将 Map 的输出按照 key 进行排序 然后进行分区 比如 A-M 为一个分区 N-Z 为一个分区 将分区的数据传输给 Reducer
- Reduce:处理某个分区所有键值对 产生最终结果 写入 Output File
- reducer 的数量为 0.95 or 1.75 * worker nodes * containers per node 当节点的 CPU 性能比较好时可以设置为 1.75 否则设置为 0.95
Example:WordCount with Java
- 代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class); //combiner与reducer使用相同逻辑
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 代码示例:
JobTracker:在 MapReduce 中负责任务调度 资源管理(通过监听 TaskTracker 的心跳来管理)由于负载过重 会导致单点故障 因此在 2.0 中进行了分离
Problems
- mapper 在处理 split 时 会因为缓冲区不够大而进一步切分 split 然后处理一部分就写入一部分结果到磁盘 最后再合并结果 reducer 也是一样的问题 这就导致 IO 次数太多 速度受到限制 解决方法是在内存里处理数据 即 Spark
- 同时 split 划分后产生的 spill 文件 一旦发送崩溃 已经处理的 spill 就没有用了 解决方法是直接以 spill 为单位进行 shuffle 并发送给 reducer 处理
YARN
- 也就是 MRv2 MapReduce 的 2.0 版本 解决了 JobTracker 的单点故障问题
- 核心思想是将 JobTracker 的任务调度和资源管理分离出来 交给了一个全局的 ResourceManager 与每一个 application 的 ApplicationMaster 其中每一个 application 可以是单个 job 或是多个 job 的 DAG
AI-4:RNN(循环神经网络)
RNN 是一种递归神经网络 每一次的输出由上一次的输出和当前的输入共同决定 即 yi=f(yi-1, xi) 也就带上了之前所有数据的特征 适合预测时间序列数据与自然语言处理
RNN 的缺点是无法并行 因为每一次的输出都依赖于上一次的输出 另外 RNN 固定了依赖的长度 模型不够灵活 导致长期记忆的学习比较弱 这点可以通过 LSTM 来解决
LSTM(Long Short-Term Memory):长短期记忆网络 是 RNN 的一种变体 通过门控机制来控制信息的流动 具体而言 LSTM 有三个门:遗忘门、输入门、输出门 遗忘门决定了之前的状态有多少会被遗忘 输入门决定了新的状态有多少会被加入 输出门决定了这个状态有多少会被输出 虽然 LSTM 仍不能并行 但是单个 LSTM 单元内部的计算的并行度较好 比较适合长期记忆的学习
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 预处理数据 相当于将第i个数据的输入变为第i-look_back到i-1个数据
def create_dataset(data, look_back):
X, y = [], []
for i in range(len(data) - look_back):
X.append(data[i:i + look_back])
y.append(data[i + look_back])
return np.array(X), np.array(y)
X, y = create_dataset(scaled_data, look_back)
# 激活函数是tanh 所以需要将数据缩放到-1到1之间
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(time_series.reshape(-1, 1))
# 构建RNN模型 神经元数为50 输入形状为look_back 输出形状为1
model = Sequential([
SimpleRNN(50, input_shape=(look_back, 1), return_sequences=False, activation='tanh'),
Dense(1) # Output layer for regression
])
# LSTM模型基本一样
model = Sequential([
LSTM(50, input_shape=(look_back, 1), return_sequences=False),
Dense(1)
])
12.23
Spark
Spark 是一个分布式计算框架
- 用于大规模的流/批数据处理 支持多种语言 比如 Java、Scala、Python、SQL、R
- 支持执行分布式的 ANSI SQL 查询(即 Spark SQL)
- 用于数据科学与机器学习
- 与 Hadoop 相比 Spark 是在内存中进行计算的 拥有 100x 的性能(在内存足够的情况下)
Example:Log Mining(Scala)
1
2
3
4
5lines = spark.textFile("hdfs://...") // 读取文件 返回一个 RDD(Resilient Distributed Dataset) 类似于python的DataFrame
errors = lines.filter(_.startsWith("ERROR"))
messages = errors.map(_.split("\t")(2)) // 从错误信息中提取信息
cachedMessages = messages.cache() // 在内存中持久化 messages 此时才开始执行前几步的操作 因为 Spark 是惰性计算 用stage来划分任务
cachedMessages.filter(_.contains("mysql")).count() // 统计包含 mysql 的错误信息 count是一个reduce操作 会交给多个节点来执行Components
- 一个 Driver Program:用户交互的客户端 处于 SparkContext 的控制下
- 一个 Cluster Manager:Mesos、YARN、Kubernetes 默认是 Zookeeper
- 多个 Worker Nodes:每个节点都有自己的 executor 用于执行任务
Quick Start
sbin/start-master.sh:启动 mastersbin/start-worker.sh spark://<master-ip>:7077:启动 worker- 使用
spark-submit --master spark://<master-ip>:7077来提交任务 - Java
- 在 Java 中引入依赖 然后创建 session 编写代码逻辑
- 打包为 jar 包 然后使用 spark-submit 将 jar 包提交到集群中运行
- Scala
- 和 Java 类似 只是语法不同 也可以打包为 jar 包 然后使用 spark-submit 提交
- 可以通过
./bin/spark-shell来启动一个交互式的 Scala 环境
- Python
- 将 py 文件通过 spark-submit 提交到集群中运行
- 可以通过
./bin/pyspark来启动一个交互式的 Python 环境
Spark RDD
- RDD 即 Resilient Distributed Dataset 是 Spark 的核心数据结构 代表一个不可变的、可分区的、并行计算的集合
- RDD 可以通过两种方式创建
- 从一个已有的集合中创建 比如
val data = Array(1, 2, 3, 4, 5)然后val rdd = sc.parallelize(data) - 从一个文件中创建 比如
val rdd = sc.textFile("hdfs://...")就是创建了一个从文件中读取的 RDD
- 从一个已有的集合中创建 比如
- RDD Operations
- Transformation(产生新的 RDD)
- map:对每个元素应用一个函数
- flatMap:对每个元素应用一个函数并返回一个迭代器 如
flatMap(_.split(" "))就是把每个元素按空格分割然后摊平 - filter:过滤元素
- union:合并两个 RDD
- Actions(返回一个结果)
- reduce:对 RDD 中的元素进行 reduce 操作
- count:统计 RDD 中的元素个数
- collect:将 RDD 中的元素收集到一个数组中
- Transformation(产生新的 RDD)
- Partition
- RDD 需要进行分区 Spark 会为每个分区分配一个任务
- 可以使用
partitionBy方法来指定分区方式 比如rdd.partitionBy(new HashPartitioner(2))就是使用哈希分区器将 RDD 分为 2 个分区 - 假设有两个 RDD 需要周期性进行 join 操作 其中 A 进行了哈希分区 而 B 没有 从而在 join 操作时 生成的子分区会根据 A 的分区数来决定 如下图所示
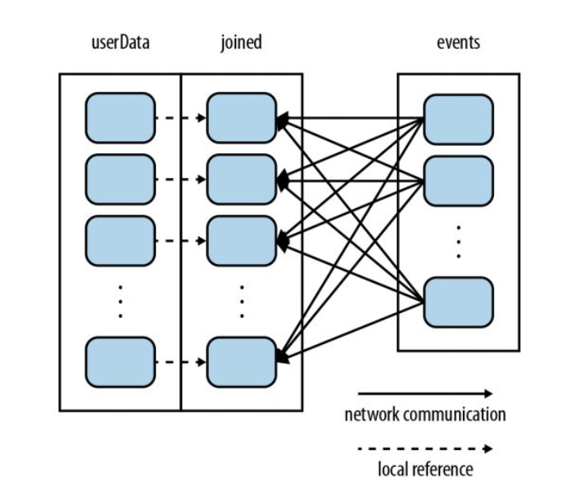
- Narrow Dependency:窄依赖 即 A 与 joined 的依赖关系 父 RDD 的每个分区只会被子 RDD 的一个分区使用 性能高 并且数据丢失时重计算快 map、filter、union 以及带有 co-partition 的 join 都是窄依赖
- Wide Dependency:宽依赖 即 B 与 joined 的依赖关系 父 RDD 的每个分区会被子 RDD 的多个分区使用 意味着多个节点之间的数据传输 性能低 groupByKey、不带有 co-partition 的 join 都是宽依赖 会导致 shuffle
- Stage
- 所有的 Transformation 都是 lazy 的 遇到 Action 时必须执行
- 除此之外 Transformation 会被划分为 stage 其边界处必须执行
- stage 的划分有两个依据
- 遇到宽依赖的 shuffle 操作
- 产生新的已缓存的分区
- 好处是减少内存占用 利用了窄依赖的高速计算 将操作尽可能推迟到宽依赖时才执行 使得窄依赖产生的 RDD 可以尽可能晚产生
- Persistence
- MEMORY_ONLY:将 RDD 缓存在内存中
- MEMORY_AND_DISK:将 RDD 缓存在内存中 如果内存不够则存储在磁盘上
- MEMORY_ONLY_SER:将 RDD 缓存在内存中 但是序列化
- MEMORY_AND_DISK_SER:将 RDD 缓存在内存中 如果内存不够则存储在磁盘上 但是序列化
- DISK_ONLY:将 RDD 缓存在磁盘上
- MEMORY_ONLY_2:将 RDD 缓存在两个节点的内存中
Spark SQL
- 即使用 SQL 语句来操作 RDD 比如
val sqlDF = spark.sql("SELECT * FROM table") - Datasets 是分布式数据集 DataFrame 则是以命名列的方式组织的 Dataset 也是不能修改的
- 可以通过
spark.read.json("hdfs://...")来读取 JSON 文件 生成一个 DataFrame - 然后使用
spark.sql("SELECT * FROM table")就可以使用 SQL 语句来操作 DataFrame
Other Issues
- Spark Streaming
- Spark 的流处理模块 可以处理实时数据流
- 实际上是多个微观的批处理 比如每隔 1s 处理一次数据 那么 1-2s 之间的所有新增数据就是一个批次
- MLlib
- Spark 的机器学习库 提供了一些常用的机器学习算法 比如分类、回归、聚类、协同过滤等
- GraphX
- Spark 的图计算库 提供了一些常用的图算法 比如 PageRank、连通分量、最短路径等
Storm
- Storm 是一个实时计算框架 用于处理实时数据流
- Architecture
- Nimbus:负责任务调度
- Supervisor:负责任务执行 监听每个 Worker
- Zookeeper:负责集群管理
- Topologies
- 由 Spout 和 Bolt 组成的 DAG 图
- Spout:数据源
- Bolt:数据处理
- Example:WordCount
1
2
3
4TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5); // 参数为 5
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word")); - Start:和 Spark 类似 也是先启动一个集群 然后提交 jar 包
Zookeeper
- Zookeeper 是一个高性能的分布式应用协调服务 用于管理分布式系统的配置、命名、同步等
AI-5:Chat-GPT
- GPT 是一个基于 Transformer 的模型 用于生成文本
- 原理其实很简单 就是预测下一个单词的概率
- 为了随机性 会在预测时加入一个温度参数
- 概率由语料库决定 首先确定每个字符出现的概率 然后确定一个字符出现后下一个字符的概率 以此类推产生了 n-gram 概率模型 就可以随机生成正确的单词
- 生成句子的过程是类似的 但是单词的数量太多了 必须降维 即把单词转换为向量
- 最后经过 transformer 模型的训练 就可以生成文本了
12.25
HDFS
HDFS 是 Google 使用 Java 编写的分布式文件系统的开源实现 适合大数据存储 并且适配低性能的硬件 不适合需要低延迟且多修改或文件较小的场景(修改的代价太大)
Architecture
- HDFS 是一个 master-slave 架构 包括一个 NameNode 和多个 DataNode 文件会被分为多个块存储在不同的 DataNode 上
- NameNode:负责管理文件系统的命名空间 包括文件、目录、权限等元数据 还需要维持文件块的复制策略 使得 DataNode 上的负载均衡 数据本身不会经过 NameNode 使得性能瓶颈不会出现在 NameNode 上
- DataNode:负责存储文件块的实际数据 通过心跳告知 NameNode 自己的存储情况与状态 使得 NameNode 可以维持文件的最小副本数
- 一般 NameNode 和 DataNode 会运行在不同的机器上 这是为了避免性能受到影响
- 尽管 HDFS 允许在一个机器上运行多个 DataNode 但是一般情况下一个 DataNode 会运行在一个独立的机器上 这样才能保证数据的备份与冗余是有效的
- HDFS 的使用和其他文件系统类似 有目录的层级 但是不支持硬链接和软链接
- HDFS 是一个 master-slave 架构 包括一个 NameNode 和多个 DataNode 文件会被分为多个块存储在不同的 DataNode 上
Replica Placement
- rack-aware placement:HDFS 会尽量把副本放在不同的机架上 以防止机架故障 但是这样也带来了 RTT 的增加
- 一般的 replica factor 是 3 其中至少有一个副本在一个不同的机架上 HDFS 会保证每一个机架上的 replica 数量小于
(总 replica 数 - 1) / rack 数 + 2
Safemode
- 当 NameNode 启动时会进入 safemode 用于检查文件系统的完整性
- NameNode 会检查当前连接的所有 DataNode 的 replica 数量是否满足大于等于最小副本数的要求 满足则退出 safemode 否则继续等待
Persistence
- NameNode 使用一个叫 EditLog 的文件来记录对文件元数据的事务操作 这个日志并非 HDFS 的一部分 而是存储在本地 OS 的磁盘上
- NameNode 还会有一个叫 FsImage 的文件 用于记录文件系统的元数据 包括所有文件块的映射与属性 同样的也是存储在本地磁盘上
- 每次启动时 NameNode 会读取这两个文件来恢复文件系统的状态 同样也有 checkpoint 机制 与 MySQL 的 binlog 类似
- DataNode 会每个块作为本地文件存储在磁盘上 并且启发式的分为多个目录存储
Communication
- HDFS 使用 TCP/IP 协议进行通信 即 RPC
Robustness
- 一旦一个 DataNode 挂掉 NameNode 会把这个 DataNode 上的块标记为损坏 并且会在其他 DataNode 上复制一个新的块以保证副本数量
- HDFS 会定期迁移数据块以保证均衡负载 保证了集群可以自动扩展 只需要增加 DataNode 即可
- 所有数据块都会有 checksum 用于检查数据的完整性
- 如果 FsImage 或者 EditLog 损坏了 NameNode 会从其他节点上的副本恢复数据(如果配置了多份副本)
Data Organization
- block size 默认是 128MB
- 读数据可以并发进行
- 写数据和 GFS 一样 需要异步的流水线操作 比较慢
HDFS 也有命令行和 WEB 界面 可以使用 Java 等语言来操作
HBase
- HBase 是一个分布式的、面向列的、基于 HDFS 的数据库 适合存储大量的结构化数据 是 Hadoop 的一个子项目
- HBase 的重点是大量数据的分布存储 并且非常灵活 其他类似于 Neo4j 的图数据库则是专门为某种非关系型数据设计的
Data Model
- HBase 的数据带有版本号 形成了一个三维的表结构 如果为空则读取最新时刻的数据 也就是说表是稀疏的 实际存储类似于 JSON
- HBase 的行是完全有序的 类似于 SSTable
- HBase 的列被划分为列族 相当于在列的顶层再加了一层结构 且列族内的列可以动态增加 导致数据是半结构化的 列族作为前缀标识数据
- Region
- 水平划分的数据块称为 region
- HBase 进行分布存储的单元就是 region
- Locking
- HBase 对于元数据文件会加锁
- Namespace
- 类似于数据库的概念 每个 Namespace 会有独立的权限管理
- HBase 要求在删除表前先 Disable 表
Architecture
- 也是使用 Zookeeper 来进行集群管理 底层存储则是 HDFS
- Master-Slave 架构
- Master:负责管理 RegionServer
- RegionServer:负责管理 Region 数据
12.30
Hive
Hive 是一个基于 Hadoop 的数据仓库工具(即将 Hadoop 转换为数据仓库) 用于让用户使用 SQL 来查询和管理大规模的数据(比如 Facebook 的数据)
Hive 的优势在于 数据可以以原始格式(如 JSON、CSV 等)存储在 HDFS 上 但仍可以通过 SQL 查询 即 Schema on Read 在查询时才会解析数据 初始加载数据非常快(同理 Schema on Write 的查询性能会更好)
DML(Data Manipulation Language)
- 使用
LOAD DATA INPATH '...' INTO TABLE table_name来加载数据 此时未做 ETL 操作 只是把原始数据放到本地的 HDFS 中 - 加载数据时可以使用
PARTITION (ds='2008-08-15')来指定分区 - 等对这张表真正进行查询时 比如
SELECT * FROM table_name才会对加载的数据进行 ETL 即把文件从 HDFS 取出 转换为 Parquet 的格式加载到 Hive 的表 然后使用 SQL 语句进行查询
- 使用
Architecture
- HiveServer:负责接收客户端的请求 并且将请求转发给对应的 HiveServer2
- Metastore:存储元数据 可以与 HiveServer 分开部署
Tables
- Partition & Bucket:分区与桶 桶是对分区的进一步划分 都是为了提高查询性能 另外桶的划分还方便了数据采样
Querying
- 支持 MapReduce 脚本
File Formats
- TextFile
- SequenceFile
- RCFile(Record Columnar File)
- 一种列式存储格式 先把数据按行划分为 Row Groups 然后再按列存储每个 Row Group 里的数据 适合 OLAP
- ORCFile(Optimized Row Columnar File)
- 与 RCFile 类似 在头尾加了一些元数据 默认 250MB 一个 stripe 适合 OLAP
- Parquet
- 一种列式存储格式 会进行差值压缩 适合 OLAP
Compression
- LZO
Flink
- Flink 是一个流式计算框架 用于处理有状态的数据流 即处理下一个数据需要依赖上一个数据的结果
- Basic Concepts
- Stream:数据流 包括无界流和有界流 Real-time 和 Recorded
- State:状态 即数据流的中间结果 保存在内存或磁盘上 周期性的做 CKPT 持久化 Keyed State 会使用哈希保证同一个 key 的状态会被保存在同一个 TaskManager 上
- Time:时间 有 Event Time 和 Processing Time 之分 前者是数据产生的时间 后者是数据处理的时间
- APIs
- SQL/Table API:把数据流当作动态表来处理
- DataStream API:对数据流进行 map、filter、join 等操作
- ProcessFunction:用于处理数据流中的每个事件
- Checkpoint (没听懂 讲的太烂了)
- Flink 会周期性的做 Checkpoint 用于保存状态 以便在失败时恢复回放
- 每个 Checkpoint 的两端会用一个称为 Barrier 的特殊事件来标记
- Flink 会等到不同的流都到达 Barrier 时 即对齐时才会进行 Checkpoint 然后把 Barrier 前的状态都落盘保存
- 需要保存的状态包括 流的位置、多个流输入时需要的 Barrier 状态、最终输出结果等
- 等待 Barrier 对齐会浪费时间 也可以做 Unaligned 的 Checkpoint 只需要把 Barrier 之前的所有输入状态与输出结果保存即可 但是同时记录的状态会更多 需要做权衡
- 使用 RocksDB 来异步存储状态数据 可以使最新的状态数据在内存中
- Watermark
- 用于处理乱序数据 会在数据流中插入一个 Watermark 用于标记数据的时间
- 比如 Watermark=10 表示 10 之前的数据都已经到达并且处理完毕
- 节点会记录水位线的最大值 接受多个输入时会取较小值
- 水位线是严格递增的 保证了多个流的数据不会交叉乱序 (不懂)
- Window
- 按时间划分数据流为 batch 可能会因为时间密度不均匀导致数据倾斜
- Architecture
- JobManager:负责任务调度
- TaskManager:Worker 中负责执行任务
- Flink Program:用户编写的程序
AI-6:Transformer
- Transformer 是一个用于处理自然语言的模型 由 Google 提出 解决了 RNN 的并行问题
- 多头注意力机制:
- 掩码机制
- 注意力机制
- Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
- 自注意力机制:计算每一个词与句子中其他词的关系
21 年卷
一
两者都选 session
首先 service 不能设为单例 单例无法为每个用户维护不同的计时器状态 也不能设为 prototype 因为会在每次调用 service 时创建新的实例 无法计算时间
然后 controller 需要调用 service 设为单例需要在代码上手动注入 service 的 bean 另外单例并发性能一般 prototype 则浪费实例 最好的还是 session 一个 controller 对应一个 service看情况
异步通信机制通过将任务尽可能的延迟来保证所有任务都能被最终处理完毕 如果说网站在白天的访问量超出负荷 在晚上则比较空闲 那么使用异步通信 可以减轻白天访问请求的压力 让用户在立即获得响应的同时 所有请求在后台还可以真正得到处理
但是如果访问量本身超出了一天处理的最大量 使用异步通信也无法让所有的请求都得到处理 即使用户立即得到了响应 最终请求也会溢出 反而因为消息队列的开销而导致负担更大使用事务
orderProcess 整体是一个事务 progation 为 required
placeOrder 与 shipping 方法放入同一个事务当中 设置 progation 为 required 保证加入父事务
log 的 progation 为 requires_new 保证其出错不会影响订单的处理创建新的对象即可 比如 a 是一个不可变对象 想要将 a 加 1 则创建一个新的对象 b=a+1
缺点是需要大量的对象占用内存第一 redis 是一个功能完整的内存数据库 支持日志回放 因此 session 存储在 redis 中 当服务器重启时 session 不会丢失
第二 redis 的使用相当于存算分离 可以解耦服务器的计算与 session 的存储 得以解决 session 共享的问题 比如 A 与 B 的 session 都存在 A 的 redis 里即可
第三 redis 有主从复制功能 可以增加读的性能和数据的可靠性web 服务是指无视 OS 与语言的服务 意味着服务的协议 语言 os 都解耦 方便第三方调用 具有跨平台 模块化等优点
restful 是一种 web 服务的设计风格 通过 uri 定位资源 通过 http 请求方法来操作资源 语义清晰的表达了资源的操作 对于用户非常友好使用网关 gateway 比如 nginx
具体而言 gateway 是一个单一请求的端点 处理所有请求 根据请求的 url 来解析 转发到对应的服务
每个服务会把自己的 ip 和端口注册到注册中心 比如 zookeeper 然后 gateway 会从注册中心获取服务的地址
二
tableopencache 是 MySQL 可以打开的表的最大数量 innodb_buffer_pool_size 是 InnoDB 缓冲池的大小 前者限制了所有连接可以打开的表的数量 存储的是 fd 后者限制了内存中表数据的大小 存储的是表中的数据
快照备份 增量备份的一种 通过 COW 来记录每一次修改 当改变达到阈值后进行一次全量备份 MySQL 本身不支持 必须使用 LVM 或者 ZFS 等文件系统
看情况
这种分区方式适合查询经常基于 oid 的场景 比如经常查询某一个 oid 的订单 或是 oid 本身按照时间排序 那么查询某一个时间段的订单可以转换为查询某一个分区的订单 此时 mysql 可以进行剪枝
如果查询并不基于 oid 比如需要查询某一个用户的 那么这样的分区是无意义的MongoDB 将 collection 分为小的 chunks 称为 shards
数据库会为每个分片的 collection 创建一个 router 存储分片的元数据
当添加或减少 shard 时 MongoDB 会自动迁移数据 使得数据均匀分布
shard 是一个服务器节点上的分片 一个 shard 包含多个 chunk MongoDB 会限制每个 shard 之间的 chunk 数量不能超过一定的阈值
用户选择用来分片的字段称为 shard key 按照 shard key 的值范围 数据会分为不同 chunk 当一个 chunk 的数据量超过阈值时 MongoDB 会自动分裂这个 chunk 并且把新的 chunk 迁移到其他 shard 上
新添加一个 shard 时 MongoDB 会把一部分 chunk 迁移到新的 shard 上 删除同理
有时不希望数据均匀存储 可以关闭 chunk 数量的限制 改用自己写的 balancer 保证数据访问的均衡关系型数据库的 join 操作是 O(n^2) 的 复杂度太高 导致某些关系复杂的查询涉及到大量的表连接 非常耗时 示例中需要查询某一本书籍的所有回复 就需要先把书籍和评论进行 join 然后把评论和回复进行 join
在图数据库中 这样的查询变得非常简单 只需要从书籍节点向外进行探索 找到具有关系的评论节点的边 然后再找到评论节点的回复节点即可空间放大是指数据库中存储数据占用的空间比实际数据量大很多 lsmt 数据库并不存在这种问题 因为额外的存储只有一些索引数据和已经被删除的数据 lsmt 数据库通常使用定期 gc 和合并来清除无用的数据
写放大是指磁盘的 IO 操作比实际数据量大很多 lsmt 数据库会有写放大的问题 因为在某些操作触发多次 compaction 时会产生大量的 IO 操作wal 的作用通常是用于记录事务操作 保证数据的持久性和原子性
持久性是说 我们通常为了性能会使用异步落盘 即事务完成但是操作不落盘 此时需要保证操作不会丢失 redo log 会记录所有的操作 以便在重启时恢复 注意 虽然现在还是需要 IO 但是从随机写变为了顺序写 性能是有所提升的
原子性是说 我们为了少占用内存 一般会尽可能快的将事务中的操作提前落盘 但是如果在写入过程中出现了错误 那么就需要回滚操作 undo log 会记录所有的操作 以便在回滚时恢复
三
iphash 是根据 ip 确定转发的服务 缺点包括负载不均衡 比如某些 ip 会产生大量的请求 其全部会转发给同一个服务 造成不同服务负载不均衡 另外 iphash 也不能完全解决 session 粘滞的问题 因为用户可能会在不同请求切换 ip
使用 docker volume create 命令创建卷 并使用–mount source=xxx,target=xxx 来将创建好的卷挂载到容器中 Docker 会自动管理卷的存储位置 通常用于无需访问数据的持久化 比如数据库
mapper 在处理 split 时 会因为缓冲区不够大而进一步切分 split 然后处理一部分就写入一部分结果到磁盘 最后再合并结果 reducer 也是一样的问题 这就导致 IO 次数太多 速度受到限制 解决方法是在内存里处理数据
另外 mapreduce 本身的中间结果文件也需要大量 IOspark 中对于 rdd 的操作分为两种 transformation 和 action
所有的 Transformation 都是 lazy 的 遇到 Action 时必须执行
除此之外 Transformation 会被划分为 stage 其边界处必须执行
stage 的划分有两个依据 遇到宽依赖的 shuffle 操作或是产生新的已缓存的分区
因此可以减少内存占用 利用了窄依赖的高速计算 将操作尽可能推迟到宽依赖时才执行 使得窄依赖产生的 RDD 可以尽可能晚产生hdfs 有机架策略 即其中至少有一个副本在一个不同的机架上 一般而言 hdfs 尽量寻找最近的副本 比如先找同一个机器的 再找同一个机架的 再找其他机架的
列族使得数据变为半结构化的 存储比较灵活 支持列的动态增加 增强了单个表的表现能力 形成一个大表 另外通过列族相当于进行了垂直分表 支持了行列混合存储 动态应对不同场景的数据存储需求 比如 OLAP OLTP
22 年 A 卷
一
首先 数据库连接池的大小和用户数并无直接关系 数据库连接池指的是 mysql 提供多少连接给服务器的后端应用 理想情况下 连接占满了 CPU 核心与硬盘的连接是最快的 因此数据库连接池=核心数*2+有效硬盘数
其次 过大的数据库连接池会让 mysql 花费大量的开销在维护连接池中的实例状态 以及上锁保证并发安全上 导致性能反而大大降低事务是用于保证操作原子性的 然而没有事务不一定意味着系统一定会出现异常 比如系统所有方法都正常的执行没有出现错误 自然每一个方法也就维持了原子性 并不会出现事务方面的异常
payOrder 可以不设置事务 视情况而定
pay 与 shipping 都设置 progation 为 requirednew 使得无论如何都会新建一个独立事务第一 消息队列会比同步处理需要更多的开销 如果访问数量超出处理能力限制 只会导致服务器的负载更大 如果遇到这种情况 增加硬件性能
第二 消息队列相比于同步处理 需要在后台异步返回操作的真正结果 这需要额外的代码逻辑与通信开销 一般可以使用 websocket 实现 让处理结果通过 ws 发送给前端无需对对象使用 sync java 中每个对象都具有一个锁 在 sync 修饰的代码块中 所有对象的锁会被获取 无需显式标明
不合理 存在两种场景的问题
第一 高并发场景下 订单放入 redis 后 放入数据库前的状态是不一致的 查询会查出这个订单 然而其并不存在于数据库中
第二 容灾场景下 存入 redis 后 放入数据库前若服务器崩溃重启 redis 中订单仍存在 但数据库中不存在 导致查询一个不存在于数据库的订单
一般为了保证一致性 都是先写入数据库 再写入缓存 就算在中间状态查询 也只会因为 redis 里不存在而把数据提取到 redis 中 只有性能影响而没有数据一致性问题单点认证是指用户只需要登录一次就可以访问所有的应用 在单台服务器上 session 足以做到 但是在分布式集群中 因为会话粘滞的问题 通常使用 jwt 来实现单点认证
具体而言 jwt 是服务器根据用户信息生成的一个 token 发回给客户端 维护在客户端的 cookie 中 服务器通过验证这个 token 本身的正确和完整性来验证用户的身份 而无需维护任何状态 使得可以在多个服务器上实现单点认证mysql 的全文索引是通过倒排索引的结构实现的 即从 term 到 document 的映射 维护一个 term 在哪些 doc 中出现过 当我们需要搜索某一个 term 时 只需要在倒排索引中找到这个 term 对应的 doc list 然后进行相关度排序返回即可
注册中心会维护各个服务的 ip 与端口 当 gateway 需要转发给某种服务时 只需要在注册中心中寻找一个服务的实例即可 主要实现了服务实例与服务器实体间的解耦 隐藏了服务到对应 url 的映射 使得服务的调用更加简单
并非正确 restful 风格的服务是通过 uri 定位资源 通过 http 请求方法来表明对资源的操作 使用注解并不代表其 api 是 restful 风格的 比如对于一本书的增加可以用 post 方法 但是如果使用 get 方法 参数全部写在 requestparam 中也可以实现 但是这样就不是 restful 风格的
二
无损连接分解是指将一个表分解为多张表后 可以通过 join 得到一模一样的原表 目的是保证数据的完整性 使得查询更加高效 并且减少数据冗余
最小化重复信息是指尽可能减少数据的冗余 一般是为了节省存储空间 并且保证数据的一致性缓冲池多实例主要是为了提高并发性能 建立多实例后 同一张表可以存储在不同实例中 进行并发的读写操作
char 类型是定长字符串 占用空间固定 varchar 则是变长 可以压缩存储
使用 char 类型的好处是不需要维护额外的长度信息 并且查询时更快?适用于数据长度固定的场景 比如 id
缺点是无法节省空间 并且对于变长数据会浪费空间物理备份是指将整个数据库的数据文件进行拷贝 逻辑备份是指记录数据库的所有操作逻辑 通常而言 逻辑操作的备份空间更大 因为要记录很多语句 并且恢复速度也是物理备份快 只需要拷贝文件即可 逻辑备份则需要逐条执行语句
缺点是适用范围小 通常不同数据库 甚至不同版本的数据库都不通用一个物理备份 而逻辑备份则可以分区除了扩展空间以外 还可以带来各种读写性能的提高 比如按照时间分区数据 当我需要按照时间范围查询时 mysql 会通过分区进行剪枝 减少了查询涉及的数据量 相当于初步的索引
另外 分区表也可以用来维护父子数据 比如各个地区的数据 在统一维护时可以通过 mysql 的 exchange partition 来实现看情况 对于电子书店 有些数据适合 MongoDB 存储 比如书籍的评论回复 但是某些需要双向查询的数据 比如订单与书籍 需要在两边都维护外键关系 这样就不适合 并且 MongoDB 也不是万能的 事务更加复杂 而且也不能自动维护数据的一致性 当需要维护一致性时 MongoDB 需要手动找到所有的引用并且更新
influxdb 中 有两类字段 fields 和 tags 其中 fields 不参与索引 这告诉我们 如果需要在某一个列上进行查询 把它设为 tags 而不是 fields 因此不会影响数据访问的效率 fields 在语义上一般就是用于数据分析 需要全表扫描的字段
是的 负载均衡会使得请求以一定比例转发给不同的实例 比如 1:3
如果数据在写入时是以 raw 形式存储的 在进行数据分析时 需要先对数据进行清洗 以便提高数据的质量 使得数据分析更加准确 然后再进行转换与加载 确保数据最终以合适的格式存储到数据仓库中 方便进行分析操作 不进行处理的数据往往是非结构化的 难以进行分析
在 worker 本地对 Map 的输出进行合并 比如(map,2),(map,3)合并为(map,5) 从而减少传输的数据量 注意不是所有任务都适合 Combine 比如求平均值就不能
combine 与 reduce 的区别在于 前者是在 mapper 的本地上进行的 目的是减少传输的数据 后者是在 reduce 上进行的 目的是得到最终的结果
22 年 B 卷
一
正确
影响不大 因为 log 是顺序写
同 A 改为 required payorder 也需要改为 required
错误 ajax 异步发送时对于前端响应速度的优化 和前端发送请求给后端没有关系哈 比如一个请求 通过 ajax 发送 可以使得页面不会阻塞 但是请求的结果仍要等待后端处理结束 消息队列解决的就是这个问题
是指一个线程可以多次获取一个锁 用于递归与嵌套调用 防止死锁
不合理 会导致数据不一致
是的 尽管有 RSA 加密 如果传输被人截断 还是可能产生中间人攻击 ssl 保证了传输的安全
tf-idf 算法对于搜索结果文档进行了相关性评分 具体而言 关键词出现的越多 并且关键词本身在所有文档中出现的越少 说明这个文档的相关性越高 鉴于我不知道支持度和置信度是什么东西 回答不了
不是 但是注册中心有很大的作用 如果没有 编码非常麻烦 gateway 需要维护所有服务的地址
否 见 A
二
BCNF 虽然保证了更强的数据完整性 但是会导致表的拆分过于复杂 在实际考虑中 通常做权衡 第三范式已经足够了
变种 LRU 策略 根据数据的热度来替换 会把新数据放到 3/8 的队列位置 队里的数据被访问时则会被放到队尾 如果是冷数据则会迅速的被挤到队头移出 还会做一定的数据迁移 把热数据放到其他地方
同上 varchar 适合存储变长数据 节省空间 但是有额外的长度信息 查询更慢
使用 flush logs 指令将 binlog 写入磁盘并切换到下一个 binlog 文件 恢复数据库时 先进行全量恢复 然后找到对应时间的 binlog 文件进行重放直到恢复到指定时间点
子分区支持在分区里继续分区 可以使用不同的字段和策略 比如按照时间分区后再按照地区分区 优化细粒度的查询
基于 R 树 快速查询空间数据
见 A
多主多从相对于一主多从 需要额外的开销确保多个主数据库的数据一致性 写入性能会更差 包括高并发 2pc 通信开销等
数据分析 即 OLAP 的场景下 通常需要对一个列的数据进行聚合操作 因此数据湖中存储面向列存的数据更加适合进行数据分析 并且列存还支持更多的压缩算法
map 类 这个操作把一个 list 变为另一个 list 符合 map 的语义 另外 过滤操作尽早的进行 可以减少传输的数据以及 reduce 需要处理的数据量 减少无谓的计算
23 年 A 卷
一
连接池=核心数*2+有效硬盘数=16*2+2=34 连接池本质上是线程 一个核通过超线程可以处理两个线程 因此 16*2=32 另外磁盘还需要异步的读写操作 因此需要 2 个连接(也即是说 CPU 在运行时 磁盘 IO 是在空转的)
合理 通常维护一个 websocket 的连接需要的开销比较大 包括心跳状态的维护等 因此用户通过 ws 接收到结果后 可以删除此会话以减少服务器的负担
undolog 可以是逻辑日志或是逻辑物理日志 不可以是物理日志 因为 undolog 要求操作可逆性 即逆向执行日志可以撤销操作 物理日志不满足 因为数据页的偏移可能已经被修改 而物理逻辑日志可以通过页面前后指针来完成回滚 逻辑日志显然可以通过执行语句来回滚
优点是保持了数据的一致性 即使在中间状态查询也不会出现数据不一致的情况 因为都会到数据库中查询数据 缺点是性能会有所下降 因为需要查询数据库 并且重新加载数据到缓存中
当等待锁的时间非常短 以至于小于线程切换的开销时 使用自旋锁比 wait 更加高效 因为 wait 会导致线程切换的开销
RESTful 的风格是完全数据驱动的 无法细化描述用户的需求 比如只取出数据的某些字段 而 GraphQL 可以根据用户的需求返回不同的数据结构 更加细粒度的控制数据的返回
微服务架构确实会影响系统性能 最主要的原因就是微服务架构中各个服务之间的通信从进程间通信变为了网络通信 还需要额外的序列化和反序列化的开销 以及网络传输的开销 但是使用微服务架构往往是一种权衡或是无奈之选 牺牲性能换取更好的可维护性和可扩展性 或者当单个服务器已经不足以支持业务需求时 必须扩展为分布式的微服务架构 另外 通过消息队列等异步通信可以减缓微服务架构的性能问题
二
首先 使用 varchar 存储 base64 编码的图片数据是不合理的 因为图片数据本身较大 base64 编码后会更大 而 varchar 类型是直接存储在数据库中的 当一个数据行超过半页时 查询效率会非常低 甚至因此导致数据行 size 的限制 很有可能根本无法写入 更好的方法是使用 blob 类型存储图片数据
其次 是否需要专门用 MongoDB 存储图片数据 答案是不一定的 mysql 的 blob 也比较适合存储图片数据 但是当数据量非常大时 关系型数据库不再是最优的使用场景 可以考虑使用 MongoDB 存储图片数据 其对于大数据量的存储和查询有更好的优化以前考过 为了并发
上课讲过 innodb 存储数据有限制 包括
在声明 MySQL 中一张表的字段类型时 一行数据最多 65535 字节 其中 char 是严格按照声明的长度存储的
在 InnoDB 引擎的实际存储中 一行数据最多存储不超过 innodb_page_size 的一半(实际会略小于一半)
声明时 VARCHAR 类型的长度可以超过 innodb_page_size 的一半 因为不知道实际存储的数据大小
CHAR 类型由于是定长 声明多少就会占用多少空间 所以总共加起来不能超过 innodb_page_size 的一半
第一条语句全部是 char 一个数据行已经大于了半页的大小了 因此报错 第二条语句是一个 varchar 其需要额外的长度信息 2byte 刚好 65535 字节 因此可以声明分区除了扩展空间以外 主要为了查询性能 我们可以根据查询场景进行合适的分区 比如经常需要查询最新的订单 可以按照时间分区 经常需要查询某个地区的订单 可以按照地区分区 这样可以减少查询的数据量 提高查询的效率
23 年 B 卷
一
见 A 一样
合理的 既然需要保持通信 那么就需要维护 ws 连接 相应的增加一些开销
redolog 需要幂等性 重复执行不会产生不同的结果 逻辑日志不满足
失败可重做性 日志执行失败后 可以通过重做达成恢复 逻辑日志不满足 因为一条逻辑记录可能对应多项数据修改 比如数据表和索引 因此必须使用物理日志优点 分表之后 多读少写的数据放入了 redis 提高了读取的速度 并且完全不会有写入的开销 缺点是在返回完整的 book 数据时 需要同时查询两边的数据并进行 join 有一定的性能开销
应对多读少写的场景 只有在修改数据时才进行拷贝
应对低并发且需要保持数据库原子性的场景 在低并发情况下 不会有多个请求同时对一个对象进行写 因此可以通过读写分离进行原子性的写 另外 cow 也可以用于快照备份 传统的快照备份需要拷贝整个数据库的状态 然而 cow 技术可以只保存指针 并只为修改过的数据创建副本 减少了存储空间同 A 需要细粒度的控制数据的返回时
如果数据量不大 不需要扩展 并且也不需要高容错性 与高并发性 或者磁盘的 IO 能力足以应对需求 那么是可以的 反之如果数据量大 需要高容错性 高并发性 那么就需要考虑使用分布式数据库 或是主从复制的数据库集群
二
针对不同场景 见 A 通常数据量较大适用于 MongoDB
把新数据放到 3/8 的队列位置 队里的数据被访问时则会被放到队尾 如果是冷数据则会迅速的被挤到队头移出 针对需要频繁访问热数据 数据访问不均匀的场景 解决了 LRU 策略的缺点 即冷数据在缓存中占用太久
见 A 第二条语句是 TEXT 在数据库中只存指针 因此声明时只占用 8byte 显然可以声明
见 A 根据查询场景进行合适的分区即可