《计算机系统工程》课程笔记
LEC 2: The Case for A Distributed System
- 现代互联网应用具有的特征:
- 高请求率 每日数以百万计的请求
- 大量的数据 包括图片视频
- 对用户透明:用户不会知道服务器的状态 即无感知
- AI 带来的新需求:需要高算力(GPU)
Case Study:以淘宝电商平台为例
旧时代的单主机部署:LAMP(Linux+Apache+MySQL+PHP)这种架构无法扩展 单主机的资源始终是有限的
如何扩展架构性能?
分解应用:做出专门定制的硬件 比如专门用于存储数据的服务器 将架构分解为应用、文件系统、数据库三台服务器 通过内网连接
缓存:为了避免频繁的数据访问 进行缓存 加快处理速度 和 1 同理 也可以做出专门作缓存的内存特化服务器
后来也就产生了几个分布式缓存系统 比如 Redis 和 Memcached 而分布式带来的问题是 键的哈希方法 如果用传统的取模哈希 增加新的服务器时就会需要大量的重写 于是采用了 Consistent hashing 的方法(后面会细讲)
更多的应用服务器:无状态的应用服务器是很容易扩展的 因为只需要一模一样的复制即可 而有状态的应用(比如用户的会话状态)比较复杂 需要在分布式中进行数据的同步
对于分布式的应用服务器 需要负载均衡 可以使用 http 重定向、反向代理等方式,轮询、随机、哈希等策略来实现
扩展数据库:两种方式 一是做主从复制 二是分库分表
分布式文件系统:比如 NFS、GFS 等 和分布式数据库比较类似
使用 CDN:通过内容分发尽可能的减少网络延迟 是一种变相的缓存
分离不同的应用:比如阿里分为了支付宝和淘宝 可以使用 k8s 进行集群部署
分布式系统的 fault 会很多 所以我们希望分布式系统有较好的容灾能力 比如个别集群内的服务器宕机 整个系统仍然可以正常使用
分布式系统需要实现高可用性
- 复制备份:复制一样的系统做同样的事 来作为当前系统的备份 困难是如何维护一致性 比如写完 A 后 还没有复制到 B 就崩溃了
- Retry 重试:发一次请求失败后再发一次 如果能得到正常响应即可视为正确
分布式系统的 CAP 理论
Consistency:所有节点看到的数据是一致的 比如 linearizability
Availability:每次请求都能及时响应
Partition Tolerance:即使局部网络故障 也能保证系统正常运行
Consistency、Availablity、Partition 三者不可能兼得
举例:(不严谨 实际上有更严谨的论文证明)
假如有两个分区 S1 和 S2 它们之间的连接完全断开 为了符合 P 用户 C 将仍能正常使用 S1 和 S2 接下来 C 给 S1 发送一条
A=V1的请求 为了符合 A S1 必须立即响应请求给 C(否则就相当于有一段时间系统不可用)如果这时 S1 和 C 的连接断开 C 将只能向 S2 进行查询 此时获取的数据就是和之前不一致的了(因为 S1 没办法和它保持一致)因此我们必须要做权衡 P 是比较必要的 因为不能指望单主机可以做到可靠 因此在 A 和 C 里进行二选一
淘宝这样的应用就会选择 A 尽管可能会产生数据不一致(比如一本书卖个了两个人) 带来的损失也不大(退款呗)
支付宝这样的应用就要选择 C 毕竟转账支付不能产生不一致 要不然会被钻漏洞或者起诉 这也是为什么支付宝转账会比较久(在同步数据)
当然 如果没有网络故障 CAP 还是可以达到的 理论只是告诉你一个分布式系统不可能永远保持 CAP
分布式系统需要哪些属性(审视系统的五个维度)?
- 可扩展性
- 性能
- 故障容忍度
- 一致性
- 易用性
可用性和可靠性

LEC 3: File System 1
iNode-based File System(单机文件系统)
一个文件有两个属性:持久化且有名字
磁盘会提供最简单的读写数据两个 API 而驱动会抽象成文件系统需要使用的更复杂的 API
文件为了可扩展性 需要设计成分布式的存储 即不连续的 sector 那就得使用元数据来存储这个 sector 属于哪个文件
7 software layers
L1:Block 层
- 提供的映射是 block number 到 block data 即根据 block_id 找到对应的数据
- block 是文件系统中数据管理的基本单元 包含连续的多个 sector 可以调整大小
- 第一个 block 是 Boot block 第二个 block 是 super block 用于存储文件系统的元数据 比如 block 大小、空闲的 block 数、free block 的列表以及其他元数据
- block 大小不能太大 会有空闲 不能太小 会浪费效率
- 如何高效跟踪 free blocks:后面跟着一个 bitmap 存储所有 block 是否空闲 不过这样要查找一个空闲块就需要遍历了
L2:File 层
- 一个文件拥有一个 inode(index node)其会存储文件的元数据 包括这个文件有哪些块以及 file 的 size
- 提供的映射是 inode 中的 block index 到 disk 上的 block number 比如 inode-1 的第 3 个 block 对应的 block number 是 178 利用这个映射 就可以实现从 inode offset 到 block data 的映射
- inode 对于大文件来说会很大 所以会做多层映射(类似多级页表)也就是 inode 指向另一个 inode
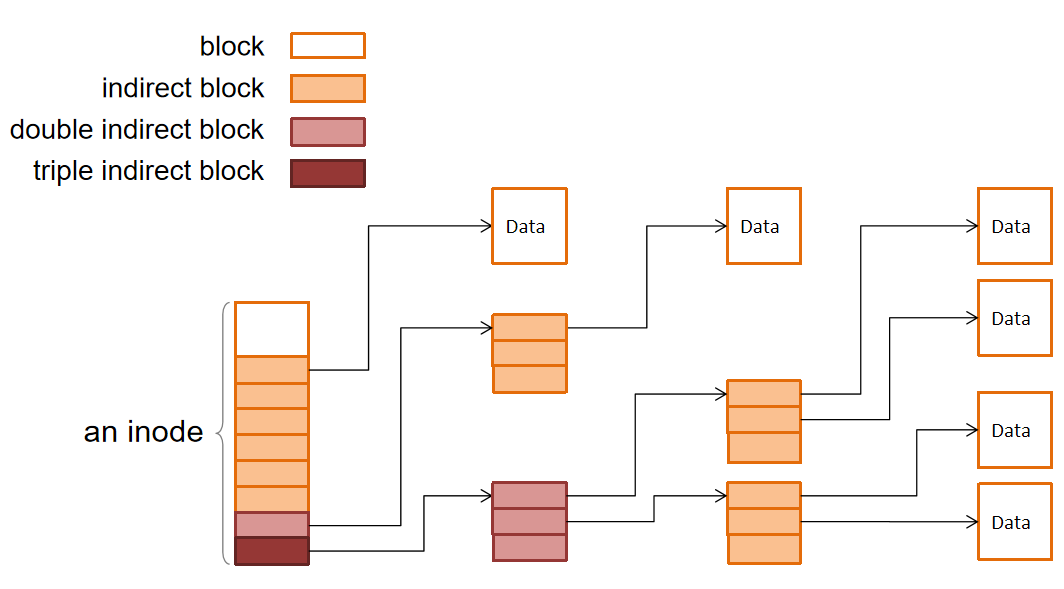
L3:Inode Number 层
- 提供的映射是 inode number 到 inode
- 在 free blocks bitmap 的后面存放了一个 inode table 其存储了 inode 的位置 inode number 就是 inode table 的 index
在此暂停一下 整合上述三层
- 已经可以提供 inode number 到 block data 的映射 比如 inode number 为 1、offset 为 4096 的 block 是哪个
- 已经足以用于操作文件 但是使用 inode number 操作对于用户不友好 并且在不同的设备上 inode number 会不同 因此引入了文件名
- 数据分布图

L4:File Name 层
- 提供 flie name 到 inode number 的映射 便于根据文件名查找文件
- 这个映射存储在一个文件里 名为 directory(目录)
- 默认的上下文是当前工作目录(current working directory)上下文的引用实际上是一个 inode number 而当前工作目录也被视为一个文件 因此 inode 结构中需要 type 字段区分文件和目录
- UNIX6 中 filename 最长为 14 个字符
L5:Path Name 层
提供 path name 到 inode number 的映射
查找的过程相当于从 pwd 开始不断打开下一层目录 直到找到文件
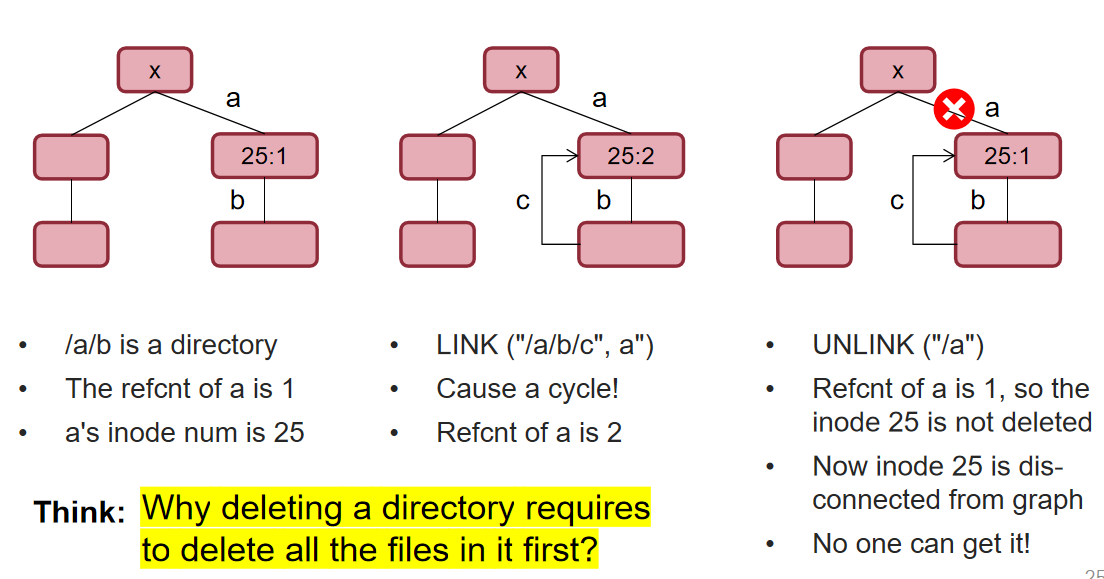
LINK 指令可以为文件创建一个快捷方式 不能为文件夹创建快捷方式 因为会导致环路 这两个文件名指向同一个 inode number
.和..都是硬链接UNLINK 指令会溢出一个文件名到 inode number 的连接 如果这是最后一个连接 那么就会释放 inode 和 blocks 因此需要一个 refcnt 记录 inode 有多少个连接
RENAME
- 先 unlink to_name 然后 link from_name 到 to_name 最后 unlink from_name 通常会在 tmp 文件里操作 如果中途崩溃 to_name 就会丢失 需要原子性
- 抛弃第一步 unlink to_name 这样即使中途崩溃 to_name 也不会丢失

L6:Absolute path name 层
- 每个用户都有自己的 pwd 也就是 home 但是不同用户无法访问其他用户的文件 为此引入了根目录
/根目录的 inode number 为 1 - 如何找到一个文件
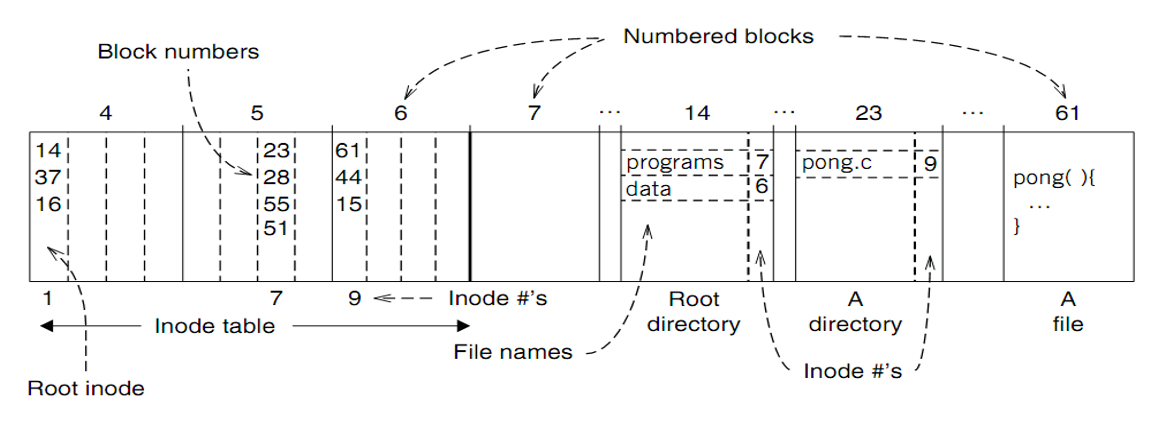
- 每个用户都有自己的 pwd 也就是 home 但是不同用户无法访问其他用户的文件 为此引入了根目录
L7:Symbolic Link 层(软链接)
- 不同的磁盘上 inode number 会不同 为了能够访问其他磁盘的文件 引入软链接
- 硬链接指向了 inode 而软链接记录了路径这个字符串 因此文件即使不存在也可以创建软链接
- bash 在 cd 一个软链接后 会自动记住旧的 pwd 从而
cd ..可以回到原来的目录 如果需要真正的上级目录 可以使用cd -P ..会回到新的 pwd 的上级目录 - LINK 不能成环
Summary
- 文件名不是文件的一部分 而是存在 directory 里的一个字符串 正因此 重命名实际上只能通过创建新文件来实现
- 硬链接是等价的 不存在先后主次
- directory 存储了各个文件名 是很小的 不像电脑里展示的那样 文件夹大小包含文件
LEC 4: File System 2
File System API
一个完整的 inode 结构
- block_nums[N]:存储文件的 block number
- size:文件大小
- type:文件类型
- refcnt:文件的引用计数
- userid:文件的所有者
- groupid:文件的所属组
- mode:文件的权限
- atime:最后访问时间 BY READ
- mtime:最后修改文件时间 BY WRITE
- ctime:最后修改 inode 的时间 BY LINK
OPEN
- check 用户权限
- 更新 atime?
- 返回一个 fd 描述符(fd 也可以表示其他硬件 比如键盘显示器等 每个进程有自己独立的 fd namespace)
- 为什么返回 fd 而不是其他的选择?
- 如果返回一个指针 用户态就可以访问内核态的结构 并且可以通过偏移量访问其他未检查的文件 十分不安全
- fd 将会完全控制用户打开文件的过程和权限由内核控制
- Flie Cursor:记录这个 fd 当前读到的位置 可以用 SEEK 来修改
- fd table 和 flie table
- file_table 是全局共享的 记录了所有打开的文件的 inode 信息 包括 inode number、file cursor、refcnt 等
- 每一个进程都有自己的 fd_table 记录了 fd 到 file_table 中文件 index 的映射 子进程会继承父进程的 fd_table 因此共享 cursor 位置
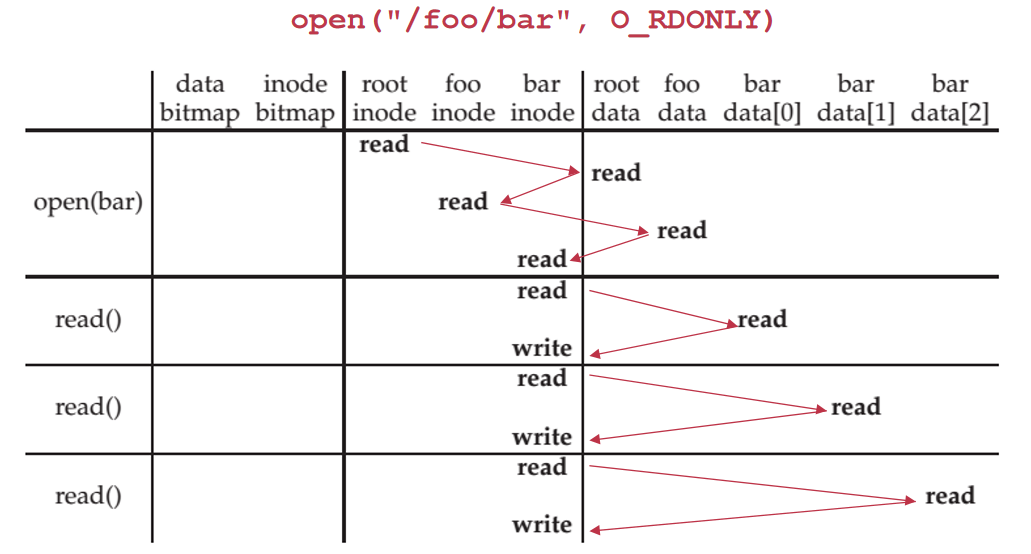
READ
- 根据 fd 找到 file_table 中的 inode 修改 inode 的 atime 读取 block data 到 buffer 里 最后修改 cursor
- 由于每次 read 都会导致对于 inode 的写(要修改 atime)linux 提供参数 no-atime 使得当最后关闭文件时才进行修改
- READ 的过程
WRITE
- 与 READ 类似 分配新的 block 并写入数据 修改 inode 的 mtime 和 size
- 写时顺序应该采用更新 block bitmap、写入新数据、更新 inode 虽然此种顺序在极端情况下会产生硬盘浪费 但是可以通过扫描磁盘来恢复 在写入数据前就更新 inode 会导致其指向一块已经被删除的数据 从而导致数据泄露
- WRITE 的过程
APPEND
- 与 WRITE 类似
CLOSE
- 释放 fd_table 中的 fd
- 减少 inode 的 refcnt
- 如果 refcnt 为 0,释放 file_table 中的条目
SYNC
- 为了保证缓存的数据落盘 必须提供这个用于同步的 API
删除一个打开的文件
- 在 linux 系统下 文件的 inode 将会在 refcnt 归零后进行删除 也就是延迟到关闭文件后删除
MALH
- 模块化
- 抽象化
- 分层化
- 层级化
LEC 5: Remote Procedure Call
分布式的数据存储 形如让几十台电脑的所有硬盘空间汇聚到一块 然后所有电脑通过远程连接的方式访问文件系统 这样就实现了高效的数据存储利用 这也是 RPC 的产生背景
An Example
本地调用函数会变成对于远端服务器上函数的调用
RPC Stub(客户端和服务端之间的代理对象)
- client stub
- 放入参数
- 发送请求
- 等待响应
- server stub
- 监听消息
- 获取参数
- 调用过程
- 将结果放入响应
- 发送响应
- 通过 stub 我们在不修改原来函数的情况下实现了远程调用
- 一次 RPC 调用:
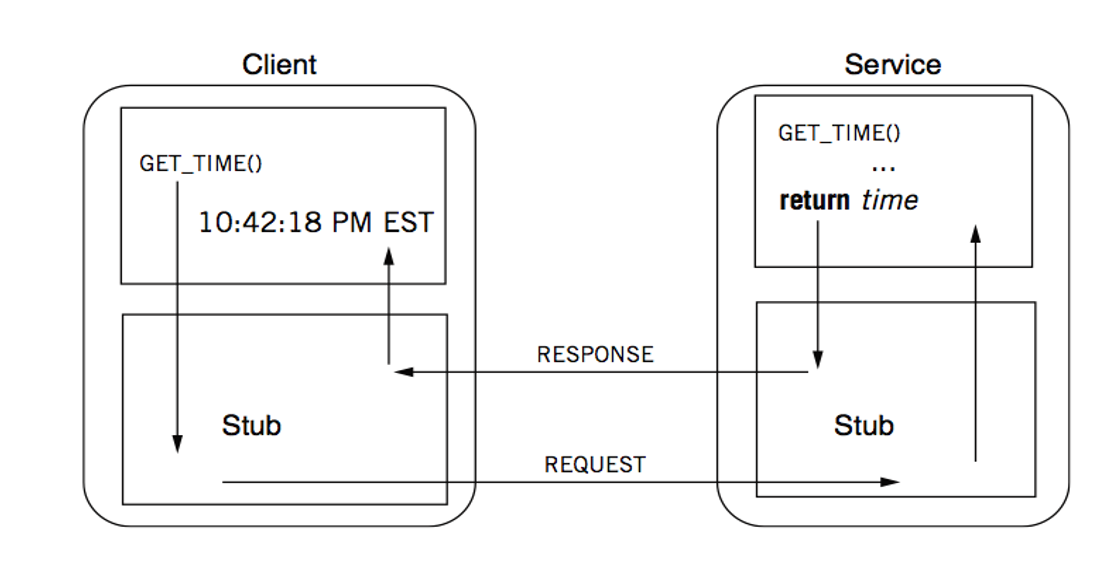
- client stub
客户端和服务器通过 message 来通信
A Message May Contain:
- 服务 ID
- 服务的参数
- 被序列化与反序列化
RPC request:
- Xid:事务 id
- call/reply
- rpc version
- program number:哪个二进制文件
- program version
- procedure number:哪个函数
- auth stuff:权限
- arguments
RPC reply
- Xid:事务 id
- call/reply
- accepted:是否接受请求 根据版本号、权限认证等
- auth stuff
- success:是否请求成功 根据文件号和过程号是否合法
- results
gRPC 会把一个服务绑定到一个端口来监听调用
How to Pass the Data?
Parameter passing
- client 把内存中的对象序列化为无指针的结构
- 发送数据
- server 反序列化为内存中的对象并建立指针
不同机器间的数据形式会有很多差别
- 大端小端
- 32 位 64 位
- 浮点数的格式
- 字符集 utf 或其他
- 对齐方式
标准化的编码
- textual:json、xml、csv 等 存在二义性 且不适用于二进制数据
- binary:更快更小 但是不可读 对于用户不友好 会通过 IDL 来定义结构 然后传输即可省去类似于 json 的字段名
传输协议
- TCP:可靠 但是慢
- UDP:快 但是不可靠
When RPC Meets Failure
semantics(语义)
- at most once:保证请求最多执行一次
- at least once:保证请求至少执行一次
- exactly once:保证请求只执行一次
- Birrell’s RPC semantics:服务器说 OK 则执行一次 服务器说 CRASH 则执行 0 或 1 次
idempotent
- 一个函数如果多次执行结果是一样的 就是幂等的
- RPC 系统会保证幂等性 使得错误处理可以用简单的 retry 来解决
LEC 6: Distributed Filesystem
- Distributed File Service Types
- Upload/Download:比如 FTP 通过上传下载文件来实现 浪费资源
- Remote Access:比如 NFS 通过远程访问文件来实现 用 RPC 接口
NFS with RPC
NFS 即 Network File System
NFS 将大部分的接口替换为了 RPC 接口 但是没有 OPEN 和 CLOSE 接口 READ 和 WRITE 接口则多了一个 offset 参数 MKDIR 返回的多了 fh(file handle)参数
NFS Protocols:
- Mount:客户端通过 mount 命令将远程文件系统挂载到本地 形如
mount 192.168.1.1:/home /mnt - Read a file:应用调用 OPEN(“f”,O) NFS 会调用 LOOKUP(dirfh,”f”) 把结果填到 fd 中返回给应用 应用调用 READ(fd,buf,n) NFS 会调用 READ(fh,offset,n) 返回结果给应用 最后应用调用 CLOSE(fd)
- Mount:客户端通过 mount 命令将远程文件系统挂载到本地 形如
为什么 NFS 不提供 OPEN 和 CLOSE 接口?
- 因为 OPEN 是有状态的 会创建类似于文件描述符的数据 而 LOOKUP 是无状态的 有状态会导致服务器重启后客户端的状态丢失 我们希望把状态保存在客户端 这也是为什么 READ 和 WRITE 多了一个 offset 参数 本质上就是把状态保存在客户端的 offset 中
什么是 fh(file handler)?
- 本质上就是一个 remote file 的标识符 包含三部分 file system ID、inode number、generation number
- 不能使用 fd 因为 fd 是有状态的
- 不能使用文件路径名 可能出现这种情况:客户端 1 打开文件 客户端 2 进行重命名 产生了不一致
- 不能使用 inode number 可能出现这种情况:客户端 1 打开文件 客户端 2 删除文件后创建文件 分配的 inode number 一样 客户端 1 就会访问到错误的文件 原本在单机文件系统中由于文件打开 inode number 不会释放后分配给新文件 这种情况就不会发生
- 因此 NFS 在 inode number 的基础上加了一个 generation number 相当于版本号 保证了文件的唯一性 以此作为 fh
READ 和 WRITE 为什么要用 offset?
- 为了实现幂等性
- 为了保证无状态的服务端 把状态保存在客户端
Performance Overheads
- 通常比本地文件系统慢 但不是绝对 和服务器性能与网络速度有关
- 优化
- 缓存到客户端 减少远程操作 或者服务端缓存到内存里
- vnode 是 NFS client 为每一个打开的文件维护的缓存数据 可以映射到服务端的 fh 减少 RPC 调用和 lookup 操作
- cache coherence
- close-to-open consistency:打开时比较 mtime 和缓存中的 mtime 关闭时把缓存中的数据写回
- read/write consistency:也许会读到旧数据 但是过一段时间会一致
- Transefer size:一次传输的数据量更大
- Read-ahead:预读取 读取一个文件时预读取后面的文件
Drawbacks
- Capacity:只能在单个服务器上放硬盘 无法扩展
- Reliability:服务器宕机后 NFS 无法使用
- Performance:单个服务器的带宽有上限
如何把单机文件系统变成分布式文件系统?
- Step 1:block layer
- 把 block_id 改为(block_id,mac_id)的形式
- 如何找到空闲的 block?用一个 master server 记录哪些 block 是空闲的 可以存在内存里
- Step 2:file layer
- 几乎不用改 因为 block layer 已经解决了大部分问题
- Step 3:inode number layer
- 同理 用 master server 存储 inode table
- 后续层几乎不用改
- 可以看到我们使用一个 master server 几乎解决了所有问题 但是这样会导致单点故障 性能瓶颈等问题
- 使用主从复制 可以解决单点故障问题和读性能的提升
Case Study:GFS(Google File System)
Assumptions
- 文件很巨大 并且 failures 是常态
- 写操作大多是 append 操作 而不是覆写 random write 很少见
- 工作量中大多数是读操作 而且是顺序读
GFS Design Goals
- scalable
- large data-intensive applications:数据密集型应用
- fault-tolerant
- high performance
GFS Interface
- 包含 create、delete、open、close、read、write 基本操作
- 多了 snapshot、append 操作
- 不支持 link、symlink、rename 操作 因为会导致一致性问题 在当时没有成熟的分布式事务解决方案
GFS Architecture
- GFS 采用了 master/slave 架构 一个集群包含一个 master 多个 chunk server master 存储分布式元数据 chunk server 存储分布式的 chunk 每个 chunk 还会被复制到多个 nodes 上
- 进行 replication 解决了容量 备灾和性能问题
- Why Large Chunks(64MB)?
- 减少 master 查询 chunk location info 的次数
- 减少 TCP 连接的数量
- 可以把元数据放在 master 的内存里 因为元数据变小了
- Reading a file
- 和 master 通信
- 获取元数据
- 获取 chunk 的位置 一个 chunk 会被复制到多个 chunk server 上
- 和 chunk server 通信 只需要和任一可行的 chunk server 通信即可
- Writing a file
- 对于并发写 GFS 保证最终 chunk 的一致性 但是不保证读数据一定是最新的
- GFS 会确定一个 primary chunk server 来确定每个写的顺序
- 2-phases write
- client 获得 repicas 的列表 确定好 primary 然后 chunkserver 以链式转发的方式进行传输 比如 1 收到数据后传给 2 2 收到数据后传给 3 这些数据会被缓存起来
- client 等待确认收到数据 然后发送一个 write request 给 primary primary 决定好写操作的顺序后再写入 一旦所有写入都确定成功 primary 会返回成功信息给 client
- 这是一种数据流和控制流分离的设计 一阶段是数据流 二阶段是控制流
- 好处是:

- GFS 的 naming 是单纯的 flat naming 没有目录结构
LEC 7: Key-Value Store
键值系统
为什么不用文件系统?
- 对于小数据 文件系统的开销太大 比如一次 GET 需要 OPEN+READ 另外文件系统的最小单位是 block 对于小于 block size 的数据会浪费空间
- 为了解决上面两个问题 可以把多个键值对放在一个文件里 形成简单的键值存储系统
一个基于文件系统 API 的键值存储系统
- 键作为字符串存储 值作为 json 格式字符串存储 键和值用逗号分隔 每个键值对用换行符分隔
- UPDATE 操作选择 APPEND 而不是修改
- 覆写需要磁盘进行随机访问 速度很慢
- 磁盘的顺序写很快 比随机访问快一个数量级
- INSERT 同理也是在文件末尾追加 查询时从后往前查询
- DELETE 同理 用一个标记位来标记删除 比如 null
上述的设计叫做 Log-Structured 即日志结构化 特征是 append-only
GET 操作需要从后往前查询 直到找到对应的键值对 线性复杂度 非常慢
使用 INDEX 来加速查询 记录 key 到文件 offset 的映射 可以使用 B+树或者哈希表 查询速度可以达到 O(logn)或 O(1)
但是前提是 INDEX 要放在内存里 通常 INDEX 本身就会非常大 必须把 INDEX 放在磁盘里
使用 Cuckoo Hashing 减少冲突 保证 O(1) 的查询时间 UPDATE 也是 O(1)的 但是 INSERT 需要驱逐 会涉及很多 IO 而且 rehash 需要把所有数据重新插入
无限制的增长会导致空间不够 使用 compaction 来合并相同键的值 回收过期的键值对
范围搜索:使用 B+ 树索引
- B+树的叶子是相连的 因此可以找到下限节点后顺序读
- B+树的 INSERT 和 UPDATE 是比较繁琐的 因此还是不宜使用
LSM 树(Log-Structured Merge Tree)
SSTable:Sorted String Table
- 在 SST 中搜索一个 key 是很高效的 因为 SST 是有序的
- 支持范围搜索
- 合并 SSTable 是很高效的 使用归并排序即可
MemTable:内存中的表
- 溢出后全部写入 SSTable
Drawbacks
- 查找旧值很慢 需要查找多个 SSTable
- compact 很慢
- 范围搜索仍然不快
解决方案:确保 SSTable 之间的 key 没有重叠 这样可以快速判断 key 是否存在这个 SSTable 中(判断 maxmin)
Crash Recovery:维护 memtable 的 WAL(Write-Ahead Log)
Write Stall:当写入一个值时 触发很多次 compaction 导致延迟变高
Write Amplification:写放大 实际对于磁盘的写入量远远大于数据量
查找不存在的 key 很慢 因为要查找所有 SSTable 可以通过 Bloom Filter 来加速
LEC 8: Distributed Storage: Sequential Consistency
How to deploy a KVS?
- 以微信为例 数据会部署在服务器和客户端上 就和我暑假做的日程 APP 一样 最大的重点是写时的数据同步 即读写都是本地的 而写会在后台进行与服务端的同步
Consistency Model
一致性模型是指一个存储系统在并发操作下如何处理同步和一致的约定
Strong Consistency
- 所有数据只有一个版本
- 读写等价于串行化的读写(线程之间的顺序可以不一样)
- 读写可以被视为一个从未 failed 的系统
- 根据等价于哪种串行化 分为:
- Strict Consistency:串行化顺序符合发生时间顺序 没有人实现这种模型 因为会有网络延迟的区别 机器的时钟不同步等问题
- Linearizability:如果 B 在 A 结束之后开始 串行化顺序中 B 一定在 A 之后
- Sequential Consistency:对于各个线程内的操作 保证串行化顺序和发生时间顺序一致 对于不同线程则不保证
Release Consistency
Eventual Consistency:所有服务器的数据最终会达到一致
如何实现 Linearizability?
- local property:如果一个数据的所有操作是线性化的 多个数据的操作组合也是线性化的
The simplest approach:centralized KVS
- 对于一个 server 客户端只需要把读写请求发送给这个 server 即可 记住在收到确认之前不能视为完成操作
- 假设接下来每个客户端需要有自己的 replica 我们采用 Primary-Backup model
- 对于每一个数据项 有一个指定的客户端作为 primary
- 对于写 primary 先转发给所有 replicas 全部写入后返回 最终在 primary 本地写入
- 为了防止 replicas 收到请求的顺序不一样 primary 会使用一个全局 counter 来为每一个 write request 加上 seq number replic 在收到前一个写之前不会执行后一个写
- 对于读 返回 primary 的数据 而不能读 replica 本地的数据 否则会产生在本地写入但是在 primary 未写入之前读取数据不一致的情况
- Drawbacks
- 读写需要额外的 RTT
- 一个 primary 会成为性能瓶颈和单点故障
- 这个模型的 backup 主要是为了容错 而不是提高性能 因此读写还是单节点的
- partitioning:把不同数据分区到不同的 primary 上 来解决只有一个 primary 导致的性能瓶颈问题
Drawbacks of linearizability
- 太慢 每一个操作都需要等待确认
- 单个 primary 会成为性能瓶颈和单点故障
- 难以提供 fault tolerance 因为 primary 一旦挂了就无法提供服务
LEC 9: Distributed Storage: Eventual Consistency
- Eventual Consistency:如果没有新的写入操作 那么所有服务器的数据最终会达到一致
- 实现 eventual consistency 是为了更高的性能
- READ:读取本地的最新数据
- WRITE:写入本地的数据 在后台异步地把写数据同步到其他服务器
如何实现 Eventual Consistency?
Write-write conflict
write-write conflict:两个不同的客户端同时写入同一个数据
linearizability 是悲观的解决方案 所有写入都会先在 primary 上确定顺序 于是先到的先写入
eventual consistency 是乐观的解决方案 先写入 之后再解决顺序问题 也正因此 读可能会读取到不一致的数据 但是最终会一致
不能再使用 update 操作 这有可能导致最终不符合语义 需要 append 操作 使用 update function 可以定义任意的数据库操作
通过 Ordered Update Log 来统一不同设备间的操作顺序 每个设备会把操作记录在自己的 log 里 同步时确保两台设备的 log 中顺序一致
同步时用什么确定 order?可以使用时间戳 如果时间戳一致则使用设备 ID
上述实现会在同步后才进行数据库的写入 然而为了用户体验 需要在本地数据库立马执行写入操作 然而如果这样做 当同步时 两个设备的初始状态是不同的 可以使用 Rollback and Replay 来解决这个问题
- 在 SYNC 前 设备把所有修改进行回滚 回到了初始状态 然后根据同步的 log 执行所有的操作 最终两台设备就会达到一致状态
- 时间一久 log 中的操作会非常多 导致回滚和重放的时间过长
- 解决方法是 checkpoint 即把 stable 的数据写入磁盘 然后截断 log 下面详细解释一下 checkpoint 的原理(使用的是 lamport clock):
- 设备 A 和设备 B 上一次同步时 如果同步得到的时间戳是 T 那么在同步之后发生的事件的时间戳一定大于 T 反之 小于等于 T 的事件一定在同步之前发生 也即一定被设备 B 所同步了
- 同理 对于设备 k 上一次同步的时间戳是 Tk 那么 Tk 之前的所有事件一定被 k 同步了
- 在设备 A 中维护一个 map 记录时间戳 Tk 时间戳小于 Tk 中最小值的事件 一定被其他所有设备同步了 也即 stable 的数据 可以写入磁盘
- 每一次和其他设备同步后 更新 Tk 集合 顺带更新了最小的 Tk 也就顺便把 stable 的数据落盘
- 问题:如果有一个设备一直离线 Tk 的最小值将永远不变
- 以下内容根本没听懂:
- 为了解决这个问题 引入 primary
- primary 会为每一个写分配 CSN(Commit Sequence Number) 分配到 CSN 的写都是 stable 的
- 不过会出现 reorder 现象

synchoronized clock time
为了用户体验 除了状态一致以外 还需要保证一些其他语义
Causal Ordering:在一台机器上 A 发生早于 B 或者是 A 触发了 B 的操作(比如 A 是添加数据 B 是删除数据)则 A 和 B 有因果关系
Lamport Clock:保证如果 A 是 B 的因 则 A 的时间戳小于 B 的时间戳 如果两个事件无因果关系(我们称其为并发事件) 则时间戳可能相等或无序
- 算法:
- 每个服务器保留一个时钟 T
- 随着时间的推移 T 会增加
- 收到一条消息的时间戳为 T’ 则更新 T 为 max(T,T’+1) 也即保证时间戳大于已经发生的事件
- 问题
- 时间戳可能相等 可以通过设备 ID 来解决
- 事件 A 发生在事件 B 之前 => A 的时间戳小于 B 的时间戳 但是反之不一定成立 因为每个设备的时间戳是独立的 换言之 没有办法确定 A 和 B 是因果关系还是并发事件
- 算法:
Vector Clock:用一个 n 维向量来表示时间戳 每个维度代表一个设备的时间戳 T[i]严格大于(即每个维度都大于)T[j] 则 i 发生在 j 之后 若无法比较 则是并发事件
算法:
- 若有 n 个设备 则每个设备有一个 n 维的向量代表时间戳
- 每个设备的时间戳初始时一样
- 设备 i 上 随着时间的推移 T[i] 自增
- 设备 i 向设备 j 发送消息时 把自己的时间戳 W 发送给对方 设备 j 把第 k 位时钟 更新为 max(V[k],W[k] + 1)
Summary
- scalability:仍有 primary 但是操作更轻量了
- 编程比较复杂
- fault tolerance:只要有一个设备存活就可以工作
LEC 10: Distributed Storage: All-or-nothing Atomicity
前面讲了两个一致性模型 是说系统如何处理并发操作来保证数据的一致性 然而面对各种 faults 这些模型将无法再保证数据的一致性 这就需要保证 atomicity 从而确保 faults 发生时数据不会出现不一致
Consistency under single-machine faults
- 任何调用都应该是 all-or-nothing 的 即要么全部成功 要么全部失败 否则会很难处理错误
- 以 bank transfer 为例 数据的一致性即保持账户总额不变
Achieving atomicity
Shadow Copy:保证对于一个文件的修改是原子的 通过写入一个新文件 然后重命名的方式来实现 因为重命名是原子的 虽然不会导致数据不一致 但是文件系统有可能会不一致
- Drawbacks
- 不支持并发 多个线程会同时写入一个原文件 导致覆盖
- 难以操作多文件 需要把所有文件放到一个目录下
- 拷贝开销大 即使只修改了一个字节也要拷贝整个文件
- Drawbacks
Journaling:上面的问题可以在 rename 之前写入 WAL 来解决 journaling 会导致极大的额外空间开销 所以可以只对 metadata 进行
- 通常磁盘会有一个电容 保证有足够的电力完成一个 sector 的写入
- 如果 journal 大于 sector size 怎么办?我们需要更通用的方法
Logging:可以见 AEA 事务笔记
REDO LOG
- logging 和 journaling 基本一致 不过 journaling 针对的是文件系统的细粒度操作 比如 rename
- 引入 transaction 的概念 一组原子性操作被称为事务
- 在准备操作前 写入 log 如何确保 log entry 是完整的?可以做一个 checksum
- redo-only logging’s pros & cons
- commit 很快速 只需要 append 操作到 log 中
- IO 利用率低 因为必须在事务提交时全部写入 log 如果在事务进行时就异步的写入 log 性能会更好
- 所有操作在提交之前需要缓存在内存中 万一内存不足就失败了
- log 无限增长 但是操作其实已经落盘了
UNDO LOG
- 为了解决 IO 和内存的问题 考虑在每一个操作后直接落盘 如果失败了需要全部回滚 因此引入了 undo log
UNDO-REDO
- undo 需要记录旧值 redo 需要记录新值 两者结合 每一个操作都记录新值和旧值 即可实现 undo-redo logging
- undo-redo 会记录每一个操作的 record 当系统调度不同事务时 可能不同的事务的 record 会交叉 因此需要一个指针来指向同事务的下一个 record
- record 的结构
- XID:事务 ID
- OID:操作 ID
- PTR:指向下一个 record
- VALUE:包括文件名、偏移量、旧值、新值
Put it together
- logging
- 每次操作前写入日志(WAL)
- 在 commit point 写入一个 commit record 到日志中
- recovery
- 从 end 遍历到 start
- 找到所有没有 commit 的事务 并添加 abort record
- undo 所有 abort 的事务 从后往前
- redo 所有 commit 的事务 从前往后
- logging
Problem:日志会无限增长 使用 checkpoint 来解决
- 等到没有任何操作在进行(而不是等到所有事务结束)
- 把 CKPT record 写入日志 CKPT 包括了所有当前正在进行的事务的 undo 和 redo 日志
- 把所有内存中的数据落盘
- 丢弃除了 CKPT 之外所有的日志
如何恢复?
- 如果 crash 时事务尚未提交 则应该保证事务回滚
- 如果事务在上一次 CKPT 后开始 则仅需 undo log
- 如果事务在上一次 CKPT 前开始 则需要 undo log 和 CKPT
- 如果 crash 时事务已经提交 则应该保证事务提交
- 如果事务在上一次 CKPT 前提交 不需要做任何事 因为 CKPT 内不会包含这个事务
- 如果事务在上一次 CKPT 后提交 且在 CKPT 后才开始 则需要 redo log
- 如果事务在上一次 CKPT 后提交 且在 CKPT 前就开始 则需要 redo log 和 CKPT
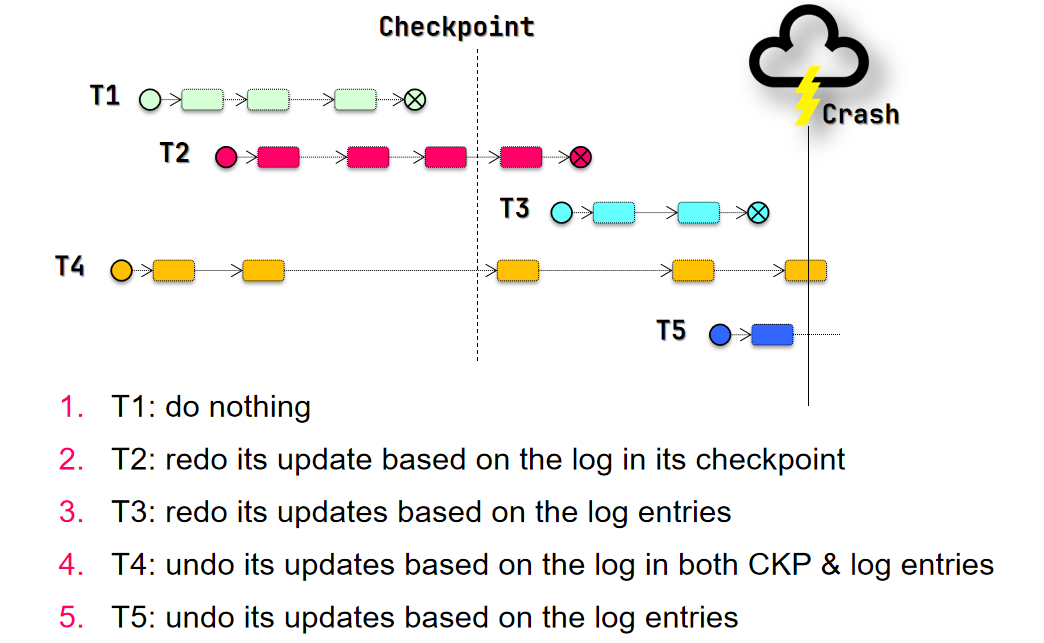
- 如果 crash 时事务尚未提交 则应该保证事务回滚
Undo-Redo vs Redo-Only vs Undo-Only
- REDO
- 更少的 IO 因为只需一半
- 更快的恢复 因为只需要从头到尾扫一遍
- 没有 UNDO 因此未提交的事务不得落盘 要求内存比较大 也就不适合事务太大 内存不够的情况
- UNDO
- 恢复快 和 REDO 一样
- 没有 REDO 因此提交的事务必须立马落盘 但是一个 page 可能包含多个事务的修改 这样就会重复落盘 很浪费性能;还有一种方法是每个操作都立马落盘 这样显然性能很差
- 由于上述原因 UNDO-ONLY 几乎不会用到
- UNDO-REDO
- IO 更多 是 REDO 的两倍
- 每条操作完了立马可以写入日志 IO 利用率比 REDO 高
- 恢复慢 要扫三遍
- REDO
Summary
- 保证原子性的方法
- shadow copy
- journaling
- logging
- Logging 同时也保证了 Durability 即一旦写入就不会丢失(因为可以 redo)
LEC 11: Distributed Storage: Before-or-after Atomicity & 2PL
- race condition:多个线程同时访问一个数据 由于操作包含多个步骤 会导致数据竞争
- before-or-after atomicity:也叫 isolation 保证一组读写操作是原子的 不允许其他线程看到中间状态
- 严格定义是 并发操作从自己的视角来看 其他的操作要么已经做完 要么还没开始
- 一组操作如何定义?用 Transaction 来定义 begin 和 end 会标记一组操作的原子性
Use Locks to achieve Isolation
- global lock:可以严格保证原子性 但是会导致性能瓶颈 粒度太粗
- fine-grained lock:对于每一个数据项加锁来减小粒度
- 如果一个事务涉及多个数据项的操作 细粒度锁并不能保证整个事务的 Isolation
- 解决方法:事务开始时按固定顺序获取所有数据项的锁 事务结束时再按相反的顺序释放所有锁
- 一旦数据量太大 内存中将放不下所有锁 对此可以预先设置最大数量的锁 数据项会哈希映射到锁上 只需确保同样的数据项会映射到同一个锁上即可
- 2PL(Two-Phase Locking)
- 在需要操作数据之前再获取锁
- 所有释放延迟到事务结束时 而不是在每个数据操作后立即释放
- 好处是推迟了锁的获取 减少了总占用时间
- 2PL 通过 serializability 保证了 before-or-after atomicity before-or-after atomicity 通常也被称为 serializability
Serializability
- Serializability:一系列事务的操作等价于它们串行执行的结果
- Final State Serializability:最终状态等价于串行化的结果
- Conflict Serializability:最常用的
- View Serializability
- Confilct ∈ View ∈ Final State
Confilct Serializability
2 opreations confilct if:
- 操作了同一个数据
- 至少有一个是写操作
- 它们属于不同的事务
定义:如果每个 conflict 的两个操作发生的顺序 和某一个串行化的都一致 则是 conflict serializable 的
Confilct Graph
- 每个节点是一个事务 边有向
- 如果 T1 和 T2 有冲突 且冲突的第一步是 T1 的操作 则有一条边从 T1 指向 T2
- 调度是 conflit serializable 的 <=> 其 conflict graph 是无环的 且节点的拓扑顺序就是其等价的串行化调度顺序
- Conflict Equivalence:如果两个 schedule 的 conflicts order 是相同的 则是 conflict equivalent 的
View Serializability
Informal Definition:如果一个 schedule 的最终状态与过程中间的读取结果可以等价于某一个串行化调度 则是 view serializable 的
Formal Definition
- 2 schedules S1 and S2 are view equivalent if:
- Ti 在 S1 中读取了 X 的初始值 且在 S2 中也读取了 X 的初始值
- Ti 在 S1 中读取了 Tj 的写入值 且在 S2 中也读取了 Tj 的写入值
- Ti 在 S1 中写入了 X 的最终值 且在 S2 中也写入了 X 的最终值
- 如果一个顺序和某一个串行化顺序是 view equivalent 的 则它是 view serializable 的
- 2 schedules S1 and S2 are view equivalent if:
View Serializability 的验证太复杂 因此很少使用 仅做理论研究
Conflict vs View
- Conflict Serializability 更容易验证 View Serializability 是近似 NP-hard 的
- Conflict Serializability 更容易实现 使用并发控制机制即可 比如 2PL
- Conflict Serializability 比 View Serializability 更严格
Proof of 2PL
2PL 保证了 conflict serializability 下面是证明:
- 假设不是 conflict serializable 则存在一个 cycle T1 -> T2 -> … -> Tk -> T1 设 Ti 和 Ti+1 间的冲突是对于变量 Xi 的
- 根据 2PL 的定义 Ti 在操作变量 X 之前会获取锁 也就是说 T1 要获取 X1 的锁 T2 要获取 X1 和 X2 的锁 … Tk 要获取 Xk-1 和 Xk 的锁 T1 要获取 Xk 的锁
- Ti->Ti+1 意味着对于数据 Xi Ti 的操作在 Ti+1 之前 因此 Ti 先拿到 Xi 的锁 再释放 Xi 的锁 然后 Ti+1 再拿到 Xi 的锁 同时因为 2PL 的定义 Ti+1 释放 Xi+1 的锁必定在 Ti+1 拿到 Xi 的锁之后 因此顺序为 Ti 释放 Xi 的锁 -> Ti+1 获取 Xi 的锁 -> Ti+1 释放 Xi+1 的锁 递推即可得到 T1 释放 X1 的锁在 Tk 释放 Xk 的锁之前 也就在 T1 获取 Xk 的锁之前 产生了矛盾
然而幻读现象是 2PL 情况下不满足 conflict serializability 的特例
一个典型的例子是:T1 是对于所有满足大于 300 的数据进行+1 操作 并 print 这些数据 T2 是插入一个新的大于 300 的数据
T1 在执行前会获取所有大于 300 的数据的锁 然而 T2 新插入的数据的锁却无法获取 因此 T1 修改完毕后 T2 立马插入新的数据 T1 再 print 时 读取到了新插入的数据 然而如果线性化 新的数据要么+1 了并且被 print 要么没有被+1 并且不被 print 而现在的结果是没有被+1 但是被 print 了 显然不符合冲突串行化的定义
幻读现象告诉我们 冲突定义中的数据项有时指的是一个范围内的数据 而不是一个具体的数据项(比如满足大于 300 的所有数据)此时只对于一个数据项加锁是不够的 需要对于整个范围加锁
解决方法包括:
- Predicate Locking:禁止其他事务插入符合条件的数据
- Range locks in B-Tree index:给 B-Tree 的索引加锁
- 或者干脆忽略
总结: 如果锁能够正确处理冲突的顺序 2PL 可以保证 conflict serializability
Deadlock
2PL 是悲观锁 仍有可能发生死锁
Methods to prevent deadlock:
- 获取锁时按照一个固定的顺序获取
- 并不通用 许多事务并不能确定获取锁的顺序(比如从一个哈希表里获取数据)
- 根据 conflict graph 来检测死锁:
- 如果有环 则有死锁
- 终止其中一个事务来断开环
- 但是检测时需要串行 具有高开销
- 使用启发式算法来检测死锁 比如超时重试
- 可能会误判 或是活锁
- 获取锁时按照一个固定的顺序获取
LEC 12: Distributed Storage: Serializability, OCC & Transaction
OCC(Optimistic Concurrency Control)
大体思路是:执行事务时不拿锁 在提交前检查是否有冲突 如果有则终止或重试
OCC Execute a TX in 3 steps:
- Concurrent local processing(因为不拿锁 所以不能在原始数据上操作 而是在副本上操作)
- 初始化 read set 和 write set
- 遇到 READ:如果 read set 中已经有这个数据项 则返回 set 中的数据 否则从数据库中读取数据
- 遇到 WRITE:把数据写入 write set 如果 read set 中有这个数据项 则修改 read set 中的数据 (此处似乎有点问题 应该是如果整个事务需要读取这个数据项 则修改 read set 中的数据?)
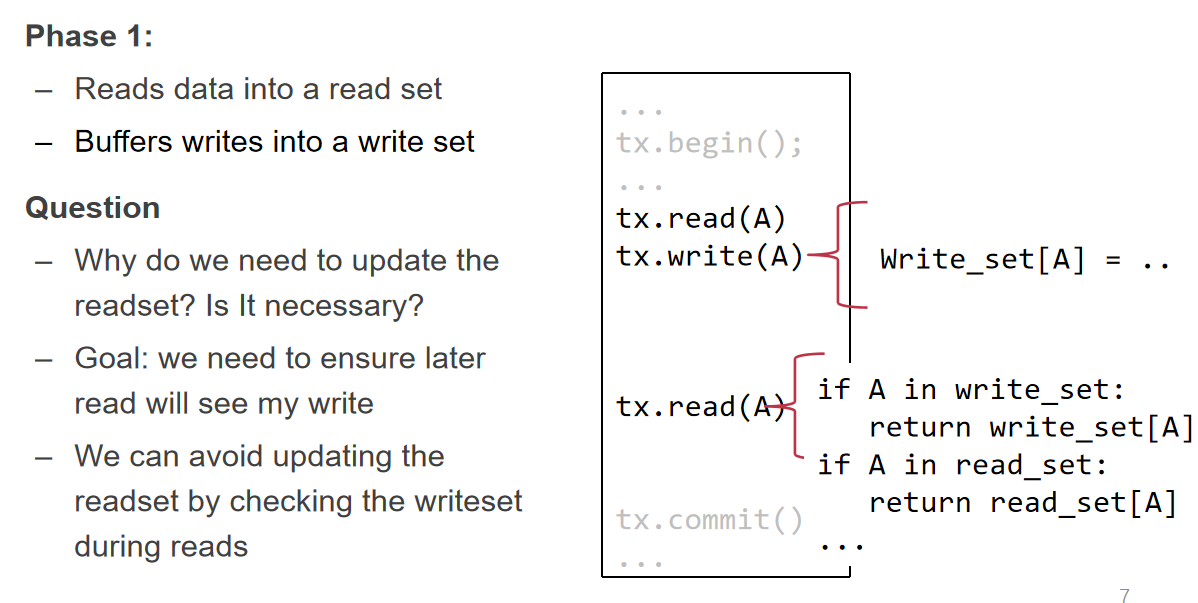
- Validation serializability in critical section
- 对于 read set 中的每一个数据项 检查是否和数据库中的数据一致 如果不一致则终止
- 为了防止 ABA 问题 可以记录每一个数据项的版本号 比较版本号即可

- Commit or abort in critical section
- 验证成功 则对于 write set 中的每一个数据项写入数据库

- 验证成功 则对于 write set 中的每一个数据项写入数据库
- Concurrent local processing(因为不拿锁 所以不能在原始数据上操作 而是在副本上操作)
Critical Section 指的是第 2、3 步也需要保证 before-or-after atomicity 确保验证到提交中间没有其他事务修改数据导致的 race condition
可以通过对第 2、3 阶段上一把全局锁来保证 由于锁的范围很小 因此性能不会受到太大影响
在分布式或高并发的场景下 还是需要上细粒度锁来提高性能 我们可以采用 2PL 验证 read set 之前获取锁 写入 write set 数据前获取锁 在提交或 abort 时释放所有锁
2PL 的死锁问题仍存在 不过现在我们必定知道哪些数据项会被访问 因此可以预先固定一个顺序来获取锁 即先把 read set 和 write set 中的数据项排序 然后按照这个顺序获取并释放锁即可
进一步思考 如果抛去 read set 数据的锁会如何?
- 如果 read set 数据被修改了 会导致验证失败 事务会被终止 肯定不会有问题
- 如果 read set 数据没有被修改 验证通过 有可能会在提交之前被修改 但是修改的数据项一定不在 write set 中 如果没有数据依赖 这个被修改的数据项一定可以等价于在提交之后发生 因此不会有问题
- 最后看看有数据依赖的特殊情境
- T1 执行 A+=B T2 执行 B+=A
- T1 读取 A 和 B T2 读取 A 和 B T1 获取 A 的锁 T1 通过验证 T2 获取 B 的锁 T2 通过验证 T1 写入 A T2 写入 B
- 此时 A 和 B 都被改为 A+B 显然不符合冲突串行化的定义
- 原因是虽然 T1 只写入 A 但是写入 A 的操作对于 B 有数据依赖 需要确保读取 B 和写入 A 之间不能被其他事务读取
- 解决方法也很简单 一个读取发生在其他事务的读取和写入之间 意味着读取后别的事务进行了写入 我们只需要检测这种情况即可 别的事务进行了写入之前一定会获取锁 因此在验证时 除了判断数据是否被修改 还需要判断锁是否被获取 也即数据是否正在被其他事务修改
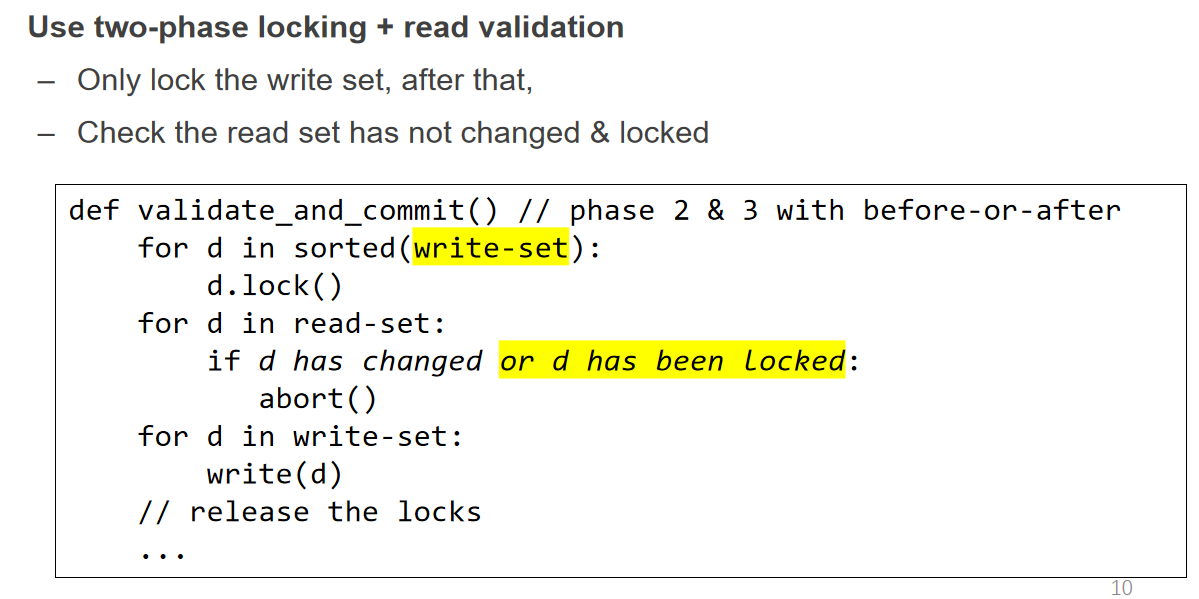
Advantages
- 阶段 1 在 local 进行 线程间没有竞争 不需要任何锁 性能很高
- 阶段 2 需要锁 但是范围很小 性能也不错
- 对于 read-heavy 的应用 OCC 的性能很好 因为 read set 不需要锁 而 2PL 则全部需要锁
Problems
- False Aborts:OCC 检查有时会把满足 conflict serializability 的事务终止 原因是 OCC 验证时如果读后发生写会终止 也就是说任一读写冲突 OCC 只允许写操作在前的顺序 对于 read-heavy 的事务 abort 的概率会更高 甚至在低竞争的情况下也会出现
- livelock:高竞争的场景下 OCC 会不断的 abort 尤其是对于读写操作很多的大事务 从而导致事务在执行 但是却无法提交 业界会采取检测 abort 次数过多的事务 并且把它们转为 2PL 来解决这个问题
Summary
- 并发事务少时 OCC 的性能很好
- 当并发事务数越多 OCC 的性能会越差 逐渐低于 2PL
HTM(Hardware Transactional Memory)
通过 CPU 硬件来保证事务的原子性
使用 xbegin 和 xend 指令来标记事务的开始和结束 代码如下:
1
2
3
4
5
6
7
8
9if (xbegin() == _XBEGIN_STARTED) {
if condition { //abort manually
xabort();
}
// transactional code
xend();
} else {
// fallback code
}RTM(Restricted Transactional Memory,which is Intel’s HTM)实际上是由 OCC 实现的 因此如果其他线程在事务中修改了数据 xbegin 会返回失败 也就进行 fallback 操作
Pros
- 简单的使用一行代码就可以把任意操作变成事务 并且性能比软件实现要好
Cons
- 正因为是用 OCC 实现的 所以无法保证成功
- 简单的 retry 并不能解决问题 因为很有可能是硬件限制导致事务失败 此时 retry 会一直失败 导致 livelock
- 在 retry 一定次数后 考虑转向拿锁 代码如下:
1
2
3
4
5
6
7
8
9
10if (xbegin() == _XBEGIN_STARTED) {
if lock.held() // 防止其他核正在进行fallback
xabort();
// transactional code
xend();
} else {
lock.acquire();
// fallback code
lock.release();
}
Implementation of RTM
- RTM 把 read/write set 数据存放在 CPU 的 cache 里 并且使用了 cache coherence 来检测冲突
- cache coherence 是指 CPU 的多个核之间如果出现 cache 上的 race condition 进行修改的核会把修改广播给其他核 从而保证数据的一致性
- 如果 set 数据大小超出了 CPU cache 的限制 RTM 会无条件 abort 事务
- 有趣的事实是 RTM 将 read set 放在 L2 和 L3 cache 里 write set 放在 L1 cache 里 这意味着写操作会更早的达到限制
- 事务的执行时间越长 RTM 的 abort 概率越高 因为 CPU 会定期切换上下文来进行调度 而上下文切换会污染 cache 因此 RTM 会无条件 abort 事务
- RTM 把 read/write set 数据存放在 CPU 的 cache 里 并且使用了 cache coherence 来检测冲突
对于小事务 HTM 的性能大于所有软件层面的 OCC 对于 TPC-C 这样的大事务 HTM 的性能会较低
LEC 13: Distributed Storage: OCC, MVCC & Multi-Site Atomicity
MVCC(Multi-Version Concurrency Control)
- 为了解决 OCC 的 false aborts 问题 我们需要确定每个数据是否属于同一个时间点 也就需要 COW 来实现多个版本的数据
- 版本号需要确定时间戳 最通用的方法是 FAA 的全局 counter FAA 有性能瓶颈 但是对于小项目足以
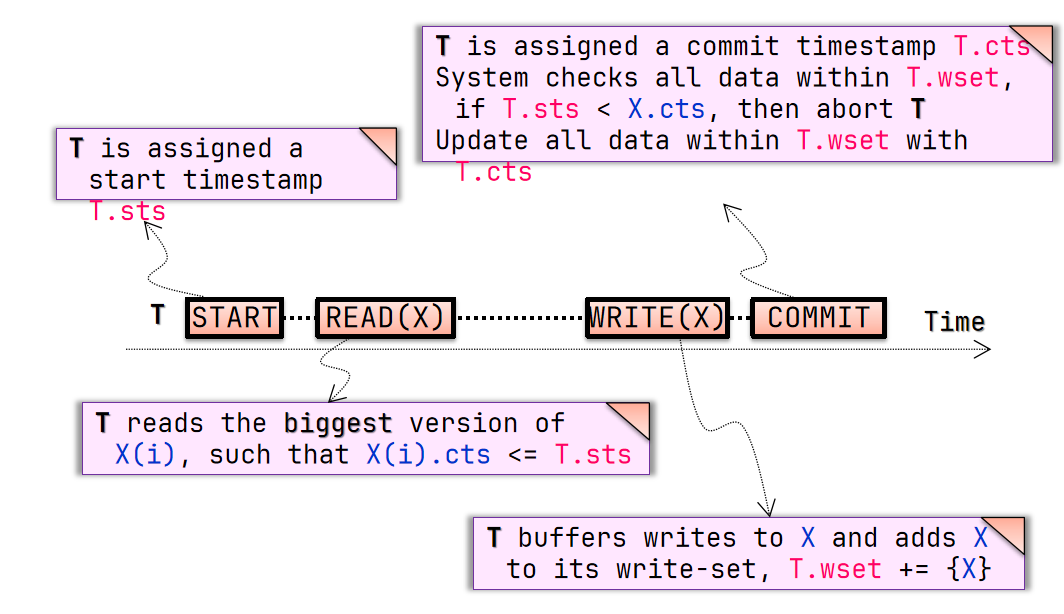
Optimize OCC with MVCC
- Try #1
- Concurrent local processing
- 获取开始时间戳
- 读取离开始时间戳最近的 snapshot
- 写入数据到缓存中的 write set 里
- Commit the results in critical section
- 获取提交时间戳
- 将 write set 写入数据库 同时带上提交时间戳
- Concurrent local processing
- Partial snapshot
- 事务 T1 读取 A 和 B 事务 T2 写入 A 和 B 可能会出现以下情况:
- T2 提交 获取时间戳为 1 写入 A T1 获取开始时间戳为 2 读取 A 和 B 此时读取 A 的版本号为 1 读取 B 的版本号为 0
- 也即事务写入时 有一段时间数据库里的版本是不完整的
- 为了保证写的 Isolation 在执行写入之前为每个数据项上锁 等到写完这个数据项后放锁 如果其他事务读取数据时有锁 则等待 这样就不会读取到 partial snapshot
- 事务 T1 读取 A 和 B 事务 T2 写入 A 和 B 可能会出现以下情况:
- 在写入数据库前 还需要检查 write set 中数据在数据库中的版本号是否大于开始时间戳 如果是则意味着有并发事务 终止事务
- 最终实现:
- garbage collection:定期清理旧版本数据 维护所有事务的最小开始时间戳 一旦这个时间戳大于版本号 数据就可以被删除
- Write skew anomaly
- 让我们看一个例子:
- T1 读取 A 写 B T2 读取 B 写 A
- T1 获取开始时间戳为 1 T2 获取开始时间戳为 2 T1 读取 A 的版本号为 0 T2 读取 B 的版本号为 0 T2 先提交 写入 A 的版本号为 3 T1 再提交 写入 B 的版本号为 4
- 我们会发现读取 A0 应该在写入 A3 之前 读取 B0 应该在写入 B4 之前 即 T1 和 T2 有冲突环
- 也即两个事务同时写入同一个数据 但是写入的数据是不同的 导致没有写写冲突 但是却不是 conflict serializable 的
- 最简单的 solution 是:对于读写事务 检查 read set 本质上也就是 OCC 但是对于只读事务 可以不检查
- 实际上如上没有 read set 检查的 MVCC 也叫 snapshot isolation 而 MVCC 还可以应用于 2PL 和 OCC 实现 MV-2PL 和 MV-OCC
- 让我们看一个例子:
Transaction
事务是对于管理数据的一组操作的抽象 具有 ACID 特性
- Atomicity:要么全部成功 要么全部失败
- Consistency:事务只会将数据从一个一致状态转换到另一个一致状态 然而这个状态是人为定义的 应用层面也会打破一致性 因此数据库无法保证 consistency
- Isolation:事务之间是隔离的 两个事务的并发一定可以串行化
- Durability:事务一旦提交 数据就会持久化
Summary
- A 与 D 用 log 来保证
- I 用 2PL、OCC、MVCC 来保证 同时还有 HTM 在硬件上实现 OCC 的思路
Multi-Site atomicity
- 当数据分布在多个 site 时 单机的原子性将不再适用 比如一个事务涉及到多个 site 的数据 在其中某一个 site 上发生了故障 则这个事务就无法保证原子性
- 如何保证分布式的原子性 即 Multi-Site Atomicity
2PC(Two-Phase Commit)
事务也应该是模块化的 一个大事务可以分解为多个小事务 小事务仍不失去原子性 在分布式架构下 可以把每一个 site 上的操作看作一个小事务 把统筹各个 site 小事务的操作看作一个大事务
2PC 大体思路
- Prepare Phase
- 将小事务的 commit 延迟
- 小事务要么 abort 要么 tentatively commit
- 大事务来评估小事务的结果
- Commit Phase
- 大事务决定小事务是否真正 commit:如果有至少一个小事务 abort 则大事务也 abort 否则 commit
- Prepare Phase
Logging in 2PC
- 分布式下 小事务执行到 commit point 时 只能保证自己的 Durability 无法保证其他事务的 因此无法真正提交
- 整个过程中只有 coordinator 是可以保证所有事务的 Durability 的 因此只有 coordinator 可以决定 commit 与否
- 小事务(worker)
- REDO-UNDO:保持不变
- commit record 需要改为 prepared record
- 记录需要带有大事务的 reference
- 当 failure 时 向 coordinator 询问是否 commit
- 大事务(coordinator)
- 有一个 prepare log 记录大事务是 commit 还是 abort
Challenge:unreliaible communication、coordinator & worker
Problem:如果小事务的日志是完好的 但是大事务的日志还未写入 没法判断是否 commit
Solution
- 听从 coordinator 的决定 如果大事务没有 record coordinator 可以向各个 worker 查看是否 prepared 如果都 prepared 则 commit 否则 abort
- worker 不能自己决定 必须向 coordinator 询问 确定了 commit 后 就可以把 prepared record 改为 commit record
本质上就是 小事务一旦处于 prepared 状态(也就是原来的 commit 状态)就意味着小事务已经保证了 A 和 D(原子性和持久性) 一旦所有小事务都处于 prepared 状态 大事务就保证了 A 和 D 因此就可以 commit
coordinator 给小事务发送 commit 的目的并非让小事务保证 A 和 D 而是让小事务把 prepared 改为 commit 从而可以继续下一个事务
Summary
- coordinator 需要记录每个小事务的 prepare 状态吗?不是必须的 反而会带来额外的开销
- 记住 logging 的最小化才是性能的关键
- 还剩一个问题:如何做 CKPT?
- 小事务的 CKPT 仍然一致 只要 commit 了就可以清除
- 大事务的 CKPT 会遇到新问题:worker 仍有可能询问这个 commit 什么时候才可以真正清除呢?
- 也很简单 coordinator 在异步发送 commit 给 worker 后 后台会收到每一个 worker 的 ack 等到所有 ack 都收到后再清除这个 commit
2PL & OCC in 2PC
- 2PL:给小事务上锁就能保证 Isoaltion 只需要每一个小事务直到大事务决定 commit 后才释放锁即可
- OCC:prepare 阶段和 OCC 的 validation 相结合 coordinator 除了询问 worker 是否 prepared 还需要 validate 是否有冲突 如果有冲突则 abort 否则 commit
Summary
- 2PC 保证了 Multi-Site Atomicity
- 然而一旦 coordinator 挂了 系统的可用性将被破坏 下节课将讨论如何解决这个问题
LEC 14: Distributed Storage: Replication & Consensus (Paxos)
- 2PC 只保证了 Consistency 通过 Replication 可以保证 Availability 与 Partition Tolerance
- Replication 可以提高性能和延迟(比如前端) 也可以提高可用性
- Replication Consistency
- Optimistic Replication:允许数据不一致 但是最终会一致
- Pessemistic Replication:保证 strong consistency
Pessemistic Replication
- 悲观复制意味着更低的可用性和性能 但是所有操作都可以被视为在一个 single copy 上执行的 用户将感知不到多个 replica 的存在 这和乐观复制不同
RSM(Replicated State Machine)
- 所有 replica 都可以被视为一个状态机 只需要保证输入和顺序一致 那么输出也一定一致 真正的关键在于请求的顺序如何保持一致
- RSM 可以使用之前提到的 primary-backup 模型实现 我们知道 primary-backup 模型最大的问题在于 primary 的单点故障导致可用性被破坏 下面我们会看到如何使用 View Server 和 Coordinator 来解决这个问题
- Coordinator
- 所有客户端的请求发送给 coordinator
- coordinator 会把请求转发给 primary
- 出现 multiple coordinators 时 会出现问题 因此引入了 view server
- View Server
- 管理 primary 和 backup 的选举 记录谁是 primary 谁是 backup
- 每个 replica 向 view server 进行心跳 维护每个节点的健康状态 当 primary 挂掉时 view server 会选举一个 backup 作为新的 primary 并找到空闲的 replica 作为新的 backup
- 新的 primary 收到 vs 发送的任命状之前会拒绝所有 coordinator 的请求 此时旧的 primary 仍可以正常处理请求
- 新的 primary 收到任命状后会开始处理请求 旧的 primary 如果收到 coordinator 的请求 会因为无法向新的 primary(在它的视角仍是 backup)写入数据而拒绝请求
- switch-over 的 commit point 是新的 primary 收到 vs 的任命状时
- 当 coordinator 收到 client 请求时 向 view server 询问当前的 primary
- vs 只负责记录 primary、维护心跳与选举 因此负载很低 不构成性能瓶颈
- vs 也可能会挂掉 因此需要多个 vs 保证可用性 此时引入 Paxos 算法保证一致性
Paxos (Single-Decree)
- Paxos 是一个分布式一致性算法 用于选举一个值
- Paxos 有三个角色(每个节点都可以同时扮演这三个角色)
- Proposer:提议者 提出一个提案
- Acceptor:接受者 接受提案 超过半数的 acceptor 接受了提案 则提案被接受
- Learner:学习者 达成统一后 发送结果给 client
- Paxos 的目标是所有的 acceptor 统一一个单值
- General Approach
- 一个 propose 决定变为 leader
- leader 提出一个提案的值 并从所有的 acceptor 那里得到接受
- leader 宣布结果
- Political Science 101
- Poxos 有轮次(round) 每一个轮次有一个 ID 称为 N
- 轮次是异步的
- 如果在 j 轮次中听到 j+1 轮次的消息 终止一切并转移到 j+1 轮
- 使用超时机制
- 每一个轮次有很多阶段(phase)
Paxos Phases
- Phase 0
- client 发送一个请求给所有的 proposer

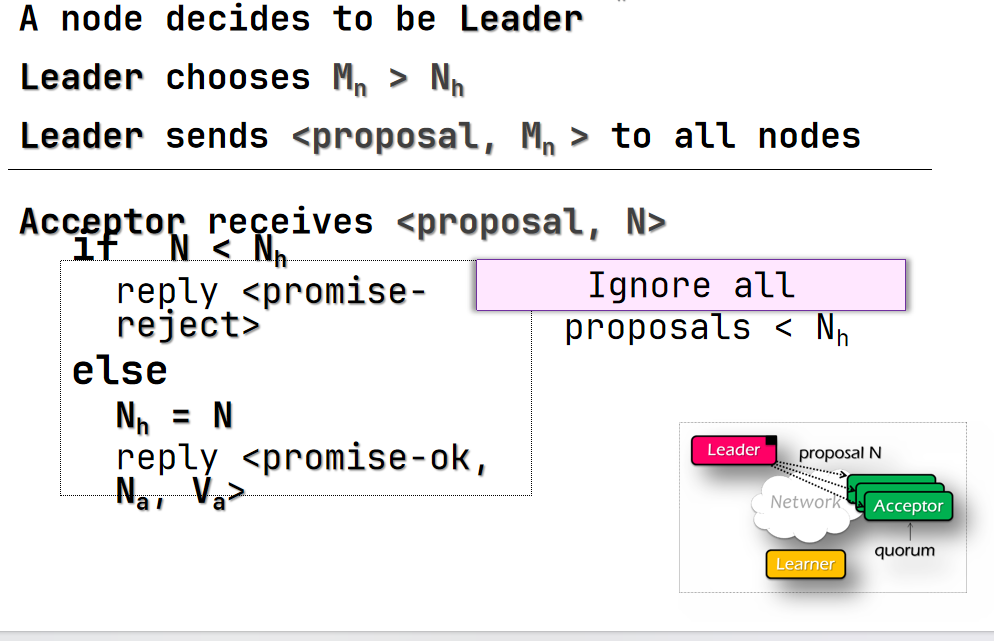
- Phase 1a(prepare)
- 一个节点决定成为 leader
- leader 创建一个 proposal N 发送给所有 acceptor 其中 N 必须比 leader 先前见过的所有轮次要大
- Phase 1b(prepare)
- acceptor 收到 proposal N 如果 N 大于等于它之前见过的所有 proposal
- 更新自己见过的最大轮次
- 回复 leader 之前accept过最大的 proposal
- 否则回复拒绝
- acceptor 收到 proposal N 如果 N 大于等于它之前见过的所有 proposal
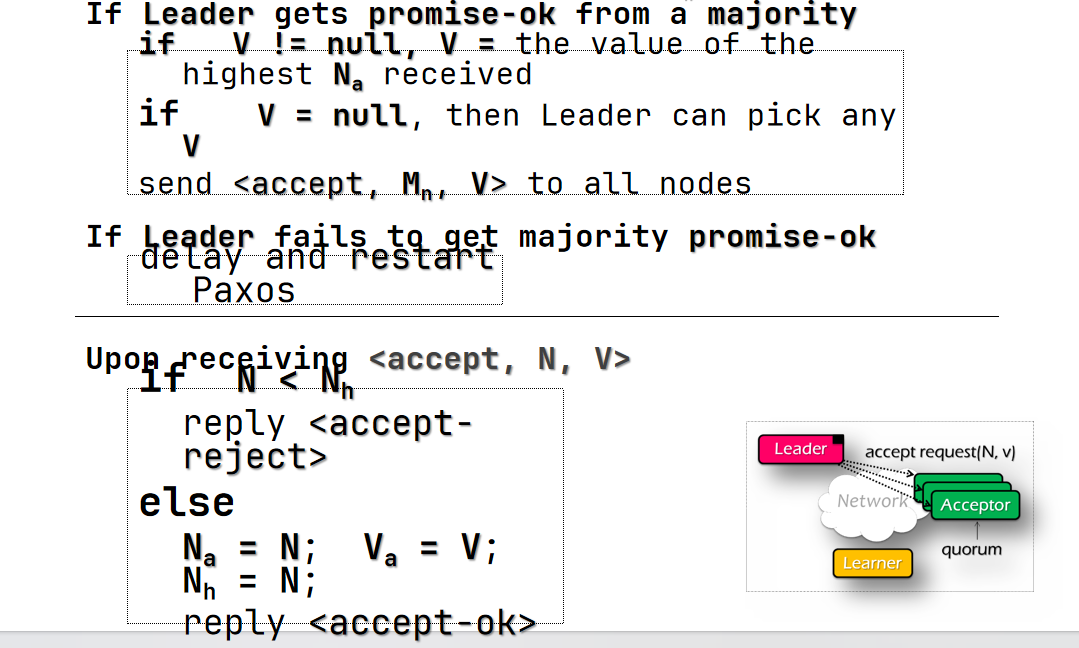
- Phase 2a(accept)
- leader 收到至少半数的 ok 后(而不是 reject)
- 设置 proposal 的初始值(任意) 如果有任何返回的 proposal 值 用其中最大轮次的替换
- 发送给所有节点一个 accept request 带上 proposal
- 如果没有至少半数的 ok 则稍作 delay 后重试
- leader 收到至少半数的 ok 后(而不是 reject)
- Phase 2b(accept)
- acceptor 收到 accept 请求
- 如果轮次 N 大于等于它之前见过的所有轮次
- 更新自己见过的最大轮次、接受的最大轮次的 proposal
- 发送 accepted message 给 proposer 和 learner
- 否则拒绝
- 如果轮次 N 大于等于它之前见过的所有轮次
- acceptor 收到 accept 请求
- Phase 3(learn?)
- leader 收到半数以上节点的 accepted message 把 decide message 发送给所有节点
- 否则稍作 delay 后重试
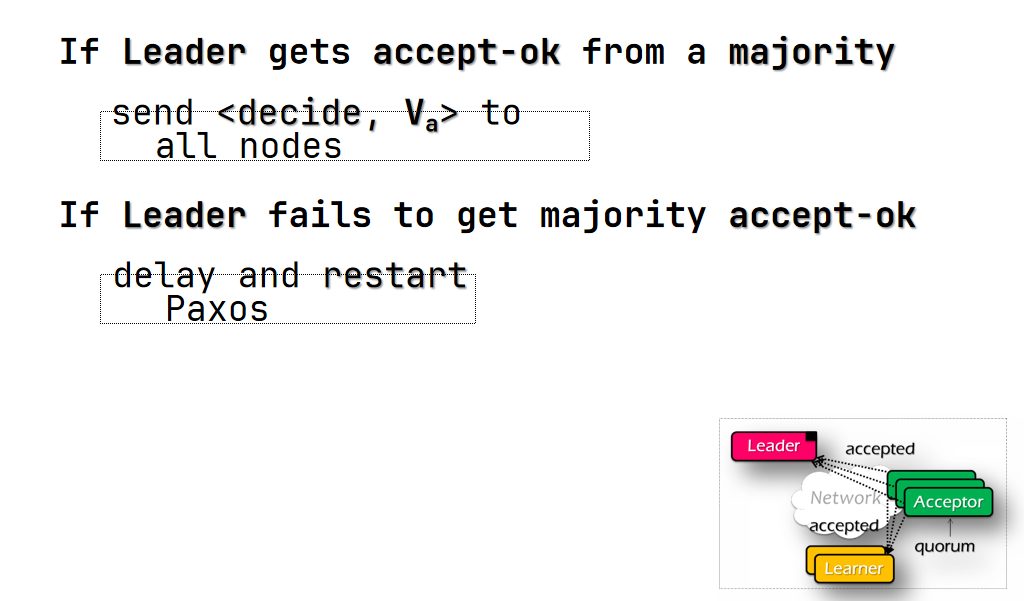
Inside of Paxos
- 为什么要多个 acceptor?
- 为了保证可用性 如果只有一个 acceptor 挂掉了 就会 halt
- 为什么不直接接受第一个 proposal?
- 有可能有多个 leader 同时提出了 proposal
- leader 可能在 decide 之前挂掉
- 为什么可以保证最终的一致?
- 不可能有两个 leader 可以同时看到半数以上的 accepted message
- 因此最终只有一个 leader 可以 decide
- 什么时候值真的被确认了?
- 当 leader 收到半数以上的 accepted message 时 此时半数以上的节点记录了这个 proposal 后续不可能无视掉这个 proposal
- 真正的时间点其实是在半数以上的节点收到了 accepted request 时 但是这个时间点对于系统来说是不可见的 因此选用后续的时间点
- acceptor 在发送 ok 后挂掉了怎么办?
- 需要在发送 ok 之前维护自己见过的最大轮次
- accpetor 在收到 accept request 后挂掉了怎么办?
- 需要立马维护自己见过的最大轮次和接受的最大轮次的 proposal
- leader 在发送 accept request 后挂掉了怎么办?
- 需要维护自己见过的最大轮次 并重新选举更大的轮次
- 上面三个状态都应该维护到 WAL 里 保证可以恢复
A extreme case for Paxos
假设现在有 10 个节点
节点 1 提出了一个 proposal <1, “hello”> 收到半数以上的 ok 后发送 accept request 发送完后立马挂掉
这个 accept request 只有节点 2 收到了
节点 3 提出了一个 proposal <2, “world”> 收到半数以上的 ok 后发送 accept request 不巧的是节点 3 和节点 2 间的网络断开了 因此节点 3 并不知道<1, “hello”> 这个 proposal 因此它可以发送 <2, “world”> 这个 proposal
以此类推 直到有半数的节点收到了 proposal 后 后续的 proposal 将必须从这 5 个 proposal 中选取
这个例子告诉我们 Paxos 不保证选举的成功 也不保证一定能选取出全局最新的 proposal 但是保证了最终一致性
Summary
- Paxos 在 RSM 中的应用:即每个 VS 是一个节点 需要选举出一个统一的 primary 和 backup 如果选举期间有节点挂掉 这个选举可能会一直进行下去 Paxos 不保证选举一定成功
- Single-Decree Paxos 只能产生一次决议 在 RSM 中 往往需要产生多个 View 因此需要 Multi-Paxos
Multi-Paxos
- Multi-Paxos 的实现非常简单 思路即一个 Paxos 负责一个决议
- 假设有 3 台 VS 我们只需要在每台 VS 上运行多个 Paxos 实例 每一个实例负责一个决议 就可以产生多个 View
- client 发送一个请求 选一个新的 Paxos 实例进行选举 如果发现最终决议不是自己的请求 则继续使用下一个 Paxos 实例进行选举
Problems
- Multi-Paxos 的性能很差 因为需要很多 RTT
- 最优情况下需要 2RTT
- 高并发场景下更糟糕
- 请求可能与其他服务器的数据有冲突 需要新建实例选举
- 可能同时有多个请求需要选举 导致多个轮次
- Solution
- 选取一个 leader 绝大部分时间都由这个 leader 来处理请求和 propose
- 这样还可以做到批处理请求 leader 可以一次性 prepare 之后的所有 proposal
- 注意这个 leader 不是必须的 用户发现 leader 挂掉后可以自己任选一个节点作为 leader 发送请求
- Hole in the log
- leader 在发送选举之前就挂掉 会导致本次决议为空
- 由于每个节点都有可能故障 Paxos 中的决议 sequence 是不连续的 会产生很多空洞
- Raft 会解决这个问题
Summary
- Multi-Paxos 基于 Single-Decree Paxos 产生一系列的决议 应用于 RSM 中
- Multi-Paxos 至今没有很好的实践 因为对于 programmer 来说不友好 需要应用自己解决很多问题
LEC 15:Distributed Storage: Replication & Consensus (Raft)
Raft
- Raft 是一个分布式一致性算法 用于保证 replicated log 的一致性
- Raft’s Approach
- Leader Election
- 选取一个 server 作为 leader
- 检测 leader 是否挂掉 选取新的 leader
- Log Replication
- leader 接受 client 的请求 添加到 log 中
- leader 发送 log 给其他 server
- Safety
- 保证 logs 的一致性
- 只有保持日志 up-to-date 的 server 才能成为 leader
- Leader Election
Election
- Server states(每个 replica 同时只能处于一个状态)
- Leader:接受 client 请求 添加到 log 中 发送 log 给其他 server
- Follower:接受 leader 的 log 当 leader 挂掉时成为 Candidate 不会向其他 server 发送消息
- Candidate:参与 leader 的选举 当发现 leader 时成为 Follower
- Term
- Raft 将时间划分为离散的 term 一个 term 会以 election 开始 当选出的 leader 挂掉时或是没有选出 leader 时结束并开始新的 term
- 每个 term 有一个唯一的 leader term 最高的 leader 说了算
- 一个 term 由几个阶段组成
- Election:选举 leader
- Normal Operation:成功选出 leader
- Split Vote:由于分票导致选举失败 开始新的 term
- Election Timeout:此任期的 leader 挂掉 开始新的 term
- Heartbeat & Timeout
- leader 每隔一段时间发送 heartbeat 给其他 server
- follower 收到 heartbeat 重置 timeout
- 如果心跳 timeout 了 则成为 candidate 开始选举
- 一般 timeout 在 100ms-500ms 之间
- Election Basics
- 状态转为 candidate
- 增加 term
- 投票给自己 并不断发送 RequestVote RPCs 给其他 server 直到
- 得到半数以上的票数->成为 leader
- 收到一个 leader 的 heartbeat->转为 follower
- 没有人赢->增加 term 重新选举
- 所有节点需要维护一个 votedFor 变量 代表每个任期都投票给了哪个节点 从而保证在同一个 term 只投一次票 也就保证了 majority 的唯一性
- 同时节点也需要维护一个 currentTerm 变量 代表自己见过的最大任期 保证自己不会把票投给 term 比自己小的节点
- Liveness
- 如果每个 server 的 timeout 是相同的 当 leader 挂掉后 所有 follower 会在同一时间成为 candidate 这就是 split vote 现象 会导致选举大概率失败
- 解决方法是随机化 timeout 确保大概率只有一个 server 成为 candidate
Log Replication
- Log structure
- 每个 log entry 代表<index, term, command>
- index 代表 log entry 在 log 中的位置 term 代表 log entry 是在哪个 term 产生的 command 代表 client 的请求
- Update Logs
- client 发送请求给 leader
- leader 添加到自己的 log 中
- leader 发送 AppendEntries RPCs 给 follower
- leader 收到 majority 的 ack 后提交 log entry 并发送 commit message 给 follower 同时在 rsm 上执行 command
- Consistency of Logs
- Raft 保证这样的性质:如果两个 server 上的 log entries 有相同的 index 和 term 那么这两个 entries 的内容一定相同 并且他们之前的所有 entries 也一定相同 这条性质也表明 一个 commited 的 entry 前面的所有 entry 一定也是 commited 的
- AppendEntries RPC 会包含 leader 当前日志的 checksum 如果 follower 发现日志不一致则拒绝 这样就保证了上述的性质
- leader 如果与 follower 不一致 会导致后续没法添加 log 因此 leader 被拒绝后 会找到不一致的部分 发送给 follower 进行覆写 最后添加新的 log entry 使得两者的日志完全一致
- 上述的性质导致了即使一条 cmd 已经得到 majority 的 ack 并且在 rsm 上被执行 但是仍有可能被覆写 这样的问题会在下面提到的 Safety 中解决
Safety
Leader Rule
- 如果让一台严重不一致的 server 成为 leader 就会导致上述的覆写问题 因此需要对 leader 的选举进行一定限制
- 因此必须选取 term 和 index 最新的 server 作为 leader(先 term 后 index) 即 follower 如果发现自己的 log 比 candidate 更新则不投票
- 这样的限制保证了 一旦当前任期的 leader 将一个 entry 写入 majority 的节点 那么这个 entry 一定会被保留在未来的 leader 中 不会被覆写 此时认为它是 commited 原因也很简单 未收到这个 entry 的节点不可能比 majority 的节点的 term 和 index 要大 因此不会成为 leader
Commit Rule
- 但是还存在一个可能使得存在于 majority 节点的 entry 被覆写的情况 就是这个 entry 是后续被覆写而达到 majority 的
- 加入 Commit Rule:Leader 判定满足以下条件的 entry 是 commited 的
- 这个 entry 在 majority 节点中
- 这个 entry 之后存在一个当前 term 的 entry 在 majority 节点中
- 原因很简单 由 Leader Rule 可知 如果当前任期的一个 entry 写入了 majority 节点 这个 entry 可以被认为是 commited 的 再由 Prefix 性质知道 其之前所有的 entry 也是 commited 的 而如果不存在后续的 entry 则可能会有其他更高 term 的节点 其 log 是不一致的 从而覆写了这个 entry
Pesudo Code
- 变量:

- RequestVote RPC:

- AppendEntries RPC:


Snapshot
- 这部分上课没有讲 但是 Lab 里有 因此简单提一下
- 随着时间的推移 日志条目数量会不断增加 导致存储空间消耗增加 日志回放变慢 于是 Raft 通过快照将日志压缩 使状态机只需要从快照恢复而不必回放所有日志条目 从而提高效率
- 定义:快照是整个状态机的当前状态的存档 包含了从系统初始化到快照点的所有信息
替代了快照点之前的日志条目 - 触发条件:通常是基于日志大小或时间间隔等条件触发的 例如当日志条目达到一定数量或大小时生成快照
- 生成过程
- Leader 在某个合适的时间点将状态机的当前状态存储为一个快照文件 生成快照时系统会阻塞新的客户端请求 确保快照的一致性
- 生成快照后 系统丢弃快照点之前的日志条目 相当于 CKPT
- 安装(恢复)过程
- 当一个节点显著落后于集群时 使用快照来加速恢复 Leader 会将快照发送给落后的节点 使用 InstallSnapshot RPC 进行传输 传输可以使用分块来减少网络开销
- 接收快照的节点将快照文件存储在本地 并用快照中的状态覆盖当前状态 节点从快照恢复后 将继续应用快照点之后的日志条目 以达到最新状态
- 优点
- 减少存储需求:可以丢弃早期的日志条目 减少日志文件的大小 节省存储空间
- 提高恢复效率:从快照恢复状态比从头开始回放所有日志条目要快得多 尤其是在系统运行时间较长、日志数量较多的情况下
- 简化日志管理:快照使得日志文件更短、更易于管理 有助于提升系统的整体性能
LEC 17: Introduction to Computing Network
Intro to Network
- Layers in Network (for CSE)
- Link Layer:把数据包从一个节点传输到另一个节点 比如 WiFi、Fiber
- Network Layer:给定两个节点 找到一条路径 通过不断的转发将数据从一个节点传输到另一个节点 比如 IP
- End-to-End Layer:所有剩余的应用接口都属于这一层 它们都是应用和应用之间的约定和协议 比如 TCP、UDP
- Application:应用层 并非网络的一部分
- Hour Glass Protocols
- Internet 的架构就像是一个沙漏 中间的 Network 层是最窄的
- 这是因为 Network 层负责了连接 这个连接的协议应该越少越好 便于简化统一
- 因此目前的网络协议都是基于 IP 的
- 另外 网络层不应该关心数据包的内容是否正确 这能够保证通信的速度尽可能快 但是质量不一定好 也即 Best Effort
- Packet Encapsulation(一个网络包的结构)
- Data
- TCP/UDP Header
- IP Header
- Frame Header & Trailer(以太网为例)
- Application Layer
- Entities:Client & Server
- Namespace:URL
- Protocols:HTTP、SMTP、FTP、DNS
- 关心的是数据的内容
- Transport Layer
- Entities:Sender & Receiver、Proxy、Firewall
- Namespace:Port 65535 个
- Protocols:TCP、UDP
- TCP 会关心数据的丢包与重传 UDP 不关心
- Network Layer(IP Layer)
- Entities:Gateway、Bridge、Router
- Namespace:IP
- Protocols:IP、ICMP
- 关心的是如何根据路由表找到下一跳
Link Layer
- Physical Transimission w/ Shared Clock
- 使用两条线 一条传输 clock 一条传输 data
- 每当遇到 clock 的上升沿就采样一次 data
- clock 的频率越高 传输速率越快
- 要求 data 和 clock 的高度同步 在宏观下无法做到如此精细的控制
- 不适用于长距离传输 只适用于 CPU 内部寄存器之间的数据传输
- Physical Transmission w/o Shared Clock
- 使用三条线 一条传输 data 一条传输 ready 一条反向传输 ack
- 初始时 ready 和 ack 都为 0 假设 A 要发送数据给 B
- A 将数据放在 data 线上 然后将 ready 置为 1
- B 收到 ready 后 读取 data 然后将 ack 置为 1
- A 收到 ack 后将 ready 置为 0 同时可以继续发送下一个数据
- B 收到 ready 后将 ack 置为 0 这样就完成了一次数据传输
- 需要两轮 RT 才能完成一次数据传输 考虑并行化来提高传输速率
- SCSI、printer 都是这种方式
- 并发时 会由传输最慢的线决定速度 并且数据会有互相干扰
- Serial Transmission
- VCO(Voltage Controlled Oscillator)是一种可以根据数据的变化来控制输出频率的电路 使用 VCO 作为接收端的时钟源 可以实现数据的单线传输
- Manchester Code:VCO 非常依赖于数据的变化 为了让数据一直变化 采用曼彻斯特编码 即 0->01 1->10 相对的 牺牲了一半的传输速率
- 多个端复用同一根线有两种方式:
- Isochronous-Multiplexing:同步的分时复用
- 为了避免数据的干扰 把 1s 成多个 frame 每个 frame 只能传输一个数据源的数据 相当于一个端的数据被放在了分开的多个 frame 里
- 优点是非常稳定 即使不发送数据也会保留 frame 给端 缺点是利用率是固定的 超过最大端数直接拒绝 一般用于电话线(其实现在也不太用了 多用于航天航空通信)
- Asynchronous Link:Frame & Packet
- 每个数据包(frame)都有一个 header 用于标识数据的来源和目的地 数据包全部发给 switch 排队等待 switch 处理后再发送数据包 广泛用于现在的各种数据传输
- 一个细节是 queue 的长度不是越长越好 反而应该是一个合适的长度 并且丢弃所有超出长度的数据包
- Frame’s separator:用 7 个 1 标记 如果数据内容中出现了 6 个 1 则在后面加一个 0 防止误判 比如数据中的 7 个 1 就变成了 11111101 6 个 1 就成了 1111110
- Error Handling:一般会对包头进行 checksum 注意我们不仅希望检测出错误 更希望能够纠正错误 因此需要使用一些特殊编码来进行纠错
- Hamming Distance:两个数据之间不同的位数 编码的海明距离越大 也就保证了错误的编码越不容易落到合法空间 可以检测与纠正的错误也就越多
- 一种简单的编码是 2bits->3bits
- 00->000 01->011 10->101 11->110
- 这种编码保证任意两个编码之间的 Hamming Distance 至少为 2 也即当某一个编码发生 1 位的错误 必定可以被检测出来
- Hamming Code
- 4bits->7bits 允许纠正 1 位错误 检测 2 位错误(即 2 位错误不可能落到合法空间)
- P1、P2、P4 是校验位 用 P3、P5、P6、P7 的异或来计算
- 3 个校验位出错的可能有 7 种 即 P1 出错、P2 出错、P1&P2 出错…P1 & P2 & P4 出错 刚好包含了 7 个位 对应 7 种错误
- 海明编码保证了出错的校验位之和就是出错的位 比如 P1 & P2 出错代表了第 3 位出错

- Isochronous-Multiplexing:同步的分时复用
LEC 18: Network: Network Layer
Network Layer
- Addressing Interface
- Network attachment point(NAP):网络接入点
- Network address:接入 NAP 后获得的地址
- Source & Destination
Routing
- 两种路由方式
- Static Routing:静态路由
- Adaptive routing:自适应路由 随着节点的变化而变化
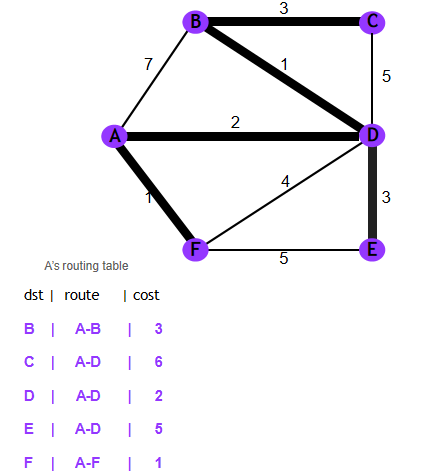
- Routing Table
- 一个路由表包含了多个路由项 形如<IP,next_hop> 即根据 IP 找到下一跳
- 网络层的工作分为两个部分
- Control-plane:负责构造路由表 正确性要求高
- Data-plane:负责根据路由表找到下一跳 要求速度快
Control-plane
- Distributed Routing Overview
- 节点通过 Hello protocol 认识其邻居
- 节点通过 advertisements 知道邻居都认识谁
- 节点通过自己知道的 routes 计算最短路径
- 2 Routing Protocols
- Link-state(发的人多 发的内容少)
- 节点的 advertisements 中包含其所有邻居的 costs
- 使用 flooding(广播)的方式 advertise 所有节点
- 通过 Dijkstra 算法计算最短路径 即找到当前 min-cost 的节点 然后用其邻居更新自己的 cost 直到所有节点的 min-cost 都被确定
- 因为是广播 因此部分节点 fail 不会影响整个网络
- Pros & Cons
- Fast convergence
- flooding is costly:2 * Nodes * Lines 的开销
- Only good for small networks(对于大网络来说开销太大)

- 路由表如图:
- Distance-vector(发的人少 发的内容多)
- 节点的 advertisements 中包含所有已知节点的 costs 以及是通过哪个邻居到达的
- 只对邻居进行 advertise
- 通过 Bellman-Ford 算法计算最短路径 即不断使用邻居的信息更新自己的信息 最终 cost 会收敛到最小值
- Infinity Problem:可能会因为节点之间的断开而导致无限循环 因此需要 Split Horizon 即不能把来自某个节点的信息再发给这个节点(比如 A 到 C 的最短路径是 A->B->C 那么 A 不应该把这个信息发给 B)
- Pros & Cons
- Low overhead:2 * Lines 的开销
- Convergence time is proportional to longest path
- Infinite problem
- Only good for small networks(对于大网络来说收敛时间太长)
- Link-state(发的人多 发的内容少)
- How 2 Scale:上述两种方法都只适用于小网络 如何扩展到更大的网络?
- Path-vector Routing
- 与 Distance-Vector 类似 只不过维护的是路径向量表 也即路径上的所有节点 然后转换为转发路由表
- 收敛速度更快 开销较大 但仍小于 link-state
- 如何避免 loop?保证路径中没有自己即可
- 遇到多条路径通向一个节点时如何选择?选择最短的
- 图变化了怎么办?router 需要抛弃任何包含挂掉节点的路径(邻居停止 advertise 就被视为挂掉)
- Hierarchicy of Routing
- 通过将节点分到不同 region 来减少路由表的大小 即只需要记录到某个 region 的 next_hop(仍需要维护 local region 的节点路由表)
- Region 也被称为 AS(Autonomous System)自治系统
- 随之带来的问题是需要快速根据 IP 地址查询出所在的 region
- 因此必须把 address 和 location 进行绑定 即一个地区的 IP 必须是相同前缀的
- 同时需要两个路由协议 负责跨 region 的路由与 region 内部的路由
- BGP(Border Gateway Protocol)就是用于跨 region 的 path-vector 的协议
- Topological Addressing
- 尽管 BGP 是跨 region 的路由协议 但是它仍然是通过记录 IP 地址来进行路由的(即 IP 地址的集合)这样就导致路由表很大
- CIDR(Classless Inter-Domain Routing)是一个用于压缩连续 IP 地址的协议 通过将 IP 分为 prefix 和 suffix 两部分来减少路由表的大小 比如 18.0.0.0/24 代表了 18.0.0.0 到 18.0.0.255 的所有地址
- Path-vector Routing
- 最终的架构就变成了两个路由表 一个是 local region 的路由表 一个是跨 region 的路由表 使用 BGP
Data-plane
- Data-plane 关注的是如何快速转发数据包 对于一个万兆的交换机 一秒钟可能要处理 10^9 个数据包 也就意味着只有几百个 cycle 来处理一个数据包 因此需要非常精简的代码逻辑
- Interface
- packet:数据包 struct
- src:源地址
- dest:目的地址
- end_protocol:应用层协议
- payload:数据
- NETWORK_SEND(segment_buffer,dest,net_protocol,end_protocol)
- 封装数据包 并把数据包交给 HANDLE
- NETWORK_HANDLE(packet,net_protocol)
- 检查 dest 如果是自己 则转发给 end_layer
- 否则查找路由表 并通过 link 层发送给 next_hop
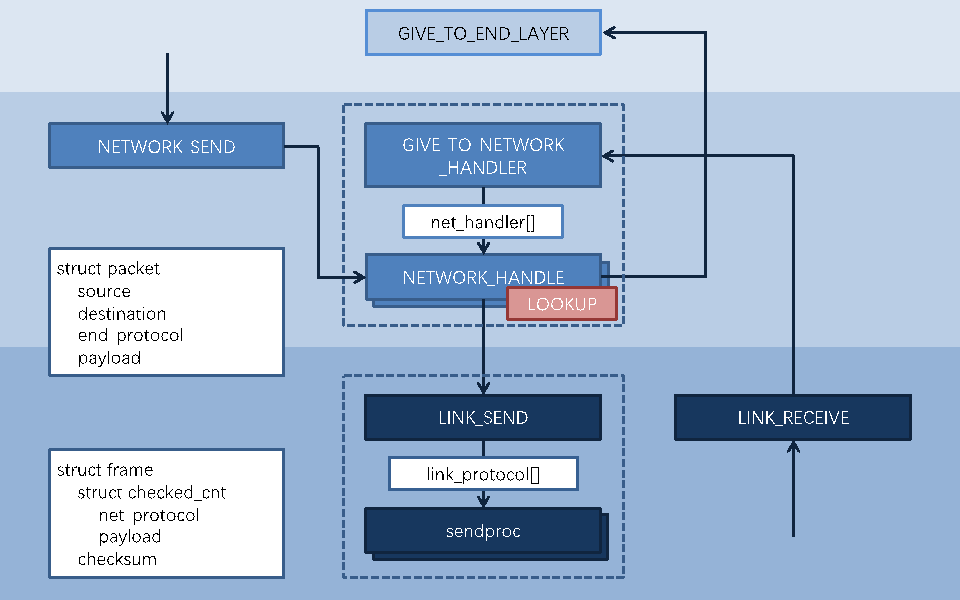
- packet:数据包 struct
- Forwarding
- 查找路由表 如果没有则丢弃
- TTL(Time To Live):每经过一个节点 TTL 减一 如果 TTL 为 0 则丢弃 也就是最多转发几次 主要是为了防止 loop
- 更新 header checksum
- 转发给 outgoing port
- 将数据包通过 link 层发送给 next_hop
- DPDK(Data Plane Development Kit)
- Intel 的 DPDK 通过轮询检查端口是否有转发来提高性能
- RouteBricks
- 伯克利的几个学生收到 DPDK 的启发 通过几台 PC 实现了超高带宽的路由器
NAT (Network Address Translation)
- 将内网的 IP 翻译为外网的 IP 以实现多个内网设备共享一个外网 IP 映射到其不同的端口上(也就是复用了 IP 利用了端口)
- 为什么需要 NAT?
- IPv4 地址不够用 因此拆分为内网和外网地址 外网仍旧是唯一的 而内网地址可以在不同的局域网中复用(IPv6 则不需要 NAT)
- 内网中的设备不会被外网直接访问 起到了保护作用
- Router 会保存形如 <Src IP, Src Port, NAT Port> 的映射表 也就是将内网的一个端口映射到了 Router 的一个连接到外网的端口上 如下图:
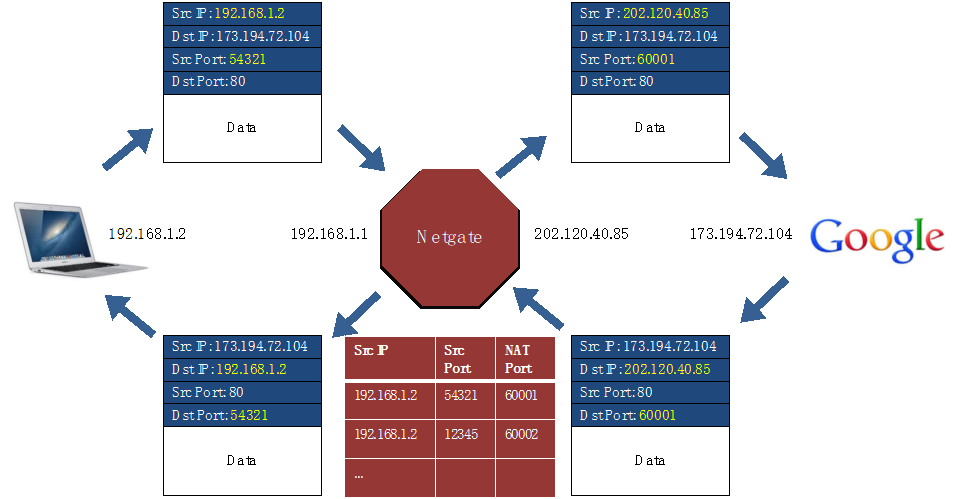
- 网络层的 IP 协议 去修改了 Payload 中的 Port 信息(属于 end layer)破坏了解耦 如果 end layer 更换为一个没有 Port 的协议 则 NAT 就无法工作(现实是 TCP 与 UDP 霸权了)
LEC 19: Network: End-to-end Layer
Case Study: Ethernet
- Basics
- 以太网一开始是为网络层设计的 后来被 IP 打败了 最后作为 Link Layer 的协议使用
- 还记得网络层中路由找到 next_hop 后把数据包发送给了一个路由器吗?接下来这个路由器需要干的事就是通过以太网发送数据包给局域网内的某个设备
- 按我的理解 IP 就是负责不同局域网之间的路由 而 eth 则是负责局域网内不同设备之间的路由 其原理是类似的
- IP 关心所有节点 而 eth 只关心与自己直接相连的节点
- 以太网的地址是 MAC 地址(48 bit) 不过 MAC 地址并非严格唯一的 基本只能保证在一个局域网内唯一(由于 eth 只用于局域网内的通信 因此足以)
- Hub & Switch
- 都是局域网内部的设备
- Hub:广播所有数据包到所有端口
- Switch:只发送数据包给目标端口
- HANDLE API(4 broadcat)
- 如果是自己的地址 处理 否则忽视 无需转发
- 如果是 BROADCAST 地址(一个特殊的地址) 处理
- Layer Mapping
- 根据 dest 的 IP 判断目标是否在同一个局域网内(根据是否是内网 IP 来判断)
- 若是发送给局域网内部的设备 只需要通过 MAC 地址即可确认
- 若是发送给外网的设备 需要发送给 router router 会根据 IP 地址找到下一跳发送给其他局域网的 router
- 因此设备需要维护一张映射表<IP, MAC> 其中内网 IP 映射到内网 MAC 外网 IP 映射到路由的 MAC
- router 为了进行转发 还需要维护直接连接的其他 router 的 <IP, MAC>
- ARP(Address Resolution Protocol)
- 通过 ARP 协议 一个新加入的设备可以构造出<IP, MAC>的映射表
- 通过广播的方式询问一个 IP 对应了哪个 MAC 填入 ARP 表中
- 类似一个缓存 会不断更新
- RARP(Reverse ARP):通过 MAC 找 IP
- An Example
- app 想要给百度发包 先填入 src IP 与 dest IP

- 这是一个外网 IP 因此会发送给 router 即 src MAC 为自己的 MAC dest MAC 为 router 的 MAC

- router1 收到包后 根据路由找到了下一跳的 IP 地址 并通过 ARP 解析出 MAC 地址 于是 dest MAC 变为 router2 src MAC 变为 router1 同时根据 NAT src IP 变为 router1

- router2 和百度位于同一个局域网内 因此包的 dest MAC 变为百度 src MAC 变为 router2 注意 src IP 仍为 router1 否则百度无法回复给正确的 IP 地址

- app 想要给百度发包 先填入 src IP 与 dest IP
- ARP Spoofing:通过伪造 ARP 包来欺骗别人的 ARP 表 从而把数据包发送到 hacker 的设备上 成为了一个中间人
- 防御方法:ARP Cache Poisoning Detection 也就是监测 ARP 包的流量 异常就会有人给你打电话哈(治标不治本)
- 也可以通过静态 ARP 表来防御 需要手动添加新设备
End-to-End Layer
- 端到端层关注的是数据的延迟 丢包 重传等问题
- Famous Transport Protocols
- UDP(User Datagram Protocol):无连接 不可靠 几乎和 IP 包一样
- TCP(Transmission Control Protocol):面向连接 可靠
- RTP(Real-time Transport Protocol):用于实时传输 基于 UDP
Assurance of End-to-End Protocol
- 下面讲的是 TCP 如何处理网络层发生的问题
- at-least-once delivery
- 包带上 nonce(即 ID)
- Sender 保存数据包的 copy
- 如果超时则重发
- timeout 绝对不能是固定的 否则一旦有网络拥塞就会导致大量的重发 越重发越拥堵 导致恶性循环
- 类似的 spring 中的
@Scheduled注解 就应该采用 fixedDelay 而不是 fixedRate 前者是从上一个任务结束后开始计时 后者是从上一个任务开始时计时 - Adaptive Timeout:根据 RTT 动态调整 timeout 初始设为 RTT 的 1.5 倍 一旦发生超时则翻倍
- NAK(Negative Acknowledgement):receiver 给 sender 发送 ack 时 带上丢失的数据包 sender 只需要维护一个全局的 timeout 来判定最后一个包是否收到 其他包则由 NAK 来确认 相应的 receiver 需要 timeout 来判断 NAK 是否丢失 适用于某些特殊情况
- Receiver 会返回带有 nonce 的 ack Sender 就可以删除这个 nonce 了
- 可能会导致重复 这是 at-most-once 需要解决的问题
- at-most-once delivery
- 维护一张收到过的 nonce 表
- 收到数据包时检查 nonce 是否重复
- nonce 表会无限增长 产生 tombstone 即无法删除的数据(因为无法确定未来会收到哪些 nonce)
- 另一种方法是实现幂等性的应用 容忍重复的数据包
- 另一种方法是维护递增的 nonce 然后记录收到过的最大连续的 nonce 小于等于这个值的 nonce 都不接受(比如收到过 1 2 3 5 则不接受 1 2 3)不过此时这个值就成为了 tombstone
- 另一种方法是为每一个新的请求使用唯一的端口 处理完数据包后关闭端口 问题是端口是有限的 最终一定会循环
- Duplicate Suppression
- sender 最多发送 3 次 则 receiver 可以在 3 * RTT 后删除这个 nonce
- receiver 需要把 nonce 表存在内存里(为了性能)这就导致重启会导致表丢失
- data integrity
- checksum 无法完全保证 只是概率问题
- stream order & closing of connections
- when out-of-order(如何保证包的顺序?)
- 只接受有序的包 乱序的包直接丢弃 问题是浪费了带宽
- 接受所有的包 暂存于 buffer 中 直到连续的包都到达 问题是需要很大的 buffer
- 结合上述两种方法 当 buffer 满了就丢弃乱序的包 问题是 buffer size 的选择
- 使用 NAK 加快丢包的重传 让 buffer 尽快释放
- TCP 协议使用 ACK 而没有使用 NAK
- when out-of-order(如何保证包的顺序?)
- jitter control
- 可能会出现延迟抖动 即数据包的延迟不稳定
- 解决方法是缓存 保证数据的稳定性
- 需要缓存的 segment 数量是 (最长延迟 - 最短延迟) / 平均延迟
- Authenticity & Privacy
- 证书机制 使用公私钥
LEC 20: Network: TCP & DNS
End-to-End Layer
Assurance of End-to-End Performance
- Lock-step protocol:Sender 一次只发送一个包 等 Receiver ack 了再发送下一个包 虽然保证了正确性 但是会导致很低的带宽利用率
- Overlapping Transmission
- Sender 一次发送多个包 Receiver 一次 ack 多个包
- Fixed Window:一次发送固定数量的包 然后停下来稍作等待 窗口大小由 Receiver 的性能决定 因此 Receiver 不会阻塞 不过还是有大量的空闲时间
- Sliding Window:Sender 接受到第 i 个 ack 后发送第 i+n 个包 window 大小相当于 n+1
- 减少了 Idle Time
- 一旦有包丢失 window 就会卡住 等重发后才能继续滑动 这是可以接受的 因为丢包往往意味着网络问题 此时做等待是合理的
- Window Size
- 太小会导致空闲时间和低网络利用率 太大则会阻塞 设置为 1 就变为了 Lock-step
- window size >= RTT * bottleneck data rate(最低带宽 即 sender 与 receiver 的较低值):可以理解为一个水管 window size 就是水管的容量 RTT 就是水管的长度 bottleneck data rate 就是水管的最小直径 我们要尽量让水充满整个水管
- window size <= min(RTT * bottleneck data rate, receiver buffer size):为了 congestion control
- TCP Congestion Control
- end-to-end 和 network 层负责 前者控制发送的速率 后者可以直接感知到网络的拥塞(比如丢包 也是一种节流的方法)
- Why Congest?处理超时的包没有意义 反而会导致更多的重发 因此需要控制发送的速率
- Basic Idea:开始时缓慢增加 cwnd(congestion window)一旦出现丢包则迅速减小 cwmd
- AIMD(Additive Increase Multiplicative Decrease):慢慢增加 快速减小 也即 cwnd+=1 遇到丢包则 cwnd/=2 问题在于最开始的增长太慢了
- Slow start:一开始指数级增加 cwnd 直到出现丢包 之后回到 AIMD
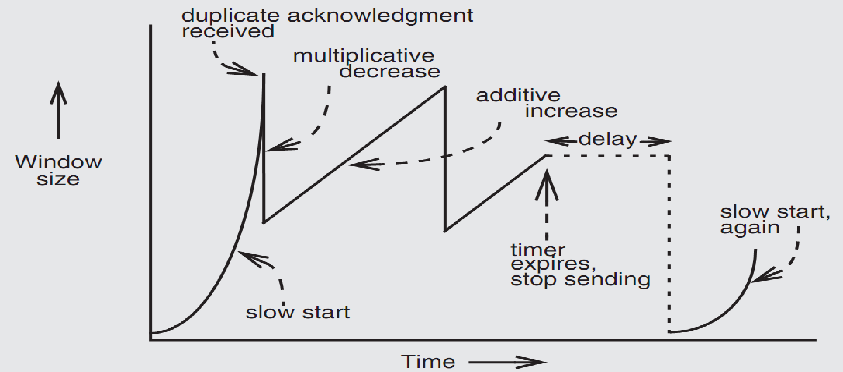
- Duplicate ack:出现丢包后 Receiver 会发送重复的 ack 通知 Sender 有包丢失了 用于尽快告知 Sender 丢包 从而调整 cwnd
- 一旦没有 dup ack 而是 timeout 则说明网络出现了严重的拥塞 会将 cwnd 重置为 1
- 最终 TCP 通过不断感知丢包 使得发送速率逐渐逼近网络的最大带宽
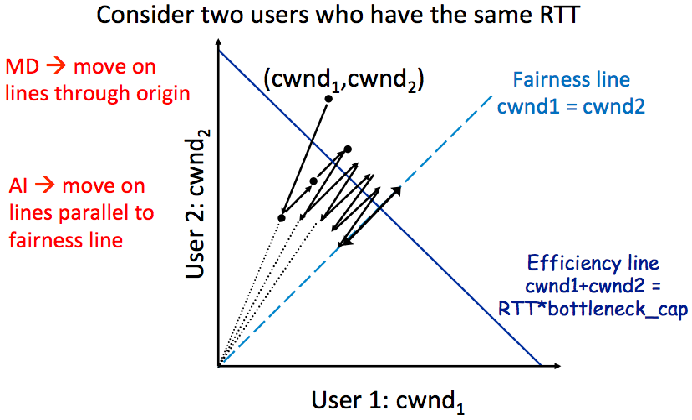
- Efficency & Fairness:如果画出二维图 会发现(cwnd1,cwnd2)这个点增长时是沿着 y=x 的方向增长的(因为是+=1) 而减少时则是向着原点减少的(因为是/=2) 最终会收敛到 y=x 上震荡 也就保证了公平性
- Weakness of TCP
- 如果 router 的 buffer 太多 会导致时延很长
- 无线网的丢包主要是因为信号不好 应该加快速率 由于 TCP 的节流反而会减少速率 导致恶性循环
- 不适合带宽高时延低的场景 比如数据中心 会浪费大量网络资源(也就是由于节流而浪费的带宽)
- 更偏向于 long RTTs
- 需要合作的对端
DNS (Domain Name System)
- DNS 的重点在于 hirarchicacy 与 de-centralization
- 一个域名可以对应多个 IP 地址 一个 IP 地址也可以对应多个域名
- 一开始 DNS 映射都存储在一个 txt 文件中 随着域名越来越多 产生了 BIND
- BIND(Berkeley Internet Name Domain)是由 4 个伯克利学生开发的 DNS 实现 目前仍被广泛使用
- bindings 被记录在多个称为 name servers 的服务器上 以达到 distributing 的目的
- Name Servers
- root zone:ICANN 维护 非盈利
- top-level domain:.com .org .net 等 由 Verisign 维护 盈利
- second-level domain:由注册商维护 如我注册的 blog.nwdnysl.site
- DNS 的解析过程从后往前 从根服务器开始逐个递归找到对应的 name server 的 IP 地址 通常返回多个 IP 地址
- DNS 是 global 的 全球唯一
- 实际上最后的根域名是
.比如blog.nwdnysl.site.通常会省略 - 为了容错 一个 zone 通常会有多个 name server
- 3 Enhancement on Lookup
/etc/hosts中可以存储<IP,Domain>的映射 用于本地解析/etc/resolv.conf中可以存储一些 name server 的 IP 会优先使用它们来解析 如果没有配置 则使用默认的根域名服务器- DNS Request Process
- 递归查询:由 name server 递归查询 即 A 问 B B 问 C C 问 D 由于 name server 的性能比较好 因此递归查询的速度会比较快
- 迭代查询:由 client 逐个查询 即 A 问 B A 问 C A 问 D 虽然速度比较慢 但是中间结果不会丢失
- Caching DNS
- client 与 name server 会缓存 DNS 的查询结果
- 缓存有 TTL 一旦过期就需要重新查询
- TTL 太长会导致 DNS 解析错误 太短则会导致 DNS 性能下降
- Hostname & Filename
- 都是 user-friendly 的
- 都将 hierarchical 的名字映射到 plane 的名字
- 都不属于映射对象的一部分
- Bad Points
- Policy:谁来管理 root zone?技术有国籍
- root servers 的负载太重 如果查询一个不存在的域名 会造成大量服务器的负载 甚至可以形成 DDOS
- Security:DNS 可能会被污染 也即返回错误的 IP 地址 通常是通过 SSL 来解决
LEC 21: Network: P2P
Naming Scheme
- Naming for modularity
- Retrieval:通过名字找到数据 比如 URL
- Sharing:通过名字共享数据 比如文件系统
- Hiding:封装低层语义 比如 fs 封装了 inode# 从而保护了 fs 的安全
- User-friendly:易于记忆
- Indirection:解耦名字和数据 一个名字可以对应多个数据
- Naming Model
- name space:名字的集合
- value space:值的集合
- mapping:将名字映射到值的算法
- context:名字的上下文 比如文件系统的当前目录
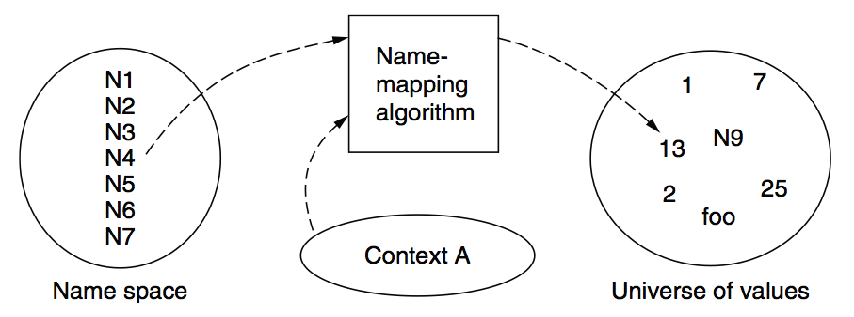
- Lookup Algorithm
- recursive lookup:递归查询
- multiple lookup:多重查询 即逐个依次查询 比如查询 path 中的命令
- Naming API
- RESOLVE(name,context):返回值
- BIND(name,value,context):绑定值
- UNBIND(name,context):解绑值
- ENUMERATE(context):返回所有的名字
- COMPARE(name1,name2):比较两个名字是否相等
Content Distribution(内容分发)
- CDN 即内容分发网络 通过将数据缓存到离用户最近的服务器上来提高访问速度 典型的边缘计算模型
- Server Selection
- HTTP redirection:通过重定向来选择服务器(逐渐废弃)
- 优点:细粒度控制、根据用户的 ip 来选择
- 缺点:需要多次请求、server 会有负载
- DNS-based:通过 DNS 获取多个 IP 选择一个最近的
- 优点:避免了重定向的延迟、DNS 缓存减少了开销
- 缺点:不一定是最近的 因为是根据 DNS
- Akamai:通过 DNS 来选择最近的服务器
- 向 Content Provider 发送请求
- 返回一个 name server
- 不断迭代查询 直到找到最近的服务器
- 最近的服务器会缓存客户端需要的数据
- HTTP redirection:通过重定向来选择服务器(逐渐废弃)
- CDN 的思路是将数据尽可能下推到用户的附近 让我们思考的极端点 不妨将数据直接存放到用户的设备上 这就是 P2P 的思路
P2P
- P2P(Peer-to-Peer)是一种去中心化的网络结构 通过将数据分布到每个用户的设备上来提高访问速度
BitTorrent
- Roles
- Tracker:用于记录哪些 peer 有文件的哪些部分 通常是一个中心化的服务器
- Seeder:拥有完整数据的 peer
- Peer:下载数据的 peer 下载完后会变成 seeder 通常是一个普通的用户设备
- Steps
- 发布一个
.torrent文件到服务器上 里面包含了 tracker 的 url、文件名、文件大小、文件的 SHA-1 值等信息 - Tracker 会记录一组 peer 的信息 即它们包含了文件的哪些部分
- Seeder 会告知 tracker 自己有完整的文件
- Peer 通过 tracker 获取到一组 peer 并通过 peer 之间的连接来下载文件
- 总的来说 就是 peer 通过中心化的 tracker 获取到可以用于下载的 peer 列表 然后就可以去中心化的进行下载了
- 发布一个
- Protocol
- Random for first one(随机选择第一个数据块)
- Rarest for the rest(选择 peer 最少的数据块)
- Parellel for the last(并行下载最后一个数据块 只要有一个完成就成功)
DHT(Distributed Hash Table)
- BitTorrent 仍存在中心化的 tracker 为了去中心化 可以使用 DHT 来分布存储文件的元数据
- 简单来讲 DHT 的 key 是文件的 SHA-1 值 value 是存储了该文件的 peer 节点信息 这样当需要下载某一个文件时就可以通过 DHT 来找到对应的 peer 省去了 tracker
- Chord Protocol(一种 DHT 的实现)
- IDs
- keyId=SHA-1(key)
- nodeId=SHA-1(IP)
- keyId 和 nodeId 在同一个 ID 空间
- 通过一致性哈希来实现分布式存储
- ID 空间是一个环
- 每个节点负责一个区间为
(predecessor,successor]的区间 换句话说 一个 key 会存储在 ID 空间中最近的后继节点上 - 比如这个节点的 ID 是 5 下一个节点的 ID 是 10 那么节点 10 负责存储的 key 就是
(5,10] - 此时已经可以通过遍历每个节点来找到大于 keyId 的第一个节点 但是太慢
- 通过 Finger Table 来实现 O(logN)的查找
- 记录离当前节点 1/2 1/4 1/8…的位置 然后进行类似二分的跳跃
- 如果节点挂掉 finger table 可能会导致错过新存放了数据的节点
- 结合两者即可解决 节点记录 successor list(每个节点的下 r 个节点)当发现跳跃到的节点挂掉时就可以遍历 successor list 来找到正确的节点 其中网络越稳定 r 越小

- Join 新节点
- 只需要向其 successor 查询一下 并更新自己的 finger table 并不需要修改其他节点的 finger table 因为不会影响实际的查询负载
- 当节点比较少时 可能会存在负载不均衡的问题
- Virtual Nodes:将虚拟节点均匀分布在 ID 环上
- 一个物理设备可以映射到多个虚拟节点 即负责多个区间的 key 存储
- 虚拟节点的数量越多 负载越均衡
- IDs
- 可以看到从 C-S 到 CDN 再到 P2P 文件的共享方式越来越去中心化
LEC 22: Distributed Computing: Intro
- 人工智能的发展导致需要大量的计算资源 也就必须得扩展为分布式计算
- AI 训练计算所需要的性能是非常好计算的
- 一个神经网络层 W 是 m*k 的矩阵 X 是 k*B 的矩阵 B 为 batch size k 为输入维度 m 为输出维度 那么计算 W*X 的时间复杂度为 (2k-1)*m*B
- backward path(反向传播)需要计算 dW 和 dX 时间复杂度为(2m-1)*k*B 和(2B-1)*k*m 都可以约为 2*参数数量*Batch Size
- 最终的结论就是 AI 模型训练总的时间复杂度为 6*参数数量*Batch Size
- 对于 GPT 来说 有 1.76trillion 个参数 一张 A100 显卡的性能是 19.5TFLOPS 那么训练一个 GPT 需要 30s 进行一次迭代 非常的耗时
- 我们最终的目的是使用足够的算力进行分布式训练 接下来将先从单个计算设备开始讲起
Computing Device
- 单个设备提升算力的关键就是并行
CPU
- 单核 CPU 系统 算力上限取决于 Clock Rate 一个时钟周期最多做一次指令 (当然也有使用 pipeline 和超标量的方法来提高单核的算力)然而硬件的主频基本上因为散热问题已经到了极限
- 多核 CPU 系统 算力上限取决于核心数 然而和分布式类似 最恶心的还是 cache 中的 coherence 问题
- 另一种类似多核的方法是增加每个核的 ALU 数量 即 SIMD(Single Instruction Multiple Data)的思想 一条指令处理多个数据
- 需要新的指令集(比如 Intel 的 AVX)增加了代码的复杂度
- 性能增益不可能达到理论的倍增 因为指令可能有依赖
- 有时候访存也会成为性能瓶颈 访存的时间 = Latency + Payload / Bandwidth
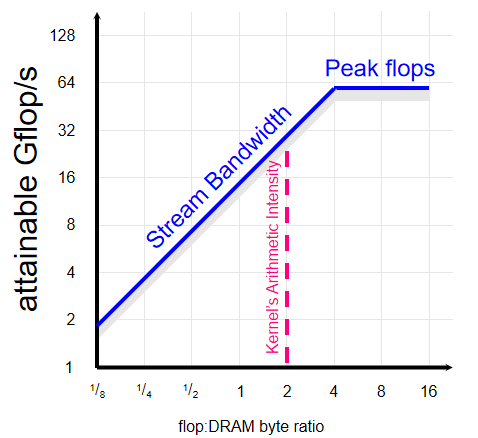
- Roofline Model:刻画算力与带宽的关系图 y 轴是算力 单位是 GFLOP/s 即每秒多少次浮点运算 x 轴是应用利用内存的效率 单位是 Flop/Byte 即读取一个字节数据可以进行多少次运算 于是斜率就是应用对于带宽的需求 单位为 Byte/s 于是设备在图中表示为两条线 一条代表算力的水平线与一条代表带宽的斜线 应用的 OI(Operational Intensity)所落在哪条线 就说明哪个因素是瓶颈
GPU
- 也是两种方式提升算力:增加核心数和 SIMD
- GPU 的 ALU 数量远远多于 CPU 因为 GPU 没有 cache coherence
- SIMD 难以实现分支条件 但是可以通过 mask 来实现 也就是执行所有分支 但是写回的数据会用条件的 mask 来选择 不过还是会造成很多无用的计算 而且编程变得很复杂
- 于是 NVIDIA 实现了 SIMT(Single Instruction Multiple Threads):(没听懂 说是超纲了)应该就是相当于用户指定某一个线程执行某一个任务 比如指定第 i 个线程执行第 i 位的相加
TPU
- Tensor Core:专门用于矩阵运算的核心 替换掉了原来的 ALU 用于加速矩阵运算
- TPUs(Tensor Processing Units):谷歌的专门用于矩阵运算的芯片
Summary
- 单个设备的算力由于种种限制没法无限提高(比如主频是因为散热问题 多核是因为芯片面积问题等)连老黄的显卡的提升也只是因为使用了 tensor core 或是增加了核心数
- 于是就需要分布式计算来提高算力 大部分情况下使用一个开源的分布式计算框架足以 接下来我们介绍一个经典的分布式计算框架:MapReduce
LEC 23: Distributed Computing: Batch Processing
- 分布式计算带来了更高的算力 但是也带来了更多问题 比如编程复杂性、网络通信的延迟等
- 今天我们介绍一个经典的批处理的分布式计算框架:MapReduce
Batch Processing
- 批处理的一个例子是统计很多网页中最受欢迎的网页 其基本思路是分治 比如求所有的 TopK 就可以分成求每个节点的 TopK 然后再合并起来求全局的 TopK
- 以往的批处理基本上都是对于具体的任务进行实现的 这样的代码即难以维护也难以复用 我们需要设计一个通用的批处理框架 但是这往往面临许多挑战
- Challenges for Programmers
- Sending data to/from nodes
- RPC 不够高效
- Coordinating among nodes
- 需要协调各个节点之间的同步
- Recovering from failures
- 规模效应:规模越大 越有可能出现 failure 比如 GPU 风扇积尘
- Optimizing for locality
- 希望数据可以缓存在本地
- Partitioning data for parallelism
- 为了并行处理 需要将数据分成多个部分
- Sending data to/from nodes
MapReduce
- MapReduce 是 Google 提出的一种分布式计算框架 其对于上述 5 个挑战都有很好的解决方案 使得用户可以专注于任务 考虑 map 与 reduce 的实现 而无需考虑其它细节
- How MapReduce Solve Challenges
- Sending data to/from nodes
- 数据只需要在 map 和 reduce 之间传输 并且通过 shuffle & sort 来减少数据传输量
- Coordinating among nodes
- 先调度 map 任务 然后调度 reduce 任务即可
- Recovering from failures
- MapReduce 有 2 个特性使得容错非常简单
- 任务是幂等的 因为 map 与 reduce 并不会对外部状态进行修改 所以可以通过 re-execute 来进行恢复(时间上的冗余)
- 基于一个可靠的文件系统(GFS)其具有许多 replicas 从而可以保证数据的可靠性(空间上的冗余)
- MapReduce’s Fault Tolerance
- Worker failure
- 通过心跳来检测节点是否存活
- 一旦某个节点挂掉 将其原本的任务重置为初始状态 并分配给其他节点执行
- Master failure
- Master 不再能通过重做来恢复 因为一个完整的大任务可能需要很长时间 不可以让之前的进度全部丢失
- 因此可以通过 CKPT 来容错 即 master 的状态(比如每个 worker 的状态 中间结果的位置等)会被定期持久化到 GFS 中 一旦挂掉 通过读取 GFS 的 CKPT 来恢复 不再需要重做所有计算
- MapReduce 有时候会因为调用第三方库而遇到 bug 其处理方式是简单的 skip 因为第三方的 bug 不是 MapReduce 的问题 并且牺牲了一点正确性来保证了容错性是可以接受的
- Worker failure
- MapReduce 有 2 个特性使得容错非常简单
- Optimizing for locality
- 有两部分数据传输 一是 mapper 从 GFS 中读取数据 二是 reducer 从 intermediate file 中读取数据 后者一般比较小 不是性能瓶颈
- 为了解决前者 Master 会把 map 任务分配给存储了这一部分数据的节点 保证数据在节点本地 无需网络开销
- 另外还可以通过把 map 和 reduce 任务分配给同一个节点来减少网络开销
- Partitioning data for parallelism
- map 可以天然并行 reduce 则需要根据 key 来分组实现并行
- Sending data to/from nodes
- Execution Flow(隔壁 AEA 已经写的很清楚了)
- 把输入的数据文件分成多个 shards 一般是 64MB(因为是 GFS 的 block size)
- 集群启动一个 Master 与多个 Worker(通过 RPC fork)Master 会把 map 或 reduce 任务分配给空闲的 Worker 其中一个 map 负责一个 shard 一个 reduce 负责一个 intermediate file
- Mapper 读取 shard 并进行处理 产生中间结果键值对(先放内存 异步落盘)
- 中间结果会缓存在内存中 并异步落盘 然后它们会被划分为 R 个分区 默认使用取模哈希来划分
- 将 intermediate data 排序 确保相同的 key 在同一个文件中 Reducer 就可以尽可能少读取文件 排序使用归并来加速 即 Mapper 在产生 intermediate data 的分区时就会进行排序 只需要进行归并即可
- Reducer 读取中间数据进行处理 产生结果
- 返回结果给用户
- Refinement:redunant execution
- 由于规模效应 在集群中总是有一部分的节点性能比其他差 拖累了整体性能 原因各种各样 甚至包括风扇积灰
- 解决方法是冗余 即同一个任务会被分配给多个节点执行 只要有一个节点执行成功即可 同时这也带来了更多的资源消耗
- 一些应用
- 分布式的 grep
- URL 计数
- 倒排索引的构建
- Reverse Web-Link Graph
- Summary
- 容易扩展
- 容错性好
- 对于适合 MapReduce 的任务性能很好
- 不适合实时处理场景
- 编程抽象有限 可以看到 MapReduce 对于比较复杂的并行化任务并不是很友好 因此下节课我们会介绍 Computation Graph
LEC 24: Distributed Computing: Distributed Computing Frameworks
Computation Graph
- 计算图将计算抽象为 DAG 其中节点代表一个数据或计算 边代表交流通道
- Why DAG?DAG 的容错比较好 一定可以通过依赖关系找到上一个有数据的节点 从而重新计算 如果有环则不能 另外 DAG 可以识别出哪些节点可以并行计算 即没有依赖关系的节点
- Scheduling
- 与 MR 类似 Job Manager(即 Master)会看哪个节点的依赖关系已经满足了 然后分配这个节点的计算任务给空闲的 Worker
- 这些中间状态不用像 MR 一样需要写入 GFS 而是写入内存中的键值系统
- 任务的分配和 MR 一样 会尽量找到数据所在的节点
- 容错则仍然是通过重做来实现 不过需要递归的寻找上游节点的依赖关系
- 举例:用计算图表示神经网络(没有 AI 基础听个吉尔)
- 任意一层的计算可以表示为 x*W->y 其中 x 是输入向量 W 是权重矩阵 y 是激活函数
- 可以根据计算图推出梯度的计算图 通过链式法则
- 将计算和硬件解耦 可以在不同的硬件上运行
- Graph fusion:将多个节点合并成一个节点 减少通信开销
LEC 25 & LEC 26: Distributed Computing: Distributed Training
- 接下来我们终于到达了目的地:分布式训练 下面介绍一下如何使用计算图来进行分布式训练
- 以所有 AI 模型训练都会用到的梯度下降法为例 可以看到求权重的下一次迭代可以表示为如下的计算图 其中 x 是输入 y 是 label w 是当前权重 最终计算出 dw 来更新权重
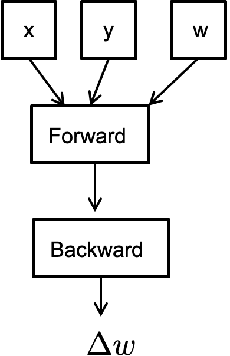
- 为了分布式训练 我们需要考虑如何实现这个计算的并行化 接下来介绍几种常用的并行化方法
Parallelism
- 业界实际场景会使用 3D Parallelism 即同时使用下面三种并行化方法
Data Parallelism
- 即将数据的 batch 划分为更小的部分 分别计算 最后再汇总 比如上图的累加操作
- 第一个问题是 同步的方法导致必须等待所有节点计算完毕才能进行下一次迭代 也就会有某些节点拖累整体性能 这个只能通过异步的方法来解决
- 第二个问题是 被称为 all-reduce 的汇总操作 往往需要巨大的通信与计算开销 比如累加操作中的 sum 操作 其开销决定了整个计算的性能
- 在 all-reduce 中主要的开销是通信开销而并非计算开销 减少通信开销的方法包括减少通信量与减少并发通信 下面是业界常用的几种方法
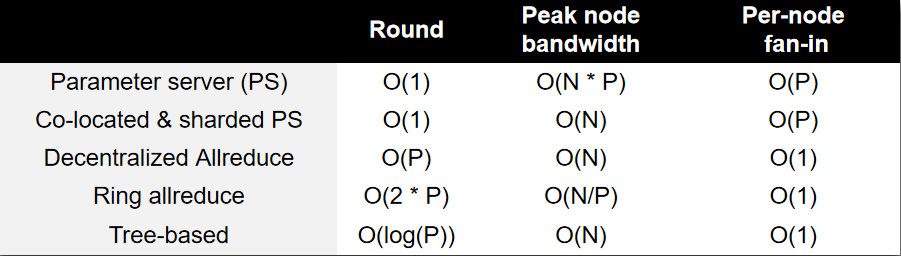
- Parameter Server
- PS 负责接受所有节点的参数并进行 reduce 然后再广播回所有节点
- 假设 N 是节点的数量 P 是参数的数量 那么 PS 需要 1 轮通信 节点的 fan-in 是 O(N) 通信量是 O(N*P)
- 这意味着随着节点的拓展通信量会线性增加 并且需要应对高并发问题
- Co-located & Sharded PS
- 进行 sharding 一个节点只负责一部分参数的 reduce 仍然只需要 1 轮 每个节点的通信量变为 O(P) 与节点数量无关
- high fan-in 问题:每个节点仍需要收到 O(N) 个节点的请求 还是存在高并发问题
- Decentralized Allreduce
- 所有节点串行的发送参数 减少了并发请求 通信量仍然是 O(N * P) 需要的轮数是 O(N^2) 有 O(1)的 fan-in
- 如果 1 给 0 发的同时 2 给 1 发 3 给 2 发 则可以减少轮数为 O(N)
- Ring Allreduce
- 节点的通信形成一个环 即 0->1->2->3 最终节点 3 进行 reduce 并广播
- 结合 sharding 后 看起来就像是每一轮每个节点都会接受上一个节点的参数 并发送参数给下一个节点 最终在 N 轮内结束 注意参数最远只需要走 N-1 步 所以所有参数肯定可以到达目的地
- 同理 广播也可以通过一轮环路通信来实现
- 每个节点的通信量是 O(P) 通信轮数是 O(2*N) 但是每个节点只需要同时处理两个节点的请求 这就是牺牲了网络延迟来换取了低并发
- 这个方法会导致每个参数的 reduce 顺序不一样 如果计算不满足交换律则会导致结果不一样(比如浮点数的加法)
- Tree Allreduce
- 不断二分 reduce 的方法 即每个节点负责两个子节点的 reduce 最终汇总到根节点上 最终再进行广播
- 每个节点的通信量是 O(P) 通信轮数是 O(logN) fan-in 为 3(父节点和两个子节点)
- 然而负载并不均衡(叶与根 fan-in 更少)于是使用 Double Binary Tree Allreduce 将二叉树进行翻转 保证负载均衡
- Parameter Server
Model Parallelism
- 可以看到 Data Parallelism 要求一个节点必须存储所有的参数 然而目前模型的参数量太大 往往一个节点存不下
- 因此考虑把模型的不同层或者每一层的不同参数分配到不同的节点上(水平或垂直切分)也就是 Pipeline Parallelism 与 Tensor Parallelism
- Pipeline Parallelism
- 即把模型的每一层放到不同节点 之所以称为 Pipeline 是因为节点之间有依赖关系 上一层计算完了才能计算下一层
- Pipeline 最大的性能问题是 bubble 即空闲时间
- 通过把 batch 进一步划分为多个 micro-batch 可以减少 pipeline 的 bubble(空闲时间)因为节点可以更早的获取上一层的结果
- 理想情况下 bubble size 是 p-1 而减少的倍数是 (p-1)/m 其中 p 为 partition 的个数 m 为 micro-batch 的数量
- 要想减少 bubble 需要增加 m 或者减少 p
- 增加 m 会导致 batch 太小 GPU 性能下降
- 那么只能相对的增大 batch size 然而这会影响模型的收敛
- p 也不能无限制减少 因为我们切分模型就是为了减少单个节点的参数量 模型的参数量也就限制了 p 的最小值
- Tensor Parallelism
- 由于参数量限制了 p 我们可以考虑把一层进一步划分为多个子矩阵 分配给不同的节点 这样多个节点就可以存储一层 p 也就可以进一步减少了
- 原理很简单 即矩阵乘法可以分解为多个子矩阵的乘法
- 由于在计算了一整个矩阵乘法后 需要汇总成完整的矩阵 因此会有额外的网络通信开销 导致其通信量比 Pipeline Parallelism 更大
- Summary
- Pipeline Parallelism
- 网络通信少
- 有 Bubble
- Tensor Parallelism
- 支持参数多的大模型
- 网络通信多
- Pipeline Parallelism
LEC 27: Security: Intro
- Security 是一个 negative goal 也就是要保证某些事情不会发生
- 为什么不直接用 fault tolerance 来保证安全性?
- fault 的影响可能是非常巨大的
- fault 一般是随机的 而 attack 是有关联的
- 2 Steps to Security
- Policy(Goals):保护什么
- Confidentiality:限制谁可以读数据
- Integrity:限制谁可以修改数据
- Availability:保证服务一直可用
- Threat Model(Assumptions):假设什么
- 威胁模型是对于攻击者的一种假设 包括了攻击者的能力和目标
- 比如 攻击者可以控制一些节点 但是不能控制所有节点
- Policy(Goals):保护什么
Authentication: Password
- 可以基于不同的因素进行认证
- knowledge-based:密码 安全问题
- have-based:门卡 钥匙
- are-based:指纹 人脸识别
Password
- Goals
- 认证用户
- 攻击者必须靠 guessing 来破解密码 是非常 expensive 的
- Timing Attack:通过密码验证的时间来判断密码匹配了多少位 比如通过内存换页 从而导致某些密码的时延变长 于是可以确定每一个字符是否正确 解决方法是比对密码的 hash 而不是密码本身
- Rainbow Table:攻击者构造一张表 存放了最常见的密码与其哈希值 一旦获取到了数据库里存储的哈希值 就可以通过在彩虹表里碰撞来获取密码
- Salting:彩虹表的解决方法是加盐 即在密码后面加上一串随机字符串再进行哈希 此时攻击者若还想构造彩虹表就需要对每一种可能的<password,salt>都进行哈希 成本成倍增加
- Strawman:现在大部分网站会使用 cookie 一般是对于<server_key, username, expiration>的哈希值 然而这样的键值对具有二义性 比如名为”BEN”的用户获取一个在”22-12-2020”过期的 cookie 与名为”BEN2” 在”2-12-2020”过期的 cookie 是一样的 解决方法是加入 split 符 比如
BEN/22-12-2020 - Phishing Attack:通过伪装的网站来获取用户的密码 比如 baidu.com 和 baidv.com
- Key Problem: 一旦攻击者持有密码 就可以成功登录 有一些解决的方法如下
- 本地计算哈希 每次 server 发送一个随机值给 client client 计算<password,random>的哈希值发送给 server 缺陷是 server 必须保存明文
- 反向验证 让 server 发送给 client 密码 确保 server 是安全的
- 要求在线登录 服务器可以发现攻击者的可疑行为 比如暴力破解
- Specific pwd:为不同的网站使用不同的密码
- One-time pwd:每次登录使用不同的密码
- 比如服务器保存密码计算 100 次的哈希值 第一次登录时客户端发送 H99 服务器再哈希一次进行对比 然后保存 H99 第二次登录发生 H98 以此类推 攻击者很难从 H99 推出 H98
- 或者每次计算<pwd,time>的哈希值 使得攻击者无法重放 这也是安全令的原理 它会离线每隔 10s 根据时间生成新的随机值 然后计算<password,random>的哈希值
- 绑定 auth 与 request:对于关键操作 即使已经登录 也需要再次验证密码 比如支付宝的支付
- FIDO:把指纹与密码绑定在一起 验证指纹通过后 程序将使用私钥对服务器发来的数据进行签名 然后返回 服务器发送的数据是由 uid 与公钥(即密码)加密的
- 如何修改密码?
- 一般会发送一个 url 给用户 这个 url 包含了一个由随机数生成的 token 用于验证用户的身份
- 事实上这个随机数是由服务器的一些状态生成的 比如键盘鼠标的输入 网络包的状态等
Security Principles
- Least Privilege:只给予最小的权限
- Least Trust:不要相信任何人
- Cost of Security:安全性是有代价的
LEC 28: Security: ROP and CFI
ROP(Return Oriented Programming)
- 最经典的 ROP 即通过 buffer 的溢出向栈中注入代码 导致 retaddr 被覆写 从而修改了程序的控制流
- DEP(Data Execution Prevention):禁止执行数据段的代码
- Code Reuse Attack:通过将代码段中带有 ret 的指令串联起来来实现攻击
- Defenses
- 隐藏二进制文件 使得攻击者无法读取汇编代码
- ASLR(Address Space Layout Randomization):随机化内存地址 这是因为现在的代码都是地址无关的
- Canary:在栈中的 retaddr 前插入一些特殊的值 一旦被修改则说明栈被破坏了
CFI(Control Flow Integrity)
- 通过检查程序的控制流来防止 ROP 攻击
- Branch Types
- Direct Branch:直接跳转
- DIRECT CALL:调用函数
- DIRECT JUMP:跳转
- Indirect Branch:间接跳转
- RET:返回
- INDIRECT JUMP:跳转到 RAX 寄存器中的地址
- INDIRECT CALL:调用 RAX 寄存器中的地址
- 事实情况是 运行中的代码大部分都是间接跳转 并且跳转的目标地址大部分都是确定的 绝大部分只有不超过 2 个目标
- Direct Branch:直接跳转
- Instrumentation
- 在原代码的 jmp 指令前加入一段检查代码 其会检查 jmp 的目标地址是否是某一个硬编码的数据(比如 12345678) 如果不是则不跳转
- 在目标地址的代码前加入这个硬编码的数据 确保控制流会到这

- 如果第三方库的代码已经加入 data 但是用户的 app 没有加入检查代码 会导致把这段数据当作代码执行
- 解决方法是使用 prefetch 指令 这个指令遇到无法执行的代码会直接跳过 相当于一个 nop

- CFI Precision
- 如果 A 调用 C B 调用 C 或 D 那么要求 C 的 data 与 D 的 data 必须一样 这就导致 A 是可以合法调用 D 的
- 解决方法是修改 B 的汇编代码 把原本的
CALL %eax变为CALL C_ADDR与CALL D_ADDR的直接跳转 缺点是增加了代码大小 - 同理 A 与 B 都调用 C 也会导致 C 的 ret 可以返回到 A 或 B 想要解决就得设法使得每一个目标地址的 data 是唯一的 这非常困难 目前的 CFI 是不考虑这些细粒度问题的
LEC 29: Security: Control Flow Integrity & Secure Data Flow
Blind ROP
- Goal & Assumption
- 攻击者通过 http 请求让服务器变为 bash
- 攻击者只知道服务器代码存在一个 overflow 但是不知道具体的二进制代码
- 攻击者发送 http 请求可能得到三个结果
- 正常返回
- 连接关闭 因为栈溢出了
- 阻塞 未收到任何返回
- Stack Reading
- 首先攻击者可以逐步增加 payload 的大小 从而找到 buffer 的大小
- 然后攻击者逐步改变 retaddr 的某一位 如果连接关闭说明代码跑飞了 如果返回正常说明这一位是正确的 从而得到了 retaddr 的值
- 注意 nginx 处理 http 请求的进程是通过 fork 产生的 因此其地址是与父进程一样的 因此父进程未崩溃的情况下 地址是不会变的
- 同理也是可以把 canary 的值猜出来的
- Find Gadgets
- 现在略微修改 retaddr 的后几位 根据结果是关闭连接还是阻塞来分类 分为 crash 或是 stop gadget
- 然后加入两个 retaddr 第一个是需要试的地址 第二个则是已经找到的 crash 或 stop 地址 如果结果是 crash 或 stop 说明这个地址是一个可用的 ret gadget 如果都是 crash 则说明这个地址是 crash gadget
- 接下来需要寻找 call write 与 pop ret 的代码段
- write(sock, buf, len) 意味着只要试出攻击者的 sock 就可以把二进制代码返回给攻击者 buf 只需要填为比 retaddr 小的一个地址即可
- pop ret 意味着攻击者把数据放到栈上就可以控制寄存器的值 从而提供给 write 函数作为参数
- 奇妙点在于 所有函数的结尾都会有一段 BROP gadget 会把所有的 callee 寄存器的值 pop 出来 并且从这段代码的中间某处开始执行 就会变成 pop rsi 与 rdi 的指令 于是任务变为找到 BROP gadget
- 现在在栈上构造这样一个结构 retaddr 是要尝试的地址 上面跟着 6 个 crash gadget 最顶上是一个 stop gadget 对于一般的代码 会直接 crash 然而对于 BROP gadget 会先 pop 出 6 个地址 然后再执行 stop gadget 因此如果这个地址的结果是 stop 那么其可能是一段 stop 或者是一段 BROP gadget
- 同理 把最顶上的 stop 改为 crash BROP gadget 的结果是 crash 这样就可以区分出 BROP 于 stop 了
- 接下来还剩下 pop rdx 与 call write 的代码段 注意到 call strcmp 与 call write 的位置不会相差太多 并且 call strcmp 会使得 rdx 中的值变为 string 的长度 只需要尝试出字符串的位置即可 并且因为 rdx 是 caller saved 的寄存器 所以 rdx 不会被 pop 掉
- 回忆 ICS 学习的 PLT 表 其结构特点是每 16 个 byte 就是一个 ret 于是通过尝试 ret gadget 是否按 16 byte 对齐就可以找到 PLT 表的地址
- 找到 PLT 表后 我们通过 strcmp 的特征来判断 注意我们已经可以控制前两个参数了 如果两个参数中有一个是 null 那么 strcmp 就会 crash 如果两个参数都不是 null 那么 strcmp 就不会 crash 于是我们可以通过这个特征来判断是否是 strcmp 函数
- 而 write 的特征就是会在响应中返回奇怪的字符串 注意需要通过多个连接来尝试 socket 的值
- 最终可以把整个服务器的二进制代码返回给攻击者 也就可以找到 exec 函数 来执行 bash 命令
Data Flow Protection
- 控制流正确并不能保证数据的安全性 比如代码如果写错了 也会导致安全问题
- 我们不妨从另一个角度思考问题 即不要让数据被泄露 即跟踪数据的流向
- 2 Usages
- 保护关键数据
- 避免可疑数据
Taint Tracking
- 通过染色机制跟踪关键数据的流向
- Dynamic Taint Analysis
- 一个变量被创建时 会根据其是否是常量来决定是否被染色(taint)
- 给一个变量赋值时 采用 OR 操作符来决定是否被染色 比如
a = b + c那么 a_taint = b_taint | c_taint - 在调用 jmp 或 send 等操作时 不允许目标是被染色的
- 上述操作被称为初始化、传播、检查 其中初始化与检查是由用户决定的
- 通过检查 可以找到被泄露的数据 比如 GPS 数据被应用进行发送
- 有一个问题 如果代码采用死逻辑 比如:可以看出等价于
1
2
3
4
5if (a == 1) {
b = 1;
} else if (a == 2) {
b = 2;
} ...b = a但是 b 却会被识别为非染色的
Defending Malicious Input
- 攻击者是如何找到 bug 的?
- 选择一个开源的代码库
- 找到需要攻击的模块
- 定位到 data input
- 跟踪 input data 的流向
- An Example(FFmpeg)
- FFmpeg 是一个开源的视频处理库
- 我们选择 parse 函数来进行攻击 因为这个函数是比较容易出错的
- 还需要选择一个不常用的文件格式来进行攻击 因为用的越多的文件格式就越稳定
- 我们找到了.4xm 文件格式 并且定位到了 parse 函数中读取文件的地方 是
ByteIOContext *pb = s->pb;这一行 - 后续找到了一处给 int 赋值为 unsigned int 的语句 导致了最终可以对内存进行任意位置的任意写入 也就可以进行攻击了
- Taint Check
- 通过染色检查数据是否是危险数据
- 存在性能问题 开销接近 40x 对于大 IO 的程序比较好 因为会留出时间给 CPU 进行操作
LEC 30: Privacy & Review
Secure Channel(建议最后重看)
- 通过加密来保证通信的安全性
- Encryption Properties
- encrypt:可逆 保证了机密性
- MAC:不可逆 保证了完整性 也就是比对哈希值
- 最简单的信息传输就是 A 发送数据的密文以及 MAC 给 B B 再解密得到明文和 MAC 然后比对检验完整性
- Replay attacks:密文被 E 截获后可以不断重发 于是需要加入时间戳或 nonce 来保证消息每次都不一样
- 然而 A B 之间是对称的 因此 E 可以把消息发给 A 于是引入了非对称加密
- 非对称加密是指两端使用不同的密钥进行加密 即 A 使用 ka 加密 使用 kb 解密 B 使用 kb 加密 使用 ka 解密
- A 与 B 最开始的密钥交换可以通过 DH(Diffie-Hellman)算法来实现
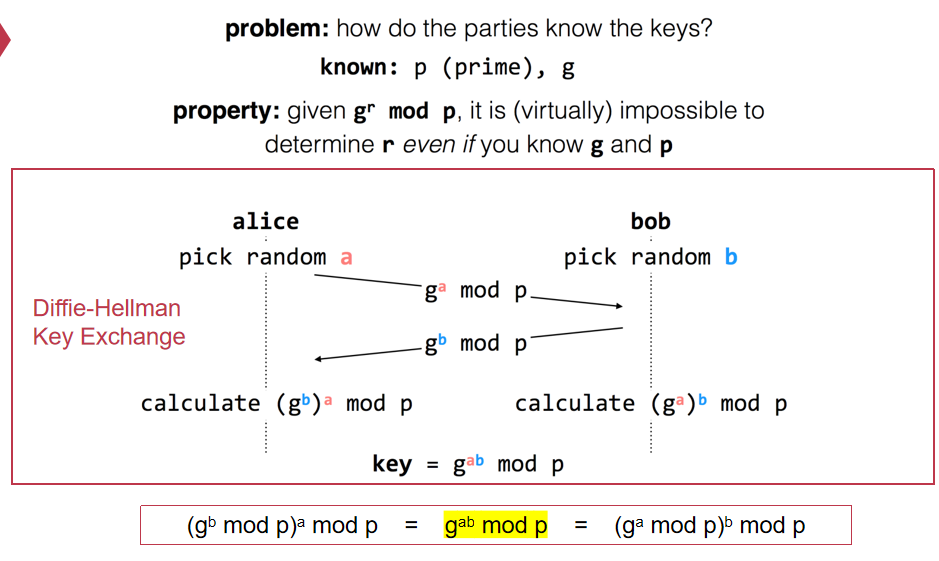
- 虽然 E 无法知道密钥 但是却可以作为中间人来进行攻击 于是引入了数字签名 用于确认消息的发送者到底是谁
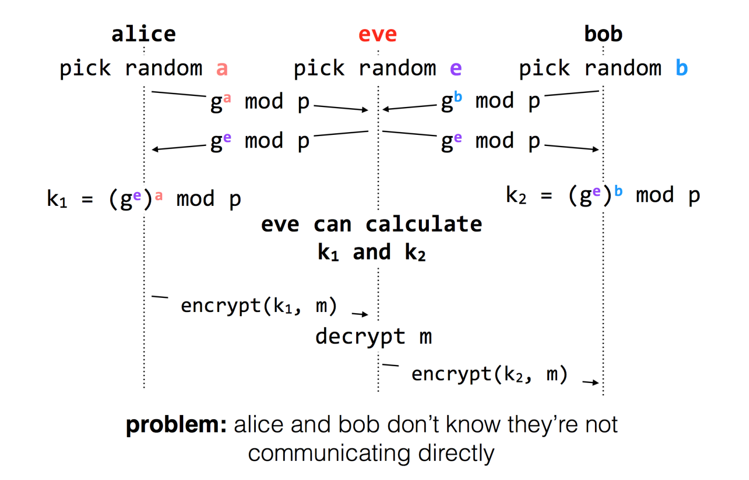
- RSA 是一种非对称加密算法 通过公钥加密 私钥解密 实现了数字签名 即 A 把公钥发布给所有人 B 通过公钥加密消息发给 A 只有 A 通过私钥才能解密 也就保证了 A 是消息的发送者 E 无法再发起中间人攻击 因为要想伪装成 B E 需要 B 的私钥
- 公钥由 CA(Certificate Authority)来签发 维护每个人的公钥
- 为了方便考虑 不可能每次对话都向 CA 去索要公钥 因此 CA 会对公钥进行签名 也就是证书 需要通信时 对方可以把 CA 签发的证书发给你 你可以通过 CA 的公钥来验证证书的真实性 也就确认了对方的身份 CA 的公钥通常存储在浏览器中
Privacy
OT(Oblivious Transfer)
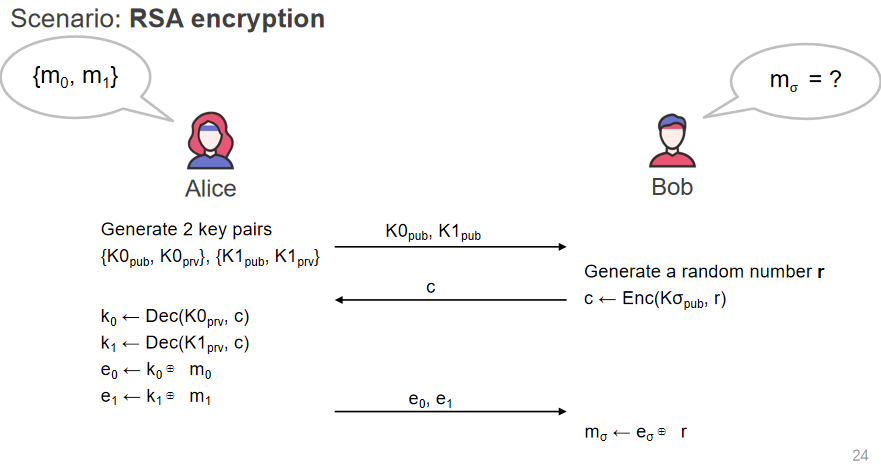
- Problem
- A 有两个消息 m0 与 m1
- B 希望获取 mx 的值 但是不希望 A 知道 x
- A 不能把两个消息都发给 B
- 1-out-of-2 OT 的解决方法很简单
- A 使用两个公钥 K0 与 K1 并把它们发给 B
- B 选择一个随机数 r 如果选择 1 则使用 K1 加密 r 得到 c 返回给 A
- A 用 K0 与 K1 解密 c 得到 r0 与 r1 然后把 e0=r0 xor m0 e1=r1 xor m1 发给 B
- B 只需要用 r xor e1 就可以得到 m1
DP(Differential Privacy)
- Problem
- 一个公司可以发布一部分人的统计收入 但是不能泄露某一个人的收入
- 一旦有一个人通过
SUM(Salary) WHERE Name != "Ben"进行查询 就得到了 Ben 的收入
- Solution
- 通过加入噪声来保护数据 也即返回的是一个约值
- 比如实际上总收入是 450 返回的是
500 除去 Ben 的收入后 返回的还是500
Secret Sharing
- 将密钥分成 n 份发给不同的人 只有当所有人都到齐时才能解密
- 进一步的实现是 n 份密钥中只要 k 份到齐就可以解密 提高了容错性
- Pros & Cons
- 优点:安全性高
- 缺点:通信开销大 因为密钥会大于 1/n
HE(Homomorphic Encryption)
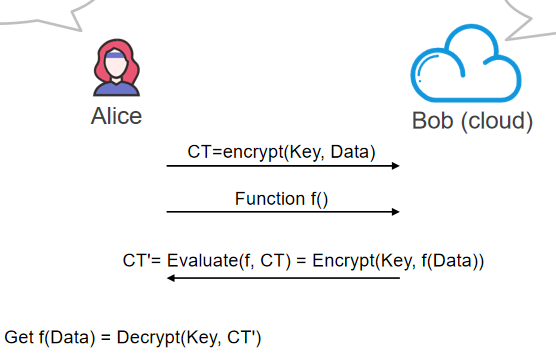
- Problem
- A 想要在谷歌上搜索一个东西 但是不想让谷歌知道他搜索的是什么
- 于是 A 用自己的密钥对搜索的内容进行加密 然后发给谷歌
- 谷歌通过对于密文的搜索来返回结果 A 通过自己的密钥解密得到结果
- 思路
- A 把数据加密为 CT 并把函数 f 发送给 B
- B 对 CT 进行 f 函数计算得到 CT’ 其等价于对于 f(Data)的加密
- 于是 A 可以通过解密 CT’得到 f(Data)
- 换句话说 加密和 f 函数具有交换律
- SWHE & FHE
- HE:如果一个操作 f 可以与加密操作交换 则称为这种加密方式具有 HE
- SWHE:只能进行有限次某些类型的操作 比如加法和乘法同态性 比如 BFV
- FHE:可以进行任意次任意类型的操作 即全同态性
TEE(Trusted Execution Environment)
- 内存是加密的 CPU 的 cache 是明文
- 保证了除非有人可以读取 CPU 的 cache 否则是安全的 实现了一部分的 HE
- 信任的人从云厂商变为了 CPU 厂商
Process of bug report
- 找到一个 bug
- 报告给厂商
- 修复 bug
- 公开 bug 与修复的过程